#236: Fuzzy wuzzy wazzy fuzzy was faster

Watch the live stream:
About the show
Sponsored by Sentry:
- Sign up at pythonbytes.fm/sentry
- And please, when signing up, click Got a promo code? Redeem and enter PYTHONBYTES
Special guest: Anastasiia Tymoshchuk
Brian #1: Using accessible colors, monolens & CMasher
- Tweet by Matthew Feickert, @HEPfeickert
- “I need to give some serious praise to fellow Scikit-HEP dev Hans Dembinski on his excellent monolens tool for interactive simulation of kinds of color blindness. It works really quite well and the fact that is a pipx install away is awesome!
- monolens lets you “view part of your screen in greyscale or simulated colorblindness”
- So simple. Just pops up a box that you can drag around your monitor and view stuff in greyscale.
- Reply tweet by Niko, @NikoSercevic
- “I mean to use cmasher so I know it’s cb friendly”
- CMasher : “Scientific colormaps for making accessible, informative and cmashing plots”
- Provides a collection of scientific colormaps and utility functions to be used by different Python packages and projects, mainly in combination with matplotlib.
- Lots of great colormaps that are color blindness friendly.
- Just specify the CB friendly colormaps with plots, super easy.
# Import CMasher to register colormaps
import cmasher as cmr
# Import packages for plotting
import matplotlib.pyplot as plt
import numpy as np
# Access rainforest colormap through CMasher or MPL
cmap = cmr.rainforest # CMasher
cmap = plt.get_cmap('cmr.rainforest') # MPL
# Generate some data to plot
x = np.random.rand(100)
y = np.random.rand(100)
z = x**2+y**2
# Make scatter plot of data with colormap
plt.scatter(x, y, c=z, cmap=cmap, s=300)
plt.show()
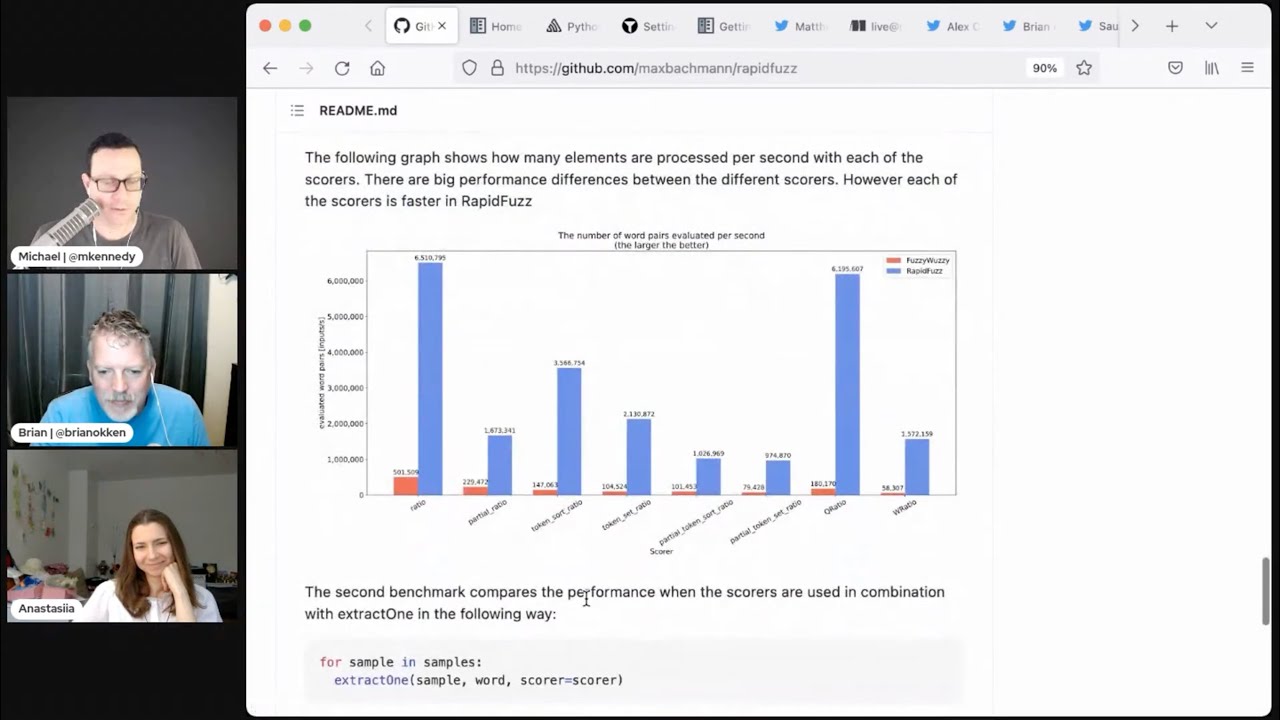
Michael #2: rapidfuzz: Rapid fuzzy string matching in Python and C++
- via Mikael Honkala
- Rapid fuzzy string matching in Python and C++ using the Levenshtein Distance
- “you mention fuzzywuzzy for fuzzy text matching in the last episode, and wanted to mention the rapidfuzz package as a high-performance alternative.”
- “non-rigorous performance testing of several alternatives (including fuzzywuzzy), and rapidfuzz came out on top with a sizable margin.”
- Simple Ratio example:
> fuzz.ratio("this is a test", "this is a test!")
96.55171966552734
Anastasiia #3: Structlog to improve your logs
- One of the best ways to improve logs is to add more structure to them
- Why do we even need to care about logs?
- logs can provide visibility to production, what is actually happening
- logs can help to improve tracing of a bug, especially if logs are machine-readable and easy parseable
- logs can give you a clue why a bug or an exception occurred
- It’s super easy to start with Structlog, also easy to integrate it with ELK stack for further processing
- Features that you will get if switch your logs to use structlog:
- readable structure of logs in key-value pairs
- easy to parse with any post processor to visualise logs and to have more visibility for your code
- you can create custom log levels and separate specific logs with event keys for each log
- I am working with structured logs for a couple of years and recommend everyone to try
Brian #4: xfail now works with pytest-subtests
- Admittedly, there may be few people that care about this, but I’m one of them.
- subtests are a kinda weird feature of unittest that came in with Python 3.4
- They’re really a context manager that you can use within a test function
- pytest started supporting them through a plugin, pytest-subtests, sometime in 2019
- With the plugin, you can use either the unittest style, or a fixture fixture style, without unittest.
- It’s a similar problem/solution that pytest-check solves to allow multiple failures per test case.
- But, like I said, they have some quirks.
- See Paul Ganssle’s Subtests in Python
- T&C 111: Subtests in Python with unittest and pytest
- One quirk is that xfail didn’t work right. It’s discussed in both links above.
- Anyway, it’s fixed now, thanks to maybe-sybr, as of version 0.5.0
- So you can now trust that xfail will work properly with subtest
Michael #5: BaseSettings in Pydantic
- via Denis Roy
- Create a model that inherits from
BaseSettings - The model initialiser will attempt to determine the values of any fields not passed as keyword arguments by reading from the environment.
- This makes it easy to:
- Create a clearly-defined, type-hinted application configuration class
- Automatically read modifications to the configuration from environment variables
- Manually override specific settings in the initialiser where desired (e.g. in unit tests)
- Get values from OS ENV or .env files
- Also has support for secrets files
Anastasiia #6: Take care of the documentation on your team will thank you later
- Sphinx and ReadTheDocs will make life of developers so much easier
- Everyone knows importance of documentation, but how to keep it up to date?
- In my experience, I tried to use Confluence, describe new features in detailed Jira tickets, write some hints in Google docs and sharing them with the team. It does not work, as documentation is getting outdated and piles up drastically
- Benefits of implementing continuous documentation for the code:
- easy to support by writing docstrings, updating them when needed
- easy to find needed information in a centralised documentation
- easy to keep versioning for each new release of the code
- ReadTheDocs if free for open source code
- Sphinx will generate code reference documentation for the code
Extras
Michael
pipxis now part of the PyPA (via Matthew Feickert)- I’ll be “speaking” at Manning’s Developer Productivity conference. It’s free, so feel free to sign up.
- Cloud bills, they do pile up!
- Flake8-FastAPI (via Brian Skinn)
- Want to contribute to Jupyter? Add a localization.
Brian
- pytest uses. Please comment on this thread if you know of some great projects that use pytest, if they converted from something else, or just find it interesting that they use pytest.
Joke
First time recursion

Episode Transcript
Collapse transcript
00:00 Hello and welcome to Python Bytes, where we deliver Python news and headlines directly to
00:04 your earbuds. This is episode 236, recorded June 2nd, 2021. I'm Michael Kennedy.
00:09 And I'm Brian Okken.
00:11 And I'm Anastasia Timosuk.
00:12 Hey, Anastasia. So great to have you here. Nice to have you on the show.
00:17 Thank you for inviting.
00:18 Yeah, absolutely. Why don't you tell people a little bit about yourself before we get into
00:21 the topics?
00:22 So I'm joining from Germany, Berlin remotely right now. And I have a little one, a baby
00:28 doc joining as well. You might hear him on the stream. I am originally from Ukraine. I'm not
00:35 German. I moved to Germany around five years ago, maybe five and a half. And my passion is Python.
00:41 I used to be a C++ developer, game developer, and so many more languages. But the best one,
00:47 I think, for me is Python. So I decided to stick with it for around eight years now.
00:52 Oh, how cool. I started out doing my professional programming in C++. And I
00:57 I know Brian still touches a little bit of C and C++ in his world. So that's cool.
01:01 Yeah, it's half my life.
01:03 Nice. And what kind of games?
01:06 Well, they were adapted first for iPad. They were like two and a half D games. And then later on,
01:15 it was mostly 3D games with Unreal Engine.
01:19 Oh, cool. Yeah, that's awesome. All right. Well, once again, welcome. Welcome. So glad to have you
01:25 here. Brian, do I have the first item this time around? No, you do. Go for it. Okay. What do you got
01:30 for us? Well, accessibility isn't really something I probably should think about accessibility more,
01:36 but I don't really. But I probably should. So I was excited to see there was a tweet recently by Matthew
01:42 Feikert that said, I need to give some serious praise to a fellow scikit hep dev, Hans Deminski,
01:50 on his excellent monolens tool for interactive simulations of color blindness. So I checked this
01:57 out. So monolens is this is a Python package and you can pip install it. And as Matthew said,
02:04 you can pip x install it. So you just always have it around, which is nice. And it just pops up this
02:12 tool, this, this really cool window. And you can just, you just drag it around. And it makes the
02:21 whatever the windows over all over your desktop, it just makes it black and white instead of color.
02:27 So you can see what it looks like in grayscale. So I, one of the things I really liked about this is,
02:34 is the example showing it with, with Matt plotlib and plots, because plots are really where
02:43 you're using color to distinguish between the two different sets of data. So you really kind of want
02:50 that data to look different, even if people don't see color. So that's, that's an important thing.
02:56 So that was neat. And then somebody that replied to that and said, Hey, I always try to use C,
03:03 C masher smasher. I'm not sure. It is a, to make sure they're colorblind friendly. So I'm like,
03:11 I've never heard of this. So I went and checked out smashers. And what it, what it is, is it's a bunch of
03:19 color maps. So you don't really have to think about it. So you, so there's all these great named color
03:25 maps and they're, they're actually fairly attractive color changes, but the, it shows you what they look
03:33 like in black and white also. So they, this isn't, it's kind of a little demo what the top
03:39 that we're looking at on the stream, but the code that you have to, you just, it's just kind of built
03:44 into Matt plotlib already. Like it's an extent, it's also kind of an extension to Matt plotlib and other
03:50 things that use color maps. So you can just say, when you're plotting, you can just specify a color
03:55 map like rainforest or something. And it, it automatically is a colorblind, friendly
04:01 color map. So you can do your plots and have it still look nice everywhere. So.
04:07 Oh yeah. This is really cool. And Matthew friend of the show. Thanks for sending that in. I never
04:13 really thought about this and I should have, you know, I mean, I feel like maybe I should go over my
04:17 websites and go, do they look terrible for people who have, you know, color vision impairments?
04:24 Yeah. So really cool. And it looks like it's this independent thing that will just go over.
04:30 You just move your mouse around. It works on anything. It doesn't necessarily have to do
04:34 with Jupyter or Matt plotlib or something like that. Right. Right. So the model lens is just a,
04:38 it's just something that works on anything. I could, I drug it over even my desktop, my background,
04:43 and it showed, showed the picture in black and white. So, it is cool.
04:48 The other thing is, wait, there's a color maps. I can just add to, Matt plotlib. That's cool.
04:54 Like rainbows and stuff. How neat. I didn't know you could just do that. So that's a,
04:59 that's kind of a neat thing. And then you can like, for instance, the, the, one of the examples
05:03 that they have on the CMASH or read me, is just, just sort of a simple plot. And when
05:09 you're in Matt plotlib kind of just picks colors for you, unless you specify colors for different
05:16 plot lines. but you can just, you can give it a color map instead of a, a specific,
05:22 list for each item. so, and that just kind of nice.
05:27 That's super neat. Yeah. Why not do it? Anastasia, what do you think?
05:31 Oh, it looks amazing really. And it's super helpful.
05:34 Yeah. when you were doing the video games, but that would be great to use it as well.
05:40 For sure. When you were doing games, did you have to think about this kind of stuff?
05:43 No, actually we were not that far at that time. It was around seven years ago, eight.
05:49 Yeah. So, yeah. The, on the, on the monolens site, one of the examples they show is using,
05:56 having one of the plots use some sort of pattern underneath and not just color. And that's,
06:03 that's, I'm not sure how to do that. So people that are great at Matt plotlib probably know how
06:07 to do that really right away. But that's kind of a neat idea also to have like one of the,
06:11 one of the graphs has hashes versus stars or slant lines or something like that.
06:16 Oh yeah. I have it like some sort of ASCII differentiator. Yeah.
06:20 Yeah.
06:20 Very nice. Yeah. This is super helpful. And Matthew again, thanks for sending in and, joy. Yeah.
06:27 Welcome to the live stream. Thanks for, for being here for the recording.
06:30 So the next one I want to talk about is something called rapid fuzz.
06:35 Yeah. So last time I talked, when we had Vincent on, I saw the fuzzy, fuzzy, fuzzy, fuzzy text matching for that, that chat bot that he was showing off. I thought,
06:47 Oh, fuzzy, fuzzy is cool. So Mikel Honkala sent in a rapid fuzz and it's very much like fuzzy,
06:55 fuzzy, but it turns out to be a whole lot faster and it uses some of the same ideas, but, you know,
07:01 coming back to the, some of the things we were talking about, it is basically written in C++ using
07:06 the Levenstein distance algorithm for words similarities, but obviously has a Python
07:12 API that we all work with. And so, yeah, it's pretty neat. It's really easy to work with. You just,
07:18 again, pip install it. And then you can come down here and do things like
07:21 fuzz.ratio and you can give it two sentences. This is a test or this is a test exclamation mark. And it
07:28 says that's 96.5% the same or, you have fuzzy, fuzzy was a bear. I guess these are, yeah. Fuzzy,
07:36 fuzzy was a bear. I guess those are the same. No, was he fuzzy. Oh, was he fuzzy. Yeah. I got it.
07:41 I got to read better. Was he fuzzy was a bear versus fuzzy. Was he was a bear? Oh my goodness.
07:45 that's 90% the same. Given a bunch of, phrases, you can sort them by similarity. You can say,
07:53 kind of use selection, like, you know, to call in sort of call center type of automation,
07:58 given three choices and given some text, you can say, find which one, you know, like Atlanta Falcons,
08:05 New York Jets, New York Giants, and so on. Somebody says, you know, lowercase New York Jets instead of
08:10 uppercase, it'll say, well, here's the likelihood that that's a match, but here's another possible
08:15 match that's, you know, and it gives you the ratios of how good of a match it is. So if you've got a
08:19 select set of choices and you're asking for input on it, you can just say, well, give me the closest
08:24 match. And if it's anywhere close, you can just run with that. So yeah, pretty neat, right?
08:29 That is pretty cool. Yeah. And the other thing that's interesting is the performance. And before
08:36 people tell me that all, all benchmarks are broken and they don't work, you know, sometimes at least
08:40 they give you a sense. So here's some of the things that, they've got in terms of performance,
08:45 save versus fuzzy wuzzy and the numbers are like 10 or 20 times faster. Definitely broken.
08:50 It's definitely broken. I think it's because it's written in C++ instead of Python, at most of
08:56 its core, you know, probably. But anyway, if you're looking for fuzzy text matching, fuzzy wuzzy is a good
09:02 option. And apparently thanks to Mikko rapid fuzz is as well. So yeah, pretty neat. Yeah. We probably
09:08 should do a segment on benchmarks at some point. No, no, no, no, no, we should do it, but I've
09:15 written blog posts and stuff on it. And it's just an endless battle of you're doing it wrong. Your
09:21 situation is not my situation and my situation. It's not as good or it's worse or it's better or
09:26 you're yeah. No, I hear you. It would be interesting, but at the same time. Yeah. Okay.
09:30 There we go. We just had a section on, benchmarks. Yeah. I've already just explained like the emotional
09:35 trauma that I'll go through from receiving all the feedback now. And it's what do you think about
09:40 this, fuzzy text matching? Well, maybe next time we can organize a battle between them.
09:46 That's right. Yeah. We'll bring some in. Yeah, sure. Do you have any use for this fuzzy text
09:51 matching, string matching stuff? Well, actually, yes, at work, we have, lots of, matching
09:57 algorithms, but we're using, different tools and I'm not a data scientist person, but I would love to
10:05 try that actually. It looks super cool. Yeah. We, we use some C++ libraries.
10:09 Yeah. Yeah. Robert out there in the live stream says we would have to benchmark the episode if we had
10:15 an episode about benchmarking. You see, it's like recursion. Save that thought for the end of the
10:20 show, by the way. All right. And Stacia, you're up next. Structured logging. Tell us about it.
10:25 well, a few years ago, I, went to meet up and I heard a talk from my Marcus Holterman about
10:32 struct log. That's the first time when I heard about this and I decided to give it a try. And actually I
10:38 fell in love with it. and I'm using it, since at least two and a half years, maybe two.
10:45 it's awesome way to bring a bit of structure to your logs to make them more visible and more usable because
10:53 usually how we log, it's like just one huge sentence, which is readable by humans, but it's not machine
11:01 readable. And the idea is here, to bring more structure, to build some dashboards based on,
11:09 different keys and then values and then see what's actually happening with the system without
11:15 touching the logs, without scrolling through the whole log. And then just reading all bunch of
11:21 things. and I already used it in production. It looks pretty well. If, you try using JSON format,
11:31 just fantastic. Oh, how cool. Yeah. You can pass it all these like processors and type stuff. So you can
11:37 say render out the print that, you know, stack info, the log level, all those kinds of things. That's neat.
11:45 We added a bunch of, processors like custom made, which were specifically designed for our
11:50 applications, which made a life of our devops parsing the logs way easier because they didn't
11:57 have to write them by hand. And if you use a structured logs for all applications, not just one, but,
12:05 for example, for example, microservices and you pass, the key ID or like trace ID or something
12:12 that will identify the path, which, the log goes through, then you might see what happened before
12:20 the bug happened or maybe because, if you want to see, how the system is working, you also need to be
12:28 either one of the detectives of the system or use the struct log.
12:33 Yeah. It's interesting when you log out stuff, it looks like you can just do key keyword arguments and
12:40 those will add to the log really nicely. So you don't have to create a message that you're going to send
12:46 that embeds, you know, the value equal, you know, variable equals valuable, very equals value. You just pass
12:52 them to the log message and they become part of the message like that. That's cool.
12:56 Yeah. And you can also use, the initial message, which is an event like greeted here,
13:01 as some kind of key, which would give more clues where this message is coming from and what type of
13:08 event happened instead of a usual message. Yeah. Nice. Very cool. The other thing it says is if you have
13:15 Colorama installed, it will automatically render in nice colors and that's very neat. I love Colorama and I love
13:22 having colors in, in the code that we look at, it really makes a nice difference. So yeah, you get things
13:28 like the colored, whether it's an info message or an error and whatnot. Yeah. Very neat. I like it.
13:35 I keep meaning to use this more and I know I'm glad you brought it up because I definitely want to try this.
13:41 Definitely try this. Yeah. Yeah. This is a really good one. This is new to me, but, quite neat.
13:46 All right. Not new to me, but also quite neat is our sponsor for this episode. So this episode is
13:52 brought to you by Sentry. So how would you like to remove a little stress from your life? Do you
13:57 worry that users may be having difficulties and encountering errors with your app right now?
14:02 Would you even know until they send that support email? I mean, yes, maybe using struck log,
14:05 but are you watching the struck log now? You don't know, right? So how much would it,
14:09 how much better would it be if you had that error or performance details immediately sent to you
14:14 with the call stack and local variables and active user and all that stuff. And with Sentry,
14:19 it's not just possible. It's easy. We use Sentry on all of our web apps, Python by set up M talk,
14:24 Python training, all those kinds of things. And we know if there's some kind of problem.
14:28 It's unfortunate if someone hits a problem, but it's better to know and be able to fix it right away.
14:31 In fact, one time somebody ran into a problem over at Talk Python Training, getting a course and
14:37 got the message. I could see who was logged in when they had the problem. And I actually fixed the bug
14:42 and was about to push out the changes. And I got an email. Hey, I'm having a problem with your,
14:46 your site. I'm like, yeah, I know. I just fixed it. Try again, please. And they were quite a surprise.
14:51 So surprise and delight your users today. Create your Sentry account at Python by set up M slash
14:55 Sentry. And please, when you're signing up, click the got a promo code redeem option and enter Python
15:01 bytes. It's not automatic. And they'll make sure that you enter Python bytes as the promo code.
15:06 Otherwise they won't know us from us. You'll get a bunch of cool stuff, two,
15:08 three months of the team plan with many more errors and events and other features as well.
15:12 So check them out at Python bytes set up M slash Sentry. That's pretty awesome.
15:16 Brian, I guess you should probably also test your code maybe before you end up with errors. What do
15:22 you think? Definitely. And actually, before we go on, I think I've mentioned this before,
15:26 but the graphic on that is on the Sentry page is so cool.
15:29 I know. I really like it too. Like, I love the upset console terminal reading a paper.
15:35 Yeah. So this is, this is kind of like inside baseball, maybe, but I don't know, maybe three
15:42 people might care about this. But anyway, I'm one of them. So X fail now works with by test subtests.
15:50 So that's, it's neat. But I got to explain it a little bit. So subtests are kind of this weird
15:57 feature of unit tests that came along in Python three, four, and it's a way it's a context manager
16:03 so that you can have possibly several places where your test might fail, but continue. It doesn't stop
16:11 if it fails. And that's a, that was within unit test. pytest had, well, pytest said pytest check,
16:18 the plugin that I wrote that allows something similar context manager. But then pytest subtests
16:25 came out, which was a plugin in about 2019 that started that, that allowed you to run the unit test
16:33 subtests within from pytest. But there's also a pytest style of doing subtests also.
16:40 They're a bit quirky. So I'm going to, we, I'm linking to, to two resources, an article by Paul
16:48 Gansel and an episode of testing code where he and I talked about subtests. And so they're a little,
16:55 before you jump in and use them right away, you should know some of the quirks about it,
16:58 but they're still cool if they work for you. But one of the quirks that was around for a long time
17:03 was that X fail didn't work. And X fails a way to say, I know my test is going to fail.
17:09 but you know, and then you get to decide whether or not you want to make market as an
17:14 X pass or market as a fail, if it, if it fails. and the, this, anyway, X fail didn't work
17:22 with subtests, but it does now as of like the start of the month. So somebody named maybe Sibber on,
17:29 GitHub, maybe, merged a fix or submitted a fix as a pull request and it got merged and it's
17:37 now in version 0 5 0. So X fail, if you wanted to use subtests, X fail now works with them. So that's
17:44 the good news. Yeah. Yeah. This looks really interesting. So the basic idea is I want to loop
17:49 over a bunch of scenarios or whatever, and maybe test them all and then have the test fail if any of them
17:54 did, but actually just go through them all before. Yeah. So like in, on the, on the subtests,
18:01 site, there's a little example. So like, let's say you're looping through a range and you want to,
18:05 you want to run all of them within, not, not a parameterized, just within the test,
18:09 you're doing like several things and you can, yeah. And if something fails, you want to actually
18:15 report all of the failures. and this is, this is, you know, sort of helpful with loops, but you
18:21 know, why not just use parameterization? but the one part where it does really help is if
18:27 you really are checking like four or five different things and you really want to know, like, let's say
18:33 you're measuring something or you're checking, several dimensions of something and, and
18:39 having all of the failures together would help you determine what the real problem is. So, so it's,
18:46 it's, it's when you have to have all the information, this is a good idea.
18:49 Very cool. Anastasia, what's the testing story in your world?
18:53 Well, we use mostly parameterized testing because we don't have the subtest need. We don't need to
19:00 test it multiple times, maybe in the future. Yeah.
19:03 Yeah. parameterized works. I'd stick with it. So yeah, it's definitely good. All right. Another
19:10 thing that I think is really neat to talk about, but I feel like it's almost down to the benchmark type
19:17 of situation is what do you do with the secrets in your application? There's to get,
19:23 ssh get, which is always terrifying. If you go here, you can see, oh, here's all the code that
19:31 we found in this branch of this GitHub repository. For example, here's your, you know, database
19:36 connection string with username and password right there. Right. So you can see all kinds of issues.
19:42 If you go over here, like even a live stream, if it doesn't feel bad enough, you like watch the live
19:46 stream of all the things that are coming in. Like right now, apparently there's some username and
19:51 password in a URI and some kind of private key and whatnot. So you don't want that. So what do you
19:56 do? Well, there's all kinds of things you can do. Do you encrypt those secrets and put them in source
20:02 code? Well, then where do you store the encryption key? There's some kind of certain types of vaults
20:07 you can install on your server, kind of like one password, but for servers, you could do that kind of
20:12 thing. There's just leave it in there and hoping for the best. There's putting it in environment
20:19 variables. That's a very, very common one. Right. But still, no matter what you pick, you kind of got to
20:24 get that data back and deal with it. So I want to introduce you to Pydantic. Brian, you've heard of
20:30 Pydantic, right? Yeah. In fact, I didn't know this had anything to do with secrets. Yeah. If you go to
20:37 Pydantic right here at the top, I believe there might be some nice little comment here. Oh, yeah. I thought,
20:45 I thought you were in here, apparently I'm in here right now. I think it toggles between us. Anyway.
20:49 Yeah. So we've known, the point is we really talked about Pydantic a lot. It's a really cool way to
20:55 create these classes that are kind of like data classes, point them at some data source, and then
21:00 they validate it and adapt it. Right. So if I've got like a JSON document and it has a field in it,
21:05 and that field is a list of something I could say in my model, this thing has a list of integers.
21:10 And if it happens to be quote a string or a number that has quotes on it, it'll just, you know,
21:16 automatically do the int pars type of thing to get it fixed. Or it'll tell us that it couldn't figure
21:21 out what to do with the third value, something like that. It's really fantastic. But what I also didn't
21:26 know was that it has a built in support for working with these user secrets. So Dennis Roy pointed this
21:32 out to me. And there's all kinds of things. You can have the .env file. You can have Docker secrets.
21:39 You can have environment variables. And all of these things has your secrets. And if you just derive from,
21:46 instead of base model, you derive from base settings, then this will automatically determine
21:51 any of the fields that are not passed to it from the environment or from .env files. What do you think?
21:58 Well, that's cool. Where do the .env files go?
22:01 Not in GitHub.
22:02 Okay.
22:04 You know, you store them somewhere else, right? You probably, what ideally I think you do is you
22:10 would store like an .env template file that has, you know, put this value and then the real value here,
22:16 this value and the real value there. And then you, of course, ignore, .gitignore the other one,
22:20 the real one, right? So you at least have a structure. But so the idea is you come down here and say,
22:24 I've got these settings and we've got like an API key and off key. We've got a Redis connection,
22:31 all those kinds of things. And you can even say, I'm going to put a prefix on it. So in your environment
22:38 variables is fine if you've got one app in one server, but if you've got 10 apps running or 10 APIs
22:45 running on your server, what is the API key referred to? What is the database connection string with the
22:50 database name in it referred to? Which one of those 10 apps, right? So you can put a prefix. So you
22:55 could have like login app API key or, you know, login app API key. And you put that in there and it
23:03 automatically will just let you access it as if it's API key. So you can sort of configure in the
23:08 environment a little bit better. There's just lots of really neat things that you can do in here to make
23:12 that work. you can say whether it's case sensitive, let's see, let me pull up, I had to take notes,
23:18 some other things that were super cool. So it's a regular Pydantic model, which means it'll do all
23:24 the conversions and the validation. So if something is missing that's required from your environment,
23:28 it'll let you know exactly what's missing. It'll do those conversions. yeah, all sorts of stuff.
23:34 It has support for raw sequence files as well, which is like a slightly different way to do it.
23:40 You can have differently named ENV files, like a prod dot ENV versus U and a D dot ENV or whatever, all sorts of settings. So I've always thought Pydantic is amazing
23:52 and I had no idea it had this built in support for working with this. The other thing that's really
23:57 cool about this is if you go back to the top where it describes it, it says it will try to get these
24:02 values from the environment if you don't pass them over. So if you're in say a testing environment,
24:08 you want to actually pass values that would control it, you could just explicitly pass them along
24:13 instead of, you know, having them come from the environment. So it's really easy to test,
24:16 you know, set the test values instead of trying to configure a test environment.
24:20 Nice. We do use it by the way, base settings, but we didn't use prefixes. Yes. Yeah. Which is a good idea.
24:27 Yeah. The prefixes are cool. If you have a bunch of apps, if you just have one,
24:31 yeah, it doesn't really matter. Right. Yeah. Yeah. Of course. Cool. You like this? It's working well for
24:35 you? Yeah, it's working perfectly well. And we are committing on the development version with some dummy
24:41 keys just to have them around. Of course. Of course. Oh, wow. How neat. Okay. Well, cool. Well,
24:46 that's neat that you're using it. Brian, you got the next one. Is that right? You've already done it.
24:51 No, but I just wanted to mention the, oh, wait. Nevermind. I had the wrong thing. Oh, here we go.
24:59 Yeah. The quote I think you were looking for was from FastAPI. Oh, yes. Yes. Of course. Of course.
25:06 Yeah. It is. I'm over the moon. Yeah. Super excited about it. Yeah. FastAPI. Thanks.
25:12 Yeah. We use it. I love FastAPI as well. And to me, like Pydantic and FastAPI,
25:17 they go together because I learned about them at the same time. I know there are different people
25:21 and different projects, but you know. It works like magic. Yeah. Yeah. Absolutely. It really is. Yeah.
25:26 And if it's not magic, maybe you should document it. Or maybe it is magic. You should document it.
25:31 Definitely. Definitely. Actually, I'm the one who is usually bringing this topic
25:38 to the team, how to write documentation. And first, the question is why to write documentation?
25:44 Everyone knows that we need documentation, but it's hard. It's time consuming. It's annoying. And
25:51 how it usually happens. Someone leaves the team. And then the last days are about handing over
25:58 everything. And... Oh my gosh. I remember I've had this experience twice at least.
26:03 Right? Where it's like, oh, you said, where you said you're going to, you've given me your two weeks.
26:09 So your next two weeks, your two weeks notice that you're going to leave. Your next two weeks will be to
26:13 start writing documentation for everything you've ever worked on and anything that people might need
26:18 to do. So your next two weeks are to begin writing documentation that you should have been doing the
26:22 whole time. In Germany, we have notice period of three months. So like it's three months.
26:27 Oh, that's a lot of documentation writing.
26:28 Yeah.
26:31 Just kidding. But normally, even if you leave the team, like you, for example, move from one team to
26:36 another, you don't, it doesn't mean that you have to leave the company. Still, you have to hand over
26:41 everything that you worked for, let's say, in a year or even half of the year. And for example,
26:49 in my experience, when I started with Python, I didn't know any Python. I had to learn it. And of course,
26:54 I didn't know about Sphinx or Read the Docs or any kind of documentation for Python. And what did I do?
26:59 Nothing. I didn't write it. And half a year later, I was wondering who wrote this code. So I did get
27:06 blame. And of course, it was me. And I was like, what a stupid person. So yeah. And I suggest to start
27:14 writing documentation now, even if you're not leaving the team. The reason why I'm bringing up the Sphinx
27:21 and Read the Docs is that it will allow to have continuous documentation. And with Sphinx,
27:28 you can easily write just some doc screens, which will explain what the function does, what the
27:35 class is doing, add some input output parameters, and then you will automatically generate it. So
27:42 there's no need to write it somewhere on Confluence or any other source. Because if there are too many
27:50 sources, that's where the documentation will die, because no one will go and check it. And
27:55 during the handover, usually it happens like that you write documentation somewhere where nobody knows
27:59 where, and nobody reads it.
28:01 Yeah, you pointed out that you've got it in Jira, and you've got it in GitHub, and you've got it in all
28:06 different places.
28:07 Google Docs, yes.
28:08 Yeah. Especially Google Docs.
28:10 Oh, yes.
28:12 And then you share like 10 Google Docs with different people, and then they lose the links, and people
28:19 are leaving. It's nice when people are leaving the team, but it's not nice to the people who are leaving
28:24 the team to another team, because they are getting all the questions for a year.
28:28 Where to find those? How can I get this function? How to get this data?
28:35 Yeah. Yeah. Very good advice. You know, for a long time, Sphinx was like synonymous with restructured
28:42 text, but now we've also got the Markdown with the missed parser there. So that's very cool as well.
28:48 I'm a fan of Markdown instead, yeah.
28:50 And also it supports the Sphinx itself. It supports different types of documentation. For example, you can
28:58 write code reference, then you can go through all the code, and then you can also write extra
29:04 documentation, like Markdown. Even ReadMe can be included into documentation. And you can also style it.
29:09 Oh, nice. Yeah. Yeah, very cool.
29:12 Yeah, there's lots of great themes to it too now. It really looks attractive.
29:15 Yeah, you did recently cover that, right, Brian, the Sphinx themes?
29:18 Yeah. And actually, when the Markdown, the support came on, that's when I went back and started looking
29:26 at Sphinx. So some of our documentation is done in Sphinx now because it does Markdown. And you can even
29:34 make it do, it's not built in, but you can make it read doc strings and interpret doc strings as Markdown.
29:41 So it's cool.
29:42 Yeah. Very cool. Very cool. Robert out in the live stream has an interesting addition to continuous
29:47 integration and continuous delivery. So can we deploy yet? Only if the documentation is complete.
29:53 Definitely.
29:53 Very cool. All right. Well, that's it for our main topics. Brian, you got anything you want to share?
30:00 Any extra stuff you want to throw out there?
30:02 Mostly, I'm curious about pytest uses. So I'll drop a link in the show notes,
30:08 but basically I've got a pinned tweet on my Twitter, and I'd like to have people tell me where they see
30:15 where they're using pytest. So I've got some examples. And then I kind of went,
30:24 I, my first question was people projects that have switched. But I was looking at just the,
30:30 just the guts of how Python works. And there's some amazing projects that use pytest,
30:35 like wheel, tip, setup tools, warehouse. Those all use pytest. That's pretty cool.
30:40 Wow. How interesting. Yeah. And those are sort of almost inside of Python, which is interesting
30:45 because they're not using unit tests, right?
30:47 Yeah. So, and then I just learned about recently, even if it's proprietary, that'd be interesting. I just
30:52 learned that Stripe and Lyft went through a pytest conversion recently. So that's kind of neat.
30:57 Yeah. That's cool. Yeah. Yeah. Very cool. Anastasia, anything else you want to throw out
31:00 there or let people know about while we're here?
31:02 Yeah. Maybe using exceptions. Don't use space exception.
31:08 Yeah. I agree. Custom exceptions.
31:10 Custom ones that like a four-year app or have certain, absolutely. I definitely second that idea.
31:14 All right. This, Brian, this was in danger of almost being an extra, extra, extra,
31:19 extra, extra hero about it. So I'll just go quick. So Matthew Feikert's getting a couple of shout
31:25 outs on the show. So he also pointed out that, whoa, super cool. PipX, which we've talked about
31:31 on the show before, it lets you install Python tools, kind of like Homebrew or Apt. They're not
31:35 part of a project, but you want to have them managed and installed in their own isolated environment. So
31:40 you pipX instead of pip install the thing, which is great. That is now officially part of PyPA,
31:44 the Python Packaging Authority. Nice.
31:47 So yeah, pretty cool. So pipX is now sort of officially part of Python, not Python, the distribution,
31:53 but the group, you know. Next, I will be presenting-ish. It's recorded, but then there's like a live Q&A
32:00 afterwards. Manning is having a conference on developer productivity. I don't honestly remember
32:06 what my top talk is going to be about. Oh yes, here it is. It's 10 tips and tools you can adopt
32:11 in 15 minutes or less to level up your developer productivity. So I'm going to be speaking on that.
32:15 All sorts of fun things. So if you want to check that out, it's free to register for. It's
32:20 later this month, I guess. Here's just a thought I would throw out there for you. I don't expect an
32:25 answer, but yikes, cloud bills can pile up. Alex Chan, who is teaching, I guess I don't,
32:32 I could figure out exactly the context of this, but put out a tweet that said,
32:37 I have a panicked student in my DMs who accidentally racked up an $8,000 AWS bill.
32:43 My suggestion of talk to support is no good. Apparently they won't issue a billing adjustment.
32:48 Anyone got ideas out there?
32:50 Oh no.
32:50 Could you imagine as a student, I mean, as a professional, it's still a lot of money, but as a student, $8,000 is like a ton of money.
32:59 Yeah. It's like a term of bills. It depends on.
33:03 Yes, exactly. Yeah. Like a semester of studies or something. So, maybe other students and
33:09 basically all people out there put up billing alerts on, on whatever cloud thing you're doing,
33:14 on whatever, whatever places I have, including AWS, I get periodically, I get an announcements like
33:21 you, your bill is now at $50. Your bill is at a hundred dollars.
33:24 Your bill is now at $500. Your bill is now at a thousand dollars. And if it goes beyond that,
33:28 I'm going to have to start paying a lot of attention to what's going on with my AWS account. So just,
33:32 you know, put these alerts on there. It's usually easy with whatever platform you're on. anyway,
33:37 don't be that poor student. All right. What's next? Brian skin, shout it out. Hey, this might not
33:44 be a total new item, but maybe we can mention it. Maybe it's interesting. Developed a flare mentioned,
33:49 a flake. It didn't develop it. I don't believe a flake eight plugin for FastAPI. So if you're doing
33:56 FastAPI, there's different ways to do things like routes and whatnot. And there's like the natural way,
34:01 there's sort of a clumsy way. And so here's a flake eight thing to make sure you're using FastAPI.
34:06 Nice. Interesting. Yep. And I think, yeah, and I think this is my last one. It is my last one here.
34:13 So Sal Shannon Brook tweeted JupyterLab three will have localization. So localization means like the
34:21 menus and the help text and the button hover tips and all that kind of stuff are localized for different
34:27 languages. So JupyterLab three will have localization making it more approachable for
34:32 people who don't want to work in an English UI and their crowdsourcing translations. So if you wanted
34:40 to contribute to Jupyter and you were good at programming and in a language that's not English,
34:44 but it's already done in English, you know, go check that out. That would be kind of cool.
34:48 What if anybody just messes with people and like does wrong translations just for fun?
34:53 I'm so afraid of that. Yeah. I think they do.
34:55 I bet they do. I bet they do. And maybe not really obvious, maybe in real subtle ways.
35:01 Yeah. Yeah. Yeah. Nevermind. Don't, don't, don't, don't have any ideas.
35:05 Brian, don't give people ideas. This is not, that's a good one.
35:08 All right. Well, that's all the extras as well. So how about a joke?
35:14 Yeah. Okay. So imagine you're learning programming, you're learning Python, take one of these computer
35:20 science courses where they talk about weird things like recursion. So cursion is the idea that the
35:26 function calls itself with different parameters, right? Like a really common example would be
35:31 factorial. So if I'm going to calculate a factorial, it's just N times N minus one times N minus two.
35:36 So that's just N times factorial of the smaller number. You can just like work your way back.
35:42 Right. But there should be an exit condition. Like if N equals one return, don't keep recursing.
35:48 So here's a nice little graphic under the banner of only programmers would understand. And it's got
35:54 the four squares. It's kind of like screen sharing. We got that infinite view. So learn to program
35:59 in one corner, next corner, make recursive function, third corner, no exit condition. And then it just
36:04 repeats and repeats and repeats down to smaller and smaller and smaller. I love it.
36:07 This is bad. No, this is good. That's how you learn.
36:12 That's right. No. Yeah, exactly. It's like when you share your screen in zoom or, or maybe Google
36:20 meet, but you've still got the window up or something like that. But it's about recursion. It's beautiful.
36:24 And then you silence basic exceptions and you cannot exit the program.
36:27 Yeah.
36:29 Do you know if, yeah, you know, if Python has a tail recursion optimization,
36:34 sorry.
36:35 I'm thinking, I'm thinking no, like, so the whole point is here, Brian, that we would run out of
36:40 a call stack space really quickly. And that's usually the error stack overflow error. If you
36:44 recurse too deep type of thing. Yeah.
36:46 But with trail recursion, it basically becomes an infinite loop. So you run out of time instead
36:50 of memory. Okay.
36:51 So, but I don't, so that would be the advantage of tail recursion. I have no idea if it is there or not.
36:56 Yeah. I mean, there's some languages that do the optimization, so they don't, they don't
37:00 generate a new call stack because there's nothing to save. So yeah.
37:05 Yeah.
37:05 Anyway.
37:05 Yeah. I don't know. I'm sure we will find out before next week.
37:09 Yeah. One of the reasons why I like asking open-ended questions on the podcast.
37:13 So yeah, that's awesome. Yep.
37:16 Well, Brian, thank you as always. And Anastasia, thank you for being here. It was great to have
37:19 you as a guest.
37:20 Thanks.
37:20 Thank you for inviting. Thank you.
37:22 Yep. Bye.



