#259: That argument is a little late-bound
Watch the live stream:
About the show
Sponsored by Shortcut - Get started at shortcut.com/pythonbytes
Special guest: Renee Teate
Michael #1: pypi-changes
- via Brian Skinn, created by Bernát Gábor
- Visually show you which dependencies in an environment are out of date.
- See the age of everything you depend upon.
- Also, shoutout again to pipdeptree
Brian #2: Late-bound argument defaults for Python
- Default values for arguments to functions are evaluated at function definition time.
- If a value is a short expression that uses a variable, that variable is in the scope of the function definition.
- The expression cannot use other arguments.
- Example of what you cannot do:
def foo(a, b = None, c = len(a)): ... - There’s a proposal by Chris Angelico to add a
=:operator for late default evaluation.- syntax still up in the air.
=>and?=also discussed
- syntax still up in the air.
- However, it’s non-trivial to add syntax to an established language, and this article notes:
- At first blush, Angelico's idea to fix this "wart" in Python seems fairly straightforward, but the discussion has shown that there are multiple facets to consider. It is not quite as simple as "let's add a way to evaluate default arguments when the function is called"—likely how it was seen at the outset. That is often the case when looking at new features for an established language like Python; there is a huge body of code that needs to stay working, but there are also, sometimes conflicting, aspirations for features that could be added. It is a tricky balancing act.
Renee #3: pandas.read_sql
- Since I wrote my book SQL for Data Scientists, I’ve gotten several questions about how I use SQL in my python scripts. It’s really simple:
- You can save your SQL as a text file and then import the dataset into a pandas dataframe to do the rest of my data cleaning, feature engineering, etc.
- Pandas has a built-in way to use SQL as a data source.
- You set up a connection to your database using another package like SQL Alchemy, then send the SQL string and the connection to the pandas.read_sql function.
- It returns a dataframe with the results of your query.
Michael #4: pyjion
- by Anthony Shaw
- Pyjion is a JIT for Python based upon CoreCLR
- Check out live.trypyjion.com to see it in action.
- Requires Python 3.10, .NET Core 6
- Enable with just a couple of lines:
>>> import pyjion >>> pyjion.enable()
Brian #5: Tips for debugging with print()
- Adam Johnson
- 7 tips altogether, but I’ll highlight a few I loved reading about
- Debug variables with f-strings and
=print(f``"``{myvar=}``")- Saves typing over
print(f``"``myvar={myvar}") with the same result
- Make output “pop” with emoji (Brilliant!)
print("👉 spam()")- Here’s some cool ones to use
- 👉 ❌ ✅
- Use
rich.printorpprintfor pretty printing- Also, cool rename example to have both print and rich.print available
from rich import print as rprint
- Both
rich.printandpprint.pprintare essential for printing structures nicely
- Also, cool rename example to have both print and rich.print available
- Brian’s addition
- In pytest, failed tests report the stdout contents by default from the test
- I love the idea of using
rich.printand emoji for print statements in tests themselves. - Even though you can use
--showlocalsto print local variables for failed tests, having control of some output to help you debug something if it ever fails is a good thing.
Renee #6: SHAP (and beeswarm plot)
- Brought to my attention by my team member Brian Richards at HelioCampus, and now they’re becoming a standard part of some of our model evaluation/explanation outputs
- SHapley Additive exPlanations
- Shapley values from game theory
- Additive: “SHAP values of all the input features will always sum up to the difference between baseline (expected) model output and the current model output for the prediction being explained”
- Negative/positive - pushing the prediction towards one class or the other
- There’s a SHAP value for every feature for every prediction
- Waterfall plots
- Scatterplots of input value vs SHAP value
- SHAP value can be outputted and pulled into other tools (I use them in Tableau)
- Negative/positive - pushing the prediction towards one class or the other
- Correlation not causation
- Beeswarm plots for feature importance with input value vs SHAP value
Extras
Brian:
- Matthew Feickert recommended
pip indexand specificallypip index versionsas a cool thing to try.- Example.
pip index versions pyhfreports- all versions of
pyhfavailable on pypi - the latest version
- your installed version
- all versions of
- It’s currently “experimental” so conceptually the pypa could yank it. But we like it. I hope it stays.
- Example.
Michael:
Renee:
- My book and companion website with interactive query editor: SQL for Data Scientists
Joke: git messages
Episode Transcript
Collapse transcript
00:00 Hello and welcome to Python Bytes, where we deliver Python news and headlines directly to your earbuds.
00:05 This is episode 259, recorded November 17th, 2021.
00:10 And I'm Brian Okken.
00:11 I'm Michael Kennedy.
00:12 And I'm Renee Teet.
00:13 Well, thanks, Renee, for joining us today.
00:15 Can you tell us a little bit about who you are?
00:17 I'm the director of data science at Helio Campus.
00:20 And a lot of people know me as Data Science Renee or Becoming Data Sci on Twitter.
00:26 So that's where a lot of people follow me.
00:29 And then I started with, I had a podcast that's not actively recording, but it's called Becoming a Data Scientist Podcast.
00:35 So some people listening probably know me from that as well.
00:39 Cool.
00:40 Yeah, awesome.
00:41 You were doing a bunch of cool stuff there.
00:42 And any chances of maybe going back to podcasting?
00:45 It's definitely still open.
00:47 I've always told myself this is a pause, not a stop.
00:50 It's just an extended pause.
00:51 So yes, hopefully I will get back to it.
00:53 It's hard to keep going, isn't it?
00:54 I mean, life gets in the way and then you get busy.
00:58 I'm always so impressed with those of you that have hundreds of episodes very consistently recorded.
01:02 Well, Brian makes me show up every week.
01:05 So yeah, it definitely helps having a partner so that you can coerce each other in.
01:09 That's right.
01:10 Well, Michael, speaking of partners, want to tell us about something?
01:14 Let's talk about some changes.
01:16 Some PyPI changes.
01:17 These come to us from Brian Skin.
01:19 Thank you, Brian, for shooting this over.
01:22 And it's a project by Bernay Gabor here.
01:26 And if we pull this up, it says, have you ever wondered when did your Python packages, the packages in your environment that you have active or any given environment, how old are they?
01:36 When were they last updated?
01:38 Is there a version of them that's out of date?
01:40 So I've been solving this by just forcing them to update using pip compile and the pip-tools stuff to just regenerate and reinstall the requirements files.
01:51 But this is a way to just ask the question, hey, what's the status?
01:55 And it wouldn't be an episode if we didn't somehow feature Will McGugan.
02:00 So this is based on Rich, of course.
02:03 So let's go check this thing out.
02:05 So over here, if we go to the homepage, we get, as all projects should, a nice animation here.
02:11 And if you look at it, you can just see type IPI dash changes and you specify the path to a Python in a virtual environment.
02:18 So in this example, it's like PyPI changes, VNV slash bin slash Python.
02:23 It does some thinking on the internet, caches some information about the packages.
02:27 And it says, all right, you've got all these things installed.
02:30 They're this version.
02:31 Some of it will just say this was updated 10 months ago or a year and three days ago.
02:35 Others, it'll say it was updated a year ago, but only six months on the latest version.
02:41 It says remote such and such.
02:42 That's the one you could install if you were to update it.
02:44 So it's a real nice way to see, well, which ones are here that could be updated or even also sometimes it's interesting to know like, oh, this library, it doesn't have an update, but it's 10 years old.
02:55 Maybe I should consider switching to a library that's a little more maintained and making progress.
03:01 Right.
03:01 What do you all think?
03:02 That's handy.
03:03 Cool, right?
03:04 It is pretty neat.
03:05 So, yeah, I've been playing with this today, installed it, checked it out, even pointed out that, you know, since yesterday, some things changed in one of my projects that I want to keep up to date.
03:13 So I updated it.
03:14 Yeah.
03:15 So I like it.
03:16 It's got a nice command line interface.
03:18 You basically specify the Python that is in the environment that you want to check.
03:24 That could either be the main Python or a environmental virtual environment Python.
03:28 Like I said, you can control the caching because the first time it runs, it has to go get lots of information about each package that's installed and it's faster the second time.
03:36 It also has some cool parallelism.
03:38 So you can say number of jobs like --jobs.
03:41 And by default, it runs 10 downloads in parallel as it's pulling this information in.
03:46 But I guess you could go crazy there.
03:48 So anyway, I thought this was pretty cool.
03:50 It's a nice little thing to have.
03:52 So I pipx installed this.
03:54 It's perfect for pipx because it doesn't need to be in the project.
03:58 It's testing.
03:59 It just needs to be on your machine as a command.
04:02 And then you point it at the environment, different environments, and it gives you reports on those environments.
04:06 Yeah, I love pipx too.
04:08 One of the things I want to note, just as I know a lot of package maintainers, having, I mean, it's worth checking things out if it's a really old packet, if it hasn't been updated for a long time.
04:19 But some things are pure Python things that just do a little tiny thing and don't need updated very often.
04:25 So it's not necessarily a bad thing that it's not updated, but it's an indicator.
04:30 It's an indicator.
04:31 Yeah.
04:31 Of something.
04:32 Yes, exactly.
04:33 Let's see.
04:34 Out in the live audience, Anthony Listerhate says, can the changes be exported to a text file?
04:39 I haven't seen anything about that other than just, you know, piping it into a text file.
04:43 And who knows what happens with all the color in there, but perhaps.
04:47 Yeah.
04:48 Renee, what do you do to manage your dependencies and all those kinds of things?
04:52 Well, at work, we started using Docker for that.
04:55 So we have a centralized Docker container that everyone on my team uses, and we make sure we have the same setup in there.
05:02 So I'm not the one that directly manages it, but that's the solution that we've gone towards to make sure we're all on the same page.
05:10 Oh, interesting.
05:10 So you've got the Docker environment that has some version of Python set up with all the libraries you need pre-installed, and then you just use that to run, and that way you know it's the same.
05:19 Yep. And then it's also nice because when we kind of move some of our projects into production, we can include that Docker container with it.
05:26 So it will have whatever version it had at the time.
05:28 So if for some reason it's not compatible with some later version we upgraded to, it still lives out there with the version of the tools that it had until we have a chance to update everything.
05:38 One of the challenges that people have sometimes is they say, even though you've got some kind of version management, iProject.toml or requirements.txt or whatever, that doesn't necessarily mean that people actually install them the latest.
05:50 So you could still be out of sync, right?
05:52 So having the image that's constantly the same, constantly in sync, that's the kind of way to force it.
05:57 I also want to give a quick shout out to this project, pip.dep.tree.
06:01 Remember, Brian, we spoke about that before, which is pretty cool.
06:04 And what it'll show you is this will show you the things you've directly installed versus the things that happen to be installed.
06:12 So if we go back to this like animation here, you can see that it's got Flask, which is 202.
06:18 But then it's got markup safe.
06:21 It's got it's dangerous.
06:22 Like nobody installed it's dangerous.
06:24 That's a thing that was installed because of Flask.
06:26 And so, for example, when I look at my environments, there were some things that were out of date, but they were out of date because they were pinned requirements.
06:34 Of other things that I actually wanted to install.
06:36 So, for example, example, doc opt and some other things are pinned to lower versions.
06:41 And I can't really update those, but they'll show up as outdated.
06:45 So you might pair this with some pip.dep.tree to see like what ones are you in control of and what ones are just kind of out there.
06:51 That's pretty cool.
06:52 That's that one.
06:53 What do you got for us?
06:55 Well, this is an interesting discussion about a possible change to future Python.
07:00 Again, this is just stuff that people are discussing.
07:04 It's nothing that's even decided on.
07:06 But it's an idea of late bound arguments for Python.
07:12 For late bound arguments for defaults.
07:17 That's it for functions.
07:20 Here's the idea.
07:22 So we know that if you sign the default value for a function argument, that is bound at definition time.
07:33 So when Python first goes and reads it.
07:36 That seems fine.
07:38 It's a weird thing about the namespace there, though.
07:41 So what happens is if you have a variable foo, for instance, or a value foo, the value expression can be looked.
07:52 You can look that up in the defining area.
07:56 So the namespace where the function is defined.
07:58 It's a little specific, but it causes some weirdness.
08:02 It's not the namespace of the function.
08:04 It's the namespace of the surrounding the function.
08:07 The problem with that really is that, like, for instance, if we wanted to do something like a bisect function that took, you know, has a given an array and maybe an x value for the middle or something.
08:21 We also have a high and low.
08:22 We know the low index would be zero as a default.
08:25 But what the high should be is should be the length of the array.
08:30 And it's you can't do that because you can't reference the array as a default value.
08:35 So that's what this kind of what this discussion is about is trying to figure out a way to possibly have an optional late binding of those values.
08:45 And and in this specific case, it'd be very helpful to be able to late bind that value, like at the time that the function is called, not at the time that it's defined.
08:55 And this was you want to take the first parameter and use it to set the default value of the subsequent parameter.
09:02 Yeah.
09:02 Like to say, like the length of the array is the default for length or something.
09:07 And that's the that was was it Chris Angelico that suggested this.
09:14 And the discussion actually got has some people even even Guido said, I'm not really opposed to it.
09:21 Let's let's explore it a little bit.
09:23 So there is some Chris is trying to do a proof of concept.
09:26 There is some question about what the syntax was should be.
09:30 So Chris suggested a equal colon.
09:35 So like the reverse of the walrus operator, because apparently that's available.
09:40 Another suggestion was equal greater than to kind of look like an arrow.
09:46 But we already have like dash arrow to mean something else.
09:49 So up in the air on the syntax.
09:52 But anyway, one of the things I wanted to comment about is the in the article we're linking to.
10:01 It says at first blush, Angelico's idea to fix this wart in Python seems fairly straightforward.
10:08 But the discussion has shown that there are multiple facets to consider.
10:12 Oh, yeah.
10:12 And it's always tricky to add complexity or to the language.
10:16 So, you know, the people in the steering council will take it.
10:21 Think about it.
10:22 Right.
10:22 Under consideration.
10:24 Yes.
10:24 OK.
10:24 Renee, what do you think about this?
10:26 I'm going to be honest.
10:27 It's going over my head a little bit.
10:29 I don't consider myself like a real software developer.
10:32 So I usually use Python for, you know, standard data science type of scripts.
10:37 I'm trying to sit here thinking of a use case for this that I would use and not coming up with one.
10:41 Yeah, I'm with you on that one as well.
10:43 That doesn't mean it's a bad idea necessarily.
10:46 Well, one use case would be to be able to set an empty list as a default value.
10:55 You can't do that now because the list is bound.
10:58 All calls to the function will get whatever the last function set it to.
11:03 And that's a weirdness in Python, but we could probably fix that with this.
11:07 Yeah.
11:07 Yeah.
11:08 That's what I was thinking as well, is if you pass immutable value as the default, then you're asking for trouble.
11:14 Right.
11:14 Because if it gets changed anywhere, then every subsequent call gets those changes applied to it.
11:20 So that seems useful.
11:21 This like sort of flowing one parameter into the next.
11:25 I'm not sure it's worth the complexity.
11:27 So, Renee, what I wanted to ask you was, as somebody who doesn't dive deep into the low levels of the language and like compiler parsing, all that kind of stuff, which is totally fine.
11:38 That's like 99% of the people.
11:40 How do you feel about these kinds of new features coming along?
11:44 Are you like, oh, geez, now I got to learn the walrus operator.
11:46 I got to learn pattern matching.
11:48 I was fine.
11:49 And now I got to deal with this code.
11:50 What is this?
11:50 Or do you see it as like, oh, awesome.
11:52 Here's new stuff.
11:53 Yeah, I mean, I guess it depends how much it really impacts my day-to-day work.
11:57 If it's something that it's not impacting something I use frequently or it's kind of abstracted away from me or optional, then, you know, go ahead.
12:05 But if it's something that some, you know, some features they roll out clearly have a wide-ranging impact and you have to go update everything.
12:13 So I'm not great at keeping up with that, which is one reason that, you know, of course, you have to be so careful when you update to a new version.
12:20 But, you know, I guess that's why people listen to podcasts like this.
12:24 So you know it's potentially coming.
12:25 So you're aware.
12:26 I guess so.
12:27 When it does come out, you're on top of it.
12:29 But I don't have strong opinions.
12:32 And what we worry about a lot in data science is the packages, right?
12:35 So not the base Python, but the packages are constantly changing and the dependencies and the versions.
12:40 So that does end up affecting us when it follows through to that level.
12:45 Yeah, my concern is around teaching Python.
12:49 Because every new syntax thing you put in makes it something that you potentially have to teach somebody.
12:55 And maybe you don't have to teach newbies this, but they'll see it in code.
13:01 So they should be able to understand what it is.
13:04 But on the other hand, like things like you can do really crazy comprehensions, list comprehensions and stuff, but you don't have to.
13:12 And most of the ones I see are fairly simple ones.
13:14 So I don't think we should nix a phone.
13:17 Nick shouldn't nix something just because it can be complicated.
13:20 Anyway.
13:21 Yeah.
13:22 Indeed.
13:22 Yeah.
13:23 Good one.
13:23 All right.
13:24 Renee, you got the next one.
13:24 All right.
13:25 So speaking of data science packages, a lot of us use Pandas.
13:29 So I wrote a book, which I'll come back to later, called SQL for Data Scientists.
13:34 And since I wrote that and, you know, some people that have been learning data science in school or, you know, on the job haven't always used SQL or if they use it as kind of a separate process from their Python.
13:45 So they started asking me, how do you use SQL alongside Python?
13:48 So this is kind of beginner level, but also something that's just very useful.
13:54 In the Pandas package, there's a read SQL function.
13:58 And so you can read a SQL query.
14:00 It runs the query.
14:02 It's kind of a wrapper around some other functions.
14:04 It will run the query and return the data set into your data frame.
14:08 And so basically you're just running a query and the results become the data frame right in your notebook.
14:14 So let's see some of my notes on here.
14:17 So you can save your SQL as a text file.
14:20 So you don't have to have the string in your actual notebook, which is sometimes useful.
14:24 And then when you import it in from that Pandas data frame, that's where a lot of people do their data cleaning and feature engineering and everything like that.
14:33 So you could just pull in the raw data from SQL and do a lot of the data engineering there.
14:37 Sometimes I do feature engineering in SQL and then pull it in.
14:41 So that's kind of up to each user.
14:43 But you really just set up the connection in your database using a package like SQLAlchemy.
14:48 So you have a connection to the database and you pass your SQL string either directly or from the file and the database connection and it returns a Pandas data frame.
14:59 So I'm happy to talk a little bit more about how I use this at work.
15:03 I think this is really good.
15:04 You know, one of the things to do with Pandas is there's just so many of these little functions that solve whole problems.
15:12 You know, it's like, oh, you could go and use requests to download some HTML and you could use beautiful soup to do some selectors and you could get some stuff and parse out some HTML.
15:23 And then you could get some table information out and then convert that into a data frame.
15:27 Or you could just say, read HTML table bracket zero or whatever.
15:32 And boom, you have it like knowing about these, I think is really interesting.
15:35 So it's cool that you highlighted this one.
15:37 I actually just, on a side, I'm just literally like in an hour.
15:40 So probably before this show ships, we'll ship this episode I did with Vex.
15:45 You have about 25 Panda functions you didn't even know existed.
15:49 And what's interesting is like this one wasn't even on the list.
15:52 So good.
15:54 So I'll highlight another one.
15:55 Now, you know, exists.
15:56 That's pretty cool.
15:58 Let's see a couple of comments from the audience.
16:00 Sam Morley.
16:01 Hey, Sam says, Pandas is so amazing.
16:03 I always find something too late that it has all of these IO functions.
16:07 And then we have Paul Ansel.
16:10 Hey, Paul says, do you have any recommendations on tutorials for how to create good SQLAlchemy selectables?
16:16 This always feels like the scariest bit.
16:19 I don't have any of that on hand.
16:20 I'll try to find something later or I'll ask my Twitter following and see what they recommend.
16:25 I don't have a good list of tutorials for that one.
16:27 I can talk about, yeah, by selectable, he said he means connectable.
16:32 So, yeah, I don't have a tutorial for that.
16:35 There's a lot of documentation.
16:36 And I know that SQLAlchemy can be a little mysterious sometimes.
16:40 Maybe that's why it's alchemy.
16:42 But, yeah, I will try to share that later on Twitter.
16:46 Yeah, fantastic.
16:47 All right.
16:48 And Paul says, read clipboard is pretty great.
16:51 Yeah.
16:52 Yeah, very cool.
16:53 Bunch of different things there.
16:54 Yeah.
16:55 So if you want me to walk through an example of how I use this at work, I'm happy to do that.
16:58 Yeah, give us a quick example.
16:59 Yeah.
17:00 So at Helio Campus, one thing we do is we connect to a lot of different databases at universities.
17:06 So the universities will have separate databases for admissions, enrollment, financial aid.
17:12 Those are all separate systems.
17:12 Those are all separate systems.
17:14 And so we pull all that data into a data warehouse.
17:16 And in SQL, we can combine that data.
17:22 And so we can either use this to just read one of those tables directly.
17:26 Or we can combine what I typically do is do a little bit of cleanup and feature engineering and narrow down my data set to the population that I want to run through my model in SQL.
17:36 And then just pull those final results.
17:38 And now I've got my data set with at least preliminary features.
17:41 I might do some standardization and things like that in pandas.
17:44 But I've got a pretty clean and subset of the data that I need right into my Jupyter notebook.
17:52 Oh, that's fantastic.
17:53 Pretty great.
17:53 Yeah, I think definitely understanding SQL is an important skill for data scientists.
17:58 And it's slightly different than for, say, like a web API developer, right?
18:04 Absolutely.
18:04 That's why I wrote the book.
18:05 That's awesome.
18:06 Yeah, for sure.
18:07 So on the API side, you kind of get something set up.
18:10 You're very likely using an ORM like SQLAlchemy and you just connect it and go.
18:15 And once you get it set, you can kind of forget about it and just program against it.
18:18 As a data scientist, you're exploring.
18:20 You don't totally know, right?
18:21 You're kind of out there testing and digging into stuff and sorting and filtering.
18:25 And yeah, I would say you probably need a better fluency with SQL as a data scientist a lot of times than as a web developer.
18:33 Because I can just use an ORM or ODM and just kind of know what it's doing.
18:37 Yeah, and it enables you to build your own data sets instead of relying on a data engineering trying to explain what you need and why and which fields you need.
18:45 Now you could just do it yourself or, you know, add a field if you need it.
18:48 You can do more sophisticated things like window functions.
18:51 So yeah, I think knowing SQL is really a value add if you're looking to become a data scientist and, you know, putting yourself out there on the market.
18:59 If you can do the whole pipeline end to end, it definitely makes you stand out.
19:03 I would think so.
19:04 All right.
19:05 One thing to wrap up on this.
19:06 Sam asks, can you configure SQLAlchemy to dump the raw queries that it runs?
19:10 Yes.
19:11 Yeah.
19:12 In this case, you have the raw query in your function call.
19:15 So I'm not actually using SQLAlchemy for that because I'm providing a query.
19:20 Yeah, you just got a select statement, right?
19:21 The problem with SQLAlchemy and data science is you have to, the structure of your models has to exactly match the structure of the data.
19:28 And often I imagine you're just kind of dealing with the loose data and it doesn't make sense to take the time to like model it in classes.
19:35 But for SQLAlchemy, you can just set echo equal true when you create the engine.
19:38 And then everything that would get sent to the crossover to the database gets echoed as like DDL or SQL or whatever that it does.
19:46 So yes.
19:46 Good.
19:47 Cool.
19:47 For sure.
19:47 Yeah.
19:48 All right.
19:49 Brian, want to tell us about our sponsor?
19:51 Yeah, let's.
19:52 I am pleased and happy that Shortcut is sponsoring the episode.
19:58 So thank you, Shortcut.
19:59 Formerly Clubhouse for sponsoring the episode.
20:01 There are a lot of project management tools out there, but most suffer from common problems.
20:06 Like it's too simple for an engineering team to use on several projects or it's too complex and it's hard to get started.
20:14 And there's tons of options.
20:16 And some of them are great for managers, but bad for engineers.
20:19 And some are great for engineers and bad for managers.
20:21 Shortcut is different.
20:22 It's built for software teams and based on making workflows super easy.
20:27 For example, keyboard friendly user interface.
20:30 The UI is intuitive for mouse lovers, of course.
20:33 But the activities that you use every day can be set to keyboard shortcuts if they aren't already.
20:39 Just learn them and you'll start working faster.
20:43 It's awesome.
20:44 Tight VCS integration.
20:46 So you can update task progress and commits with a commit or a PR.
20:49 That's sweet.
20:51 And iteration planning is a breeze.
20:53 I like that there's a burndown and cycle time charts built in.
20:57 They just are set up already for you when you start using this.
21:00 So it's a pretty clean system.
21:02 Give it a try at shortcut.com slash Python bytes.
21:05 Yeah, absolutely.
21:06 Thanks, Shortcut.
21:07 For sponsoring this episode.
21:09 Now, what have we got next here?
21:10 Pidgin.
21:11 I want to talk about Pidgin.
21:12 So we already talked about Will McGooghan and Rich.
21:17 So it's time to talk about Anthony Shaw so that we can complete our shoutouts we always seem to give over on the podcast.
21:24 So I want to talk about Pidgin because I just interviewed Anthony Shaw.
21:27 But more importantly, he just released Pidgin as 1.0.
21:32 So Pidgin is a drop-in JIT compiler for Python 3.10.
21:36 Let me say that again.
21:37 A JIT compiler for Python.
21:39 And there have been other speed-up type of attempts where people will like fork CPython and they'll do something inside of it to make it different.
21:48 Think Cinder.
21:49 There have been attempts to create a totally different but compatible one like PyPy.
21:55 And they've worked pretty well, but they always have some sort of incompatibility or something.
22:02 It would be nice if just the Python you ran could be compiled to go faster if you want it to be.
22:07 So that's what this is.
22:09 It uses a PEP whose number I forgot that allows you to plug in something that inspects the method frames before they get executed.
22:17 And then instead of just interpreting that code, the bytecode as Python bytecode, it'll actually compile it to machine instructions.
22:26 First to .NET intermediate instructions, intermediate language.
22:30 And then those get JIT compiled to machine instructions that then run directly.
22:34 Works on Linux, macOS, Windows, X64, and ARM64.
22:39 So this is a pretty cool development.
22:42 It is pretty cool.
22:43 Yeah.
22:44 So if we go over here and check it out, in order to use it, it has some requirements.
22:49 You just pip install Pigeon.
22:50 That's it.
22:51 That's crazy, right?
22:52 And then it has to be on 310.
22:54 It can't be older than that.
22:55 And you have to have .NET 6 installed.
22:58 Okay.
22:58 So that just got released.
22:59 It's a good chance you don't have .NET 6 installed.
23:02 But then once you set it up right, you can just say import Pigeon, Pigeon.enable at the startup of your app.
23:07 And then it will look at all the methods and JIT compile them.
23:11 So if you come down here, like he has an example of a half function that Anthony put up here.
23:16 And when it first loads, it's not JIT compiled.
23:20 But after that, you can go and say, if you run it, you can say disassemble this thing.
23:24 And it'll show you basically assembly instructions of what would have otherwise been Python code.
23:31 Wow.
23:31 It's wild, right?
23:32 So it's a little bit like Numba.
23:34 It's a little bit like a tiny bit like Cython in the sense that it takes Python code, translates it into something else that then can be interoperated with, and then makes it go fast.
23:44 So this is all well and good.
23:46 If you're going to use it on the web, by default, it would be just fine.
23:49 Except if you're hosting it, normally you host it in this supervisor process and then a bunch of forked off processes.
23:57 So there's a WSGI app configuration thing you can do as well somewhere in the docs.
24:02 I'm not seeing it right now.
24:03 But you basically allow it to push the pigeon changes on down into the worker processes, which is pretty cool.
24:11 And it has a bunch of comparisons against PyPy, Piston, Numba, IronPython, et cetera, Nutka, and so on.
24:19 Now, it's not that much faster.
24:21 It is faster when you're doing more data science-y things, I believe, than if you're doing just a query against a database where you're mostly just waiting anyway.
24:29 But still, I think this is promising, and it's really pretty early days.
24:33 So the thing to look at is if there's optimizations coming along here somewhere in the docs.
24:41 Anthony lists out the various optimizations he's put in so far, and really, it just needs more optimizations to make it faster still, which is pretty neat.
24:50 I think that's pretty cool.
24:51 One of the things that my first reaction was, oh, it's .NET only, so I have to use it on Windows.
24:57 But that's not been that way for a long time.
25:00 So .NET runs on just about everything.
25:02 Yeah, exactly.
25:03 It supports all the different frameworks.
25:05 There's even this thing called live.trypigeon.com, where you can write Python code, like, over here on the left.
25:11 And then you can say, compile it.
25:13 And it will actually show you the assembly that it would compile to.
25:17 And then here's the .NET intermediate language.
25:20 I guess maybe they should possibly be switching orders here.
25:23 Like, first it goes to IL, and then it goes to machine instructions through the JIT.
25:27 But it shows you all the stuff that it's doing to make this work.
25:31 You could even see at the bottom, there's, like, sort of a visual understanding of what it's doing.
25:35 One of the things that's really cool that it does is, imagine you've got a math problem up here.
25:40 Like, you're saying, like, X equals Y times Y plus Z times Z, or, you know, something like that.
25:47 Like, each one of those steps generates an intermediate number.
25:51 So, for example, Z times Z would generate, by default, a Python number.
25:56 And then so would Y times Y, and then the addition, and finally you assign it.
26:01 What it'll do is it'll say, well, okay, if those are two floats, let's just store that as a C float in the intermediate computation.
26:07 And then that's as a C float.
26:09 And so it can sort of stay lower level as it's doing a lot of computational type of things.
26:13 So there's a bunch of interesting optimizations.
26:15 People can check this out.
26:16 I haven't had a chance to try it yet.
26:17 I was hoping to, but haven't got there yet.
26:19 Yeah, really interesting conversation you had with him, too.
26:22 Oh, thanks.
26:24 It's interesting timing to just get him to jump on this, like, right after he wrote the book on Python internals, CPython internals, to jump into this.
26:33 Well, I guess he's working on it before, but still.
26:36 Yeah, you definitely got to know CPython internals to do this.
26:40 Renee, do you guys do anything to optimize your code with, like, Numba or Cython or anything like that?
26:48 Or are you just running straight Python and letting the libraries deal with it?
26:51 Yeah, not currently.
26:52 We have a pretty good server and are working with relatively small data sets, you know, not millions of rows, for example.
26:59 So for right now, we haven't gone in this direction at all.
27:03 I can imagine this would also be really useful if you were a computer science student and trying to understand what's going on under the hood when you run these things.
27:11 So it's interesting that it's for the people that aren't seeing the visual, you kind of have three columns here with the code side by side to kind of get a peek under the hood at what's going on there.
27:21 But no, this isn't something I've used personally.
27:23 Yeah, yeah.
27:24 I haven't used it either.
27:25 But like I said, I would like to.
27:26 I think it's got the ability to just plug in and make things faster.
27:30 And really, it is faster to some degree.
27:33 Sometimes I think it's slower, sometimes faster.
27:35 But the more optimizations the JIT compiler gets, the better it could be, right?
27:40 So like if it could inline function calls rather than calling them, or it could, there's things like if it sees you allocating a list and putting stuff into it, it can skip some intermediate steps and just straight allocate that.
27:54 Or if you're doing accessing elements by index out of the list, it can just do pointer operations instead of going through the Python APIs.
28:01 There's a lot of hard work that Anthony's put into this, and I think it's pretty cool.
28:06 Yeah, I haven't tried it.
28:08 I would like to.
28:08 Yeah.
28:10 Cool.
28:10 Indeed.
28:11 All right.
28:11 Brian, what do you got for us?
28:12 Well, actually, before I jump to the next topic, I wanted to mention, I wanted to shoo into this last conversation.
28:18 Brett Cannon just wrote an interesting article called Selecting a Programming Language Can Be a Form of Premature Optimization.
28:27 And this is relevant to the conversation.
28:32 He says if you think Python might be too slow, another implementation like Pigeon is like step three.
28:40 So first prototype in Python, then optimize your data structures and algorithms and also profile it.
28:47 And then try another implementation before you abandon Python altogether.
28:52 And then, you know, you can do some late bindings like language bindings to connect to see if you need to or rust.
29:00 But I think it ties in as like when would I choose Pigeon or PyPI over CPython.
29:07 Well, it's step three, just to let people know.
29:10 Step three.
29:12 Got it.
29:12 Step three.
29:13 I wanted to do something more lighthearted, like use print for debugging.
29:17 So I love this article.
29:20 I am guilty of this.
29:22 Of course, I use debuggers and logging systems as well.
29:26 But I also throw print statements in there sometimes.
29:29 And I'm not ashamed to say it.
29:31 So Adam Johnson wrote tips for debugging the print.
29:35 And there were a couple that with print, there were a couple that stood out to me.
29:38 I really wanted to mention because I use them a lot.
29:41 Even with logging, though, is use debug variables with f-strings and the equal sign.
29:48 So this is brilliant.
29:51 It's been in since 3.8.
29:52 Instead of typing like print widget equals and then in a string and then the widget number or something,
29:59 you can just use the f-strings and do the equal sign and it interpolates for you.
30:05 Or it doesn't interpolate.
30:06 It just prints it for you.
30:07 So it's nice.
30:08 I like that.
30:10 The next one is, I love this.
30:12 Use emojis.
30:13 I never thought to do this.
30:14 This is brilliant.
30:15 Throw emojis in your print statement so they pop out when you're debugging.
30:22 Have you ever used emojis?
30:23 Yeah, this is cool.
30:23 I started using emojis in comments.
30:26 Oh, okay.
30:27 Comments.
30:27 Nice.
30:28 Yeah.
30:28 So I'll put like the different emojis mean for me, I was doing some API stuff.
30:33 So like, oh, this is the read only method here of an API.
30:35 So I'll put a certain emoji up there.
30:37 And this is one that changes data.
30:39 So here's what I'll put there.
30:40 Here's one that returns a list versus a single thing.
30:42 So I'll put a whole bunch of those emojis and stuff.
30:45 Yeah.
30:45 Well, I mean, I used to do like a whole bunch of plus signs because they're easy to see.
30:49 But an emoji would be way easier to see.
30:52 Way more fun, man.
30:53 Yeah.
30:53 Yeah.
30:54 I do this as well.
30:55 I print all the time for debugging, especially in Jupyter Notebooks, because you don't always
30:59 have the most sophisticated debugging tools in there.
31:01 But being able to print and see what's going on as you go through each step of the notebook.
31:06 And emojis are a great idea for that because it's so visual as you're scrolling through.
31:11 You want to like they're showing there the X and the checkmark emoji.
31:14 I like that for my little to-do lists in the comments that I leave for myself.
31:18 Yeah, yeah.
31:18 I have a thought.
31:18 So I've done that as well.
31:19 That's cool.
31:20 Chris May out in the audience just put a heart sign, smiley face emoji as a response
31:26 to this.
31:27 Love it.
31:27 Last thing.
31:28 He's got like seven tips.
31:30 The last tip I wanted to talk about was using rich and or specifically rich print, rich.print
31:36 or pprint.
31:38 So for pprint, you have to do from pprint install pprint or something, or unless you wanted to
31:44 say it twice with pprint dot pprint.
31:46 But pprint stands for pretty printing.
31:50 And the gist of this really is the structures by default print horribly.
31:55 If you just print like a dict or a set or something, it looks gross.
32:00 But rich and pretty print make it look nice.
32:04 So if you're debugging, printing with those and debugging, use that.
32:07 So yeah.
32:08 There's also exception handling stuff in there for it.
32:12 And there's a lot of that kind of debugging stuff in rich.
32:14 Yeah.
32:15 Printing exceptions is great with that.
32:17 I also wanted to say one of the reasons why I, one of the places where I use printing
32:22 a lot for debugging is I print to print stuff in my, what I expect is going on when I'm
32:29 writing a test function.
32:30 So I'll often print out the flow, what's going on.
32:33 The reason I do that is when if pytest for pytest, if a test fails, pytest dumps the standard
32:40 out.
32:40 So it'll dump all of your print statements from the failed procedure.
32:44 So that's either the test under code or the test itself.
32:47 If there's print statements, it gets dumped out.
32:49 So that's helpful.
32:50 Yeah.
32:50 Nice.
32:51 That's great.
32:52 I love it.
32:52 I use print statements a lot.
32:54 My output is very verbose.
32:55 You can see right in order what's happening.
32:58 Sometimes a debugger helps, but sometimes it's time to just print.
33:02 Yeah.
33:03 Speaking of visual stuff, what's your last one here, Renee?
33:05 Yeah.
33:06 So in our line of work with data science, especially when you're providing the models as tools for
33:12 end users that aren't the data scientists themselves, you really want the explainability is really
33:17 important.
33:18 So being able to explain why a certain prediction got the value it did, what the different inputs
33:23 are, we're always working to make that more transparent for our end users.
33:28 In our case, for example, we might be predicting which students might be at risk of not retaining
33:35 at the university.
33:36 So not being enrolled a year later.
33:37 So what are the different factors, both overall for the whole population that are correlated with
33:43 not being enrolled for a year?
33:44 And for each individual student, what might be particular factors that, at least from the
33:49 model's perspective, puts them at higher risk?
33:52 So this package is called SHAP, and that stands for Shapley Additive Explanations.
33:59 It was brought to my attention by my team member, Brian Richards at Helio Campus.
34:04 And now we use it very frequently because it has really good visualizations.
34:08 So these Shapley values, apparently they're from game theory.
34:12 I won't pretend to understand the details of how they're generated.
34:15 But you could think of it as like a model on top of your model.
34:18 So it's additive and all the different features.
34:22 If you see the visualization here, it's showing kind of a little waterfall chart.
34:26 So some of the values that you think of a particular row that you're running through your algorithm,
34:31 some of the values in that row are going to make the, if you're doing a classification model,
34:37 some values might make you more likely to be in one class.
34:40 Some might make you more likely to be in the other class.
34:42 So you have these visuals of kind of the push and pull of each value.
34:46 In this visual, we're seeing, you know, age is pushing a number to the right.
34:50 Sex is pushing it to the left.
34:52 I guess BP and BMI, that looks like a blood pressure.
34:55 So it's got this like waterfall type of chart.
34:58 And what it's actually doing is it's comparing.
35:00 It starts with the expected value for the whole population.
35:03 And then it's showing you where this particular record, each of the input values is kind of nudging
35:11 that eventual prediction one in one direction or the other.
35:15 So it's just nice visually to have those waterfall plots and to see which features are negatively
35:22 or positively correlated with the, you know, the end result.
35:27 And you could also do some cool scatter plots with this.
35:30 So you can do the input value versus the shop value and have a point for every item in your population.
35:37 So for in our, in our example, that would be students.
35:39 So we can have a scatter plot of all the students and something like the number of cumulative credits
35:45 that they have as of that term.
35:46 And so you'll see the gradient of like from low credits to high credits, it's not usually linear.
35:52 What are those kind of break points?
35:54 And at what point are the values, you know, positively impactful to likelihood to retain or in the opposite direction?
36:02 Of course, I'm glad that they put in this documentation, a whole, they have a whole section on basically correlation is not causation.
36:11 And we're constantly having to talk to our end users about that.
36:14 But, you know, if we say a student that, you know, lives in a certain town is, you know, potentially more likely to retain,
36:23 maybe because of distance from campus, or maybe you have traditionally recruit a lot of students from that town.
36:28 It doesn't mean that if you force someone to move to that town, they're more likely to stay at your institution.
36:33 Right.
36:34 So, yeah, correlation is not causation.
36:37 And I'm going to switch over here to the visual, to something called a B-swarm plot that you can output this right in your Jupyter notebook,
36:44 which is really handy when you develop a new model.
36:48 And I'll try to describe this for people who are listening to the audio.
36:51 It has along the x-axis a list of features.
36:56 So you've got in this example on their website, age, relationship, capital gain, marital status.
37:01 And then you see a bunch of dots going across horizontally.
37:05 And there's areas where there's little clusters of dots.
37:08 So what this is showing is the x-axis is the SHAP value.
37:12 So what this SHAP package outputs.
37:16 So you can see visually across, you know, what is the spread of the impact of this value.
37:22 So if each dot is a person in this case, you see people all the way to the right, whatever their age was, positively impacted their eventual score.
37:32 People all the way to the left, their age negatively impacted the score.
37:35 And then each dot is a color that ranges from blue to red.
37:39 So the blue ones are people with low age and the red ones are people with a high age.
37:45 So you can see here, basically the higher the age, the more positive their eventual prediction.
37:52 So just an interesting way to get both like a feature importance and see the distribution of the values within each feature.
38:00 So it's just really helpful when you're doing predictive models, both for evaluating your own model and then eventually explaining it to end users.
38:09 So would a wider spread mean that the feature is more useful or does it have any?
38:16 Yeah.
38:17 Especially if you can see a split in the numbers there.
38:19 So you see in this example, relationship, you've got all the red ones to the right and all the blue ones to the left.
38:25 That means that there's a clear relationship from this relationship field with the target variable.
38:31 So there's a clear split where the low values are on one side and the high values are on the other side.
38:37 And then, yeah, the spread means that if there's not a good example here, but sometimes you'll see like two clumps, two bee swarms spread apart with nothing in the middle.
38:48 So that's when you have a really clear spread of the high impact group versus the low impact group.
38:53 And if it's more narrow, that's less of an important variable.
38:58 So you see if you look at the one that's sorted by max, here we go, absolute value of the shop value, the ones near the bottom for the population have less impact.
39:11 Now there might be one person in there where that particular value was like the deciding factor of which class they ended up in.
39:18 But for the population as a whole, there's less differentiation across these values than across the ones near the top of the list.
39:25 Yeah, this is cool because that visualization of models is very tricky, right?
39:30 And it's something like knowing why you got an answer.
39:32 Now this looks very helpful.
39:34 Yeah, it's really useful.
39:35 And the visuals are so pretty by default, but then you can also pull those values into other tools.
39:40 So for each feature in each row, you get a shop value.
39:46 So you can write those back to the database and then pull those values into another tool.
39:50 Like we use it in Tableau to highlight for each student, what are those really important features, either making them, you know, if you're not making them, it's not causation, but, you know, correlated with their more likely to retain or less likely to retain.
40:06 So we might say, well, for this student, their GPA, that's the main factor.
40:10 Their GPA is really low.
40:11 Students with low GPAs tend not to retain.
40:13 And so when the end user is looking at all of their values in, you know, in a table or some other kind of view, you can use the shop value to highlight.
40:22 The GPA is the one you need to hone in on.
40:24 The student is struggling academically.
40:26 Right.
40:26 Try to help them get some help with grades, for example.
40:28 Cool.
40:29 Yeah, this is a great find.
40:30 Indeed.
40:31 Indeed.
40:31 Indeed.
40:32 Brian, that brings us to the extras.
40:34 Extras.
40:35 Got any extras for us?
40:36 I do.
40:37 I've got one that was just a quick one.
40:40 Let's see.
40:41 Pull it up.
40:43 Matthew Feigert mentioned on Twitter that pip index is a cool thing.
40:49 And I kind of didn't know about it.
40:52 So this is neat.
40:53 So pip index is something you can take pip index.
40:57 Well, specifically pip index versions.
41:00 So pip index does a whole bunch of stuff.
41:02 pip index versions will tell you, if you also give it a package, it'll tell you all the different versions that are available on PyPI and which one you have and which, you know, if you're out of date and stuff.
41:16 But so for instance, if you're thinking about upgrading something and you don't know what to upgrade to, you can look to see what all is there, I guess.
41:25 Or you want to roll it back.
41:27 You're like, oh, this version is not working.
41:28 I want to go back to a lower one.
41:31 But if you're on 2.0, is it not 1.0?
41:34 What is it, right?
41:34 What do you go back to?
41:35 And so this will like list all the available versions.
41:37 Basically, this is a CLI version of the releases option in pypi.org.
41:44 Right.
41:44 And that's not like obvious how to get to on PyPI.
41:48 But I know you can get to it.
41:50 You can see all the releases.
41:51 But by default, it doesn't show those.
41:53 So this is pretty quick.
41:55 Yeah.
41:55 Pretty neat.
41:56 Good one.
41:57 Good one.
41:57 Renee, how about you?
41:58 Some extras?
41:59 Sure.
41:59 I wanted to make sure to mention my book.
42:01 So just published and just out in Europe this week, actually, as a paperback, but it's been
42:06 out since September in the US.
42:08 SQL for Data Scientists, A Beginner's Guide for Building Data Sets for Analysis.
42:12 So I mentioned earlier, you know, I wrote this book because I think a lot of students coming
42:18 out of data science programs or people who are coming from maybe statistics background that
42:25 are in data science might not have experience pulling the data.
42:28 So in class, a lot of times you're given a clean spreadsheet to start with when you're building
42:32 your predictive model.
42:33 Then you get to the job and, you know, you sit down the first day and they say, great, build
42:37 us a model.
42:38 And you say, well, where's the data?
42:39 It's in a raw form in the database.
42:41 So you have to build your own data set.
42:43 So that's what the purpose of the book is, to kind of get you from that point of when you
42:47 have access to raw data to exploring and building your data set so that you can run it through
42:52 your predictive model.
42:53 So on the screen there, you see my website.
42:56 And for people on the audio, it's SQL for datascientist.com.
43:01 And you can go to different chapters on the website.
43:04 And I have some example SQL, and you can also run it.
43:07 So there's a SQLite database in the browser here.
43:11 And so you can actually copy and paste some of the SQL on the page, click execute, and it
43:17 shows up in a table down here.
43:18 You can edit it and rerun it.
43:20 So you get a little bit of practice with this, using the database in the book.
43:24 Neat.
43:24 Yeah.
43:25 Cool book.
43:26 And wow, SQLite in the browser.
43:28 Very neat.
43:28 Thank you.
43:29 Yeah.
43:30 Awesome.
43:31 It's a book that definitely should exist.
43:32 All right.
43:33 Really quickly, I'm going to do a webcast with Paul Everitt.
43:37 I haven't seen Paul in the audience today.
43:39 Paul, where are you?
43:39 No, I'm not sure.
43:40 He might be working.
43:41 But on November 23rd, I'm going to be doing a webcast around PyCharm.
43:46 I've updated my PyCharm course with all sorts of good stuff.
43:50 I haven't quite totally announced it yet because there's a few things I'm waiting, slightly
43:54 more stable versions to come out of JetBrains to finish some of their data science tools,
43:59 actually.
43:59 And then I'll talk more about it.
44:01 But we're doing a webcast in about a week or so.
44:04 So that should be a lot of fun.
44:05 And yeah, come check it out.
44:07 Watch Paul and me make the code go.
44:10 Two days before Thanksgiving.
44:11 Yes, indeed.
44:13 All right.
44:13 That brings us to our joke.
44:15 I need a joke.
44:16 And the joke is a response to something that you posted on Twitter.
44:21 Really appreciate my foresight of using lots of stuff comment as the message in Git commit.
44:27 Well, it actually confused me because I did a Git rebase main and it said applying lots of
44:31 stuff.
44:31 And I thought it was a feature of Git rebase and it just happened to be my commit message.
44:38 Yeah.
44:38 It's like, oh, Git's gotten real casual.
44:40 It's a lot of stuff.
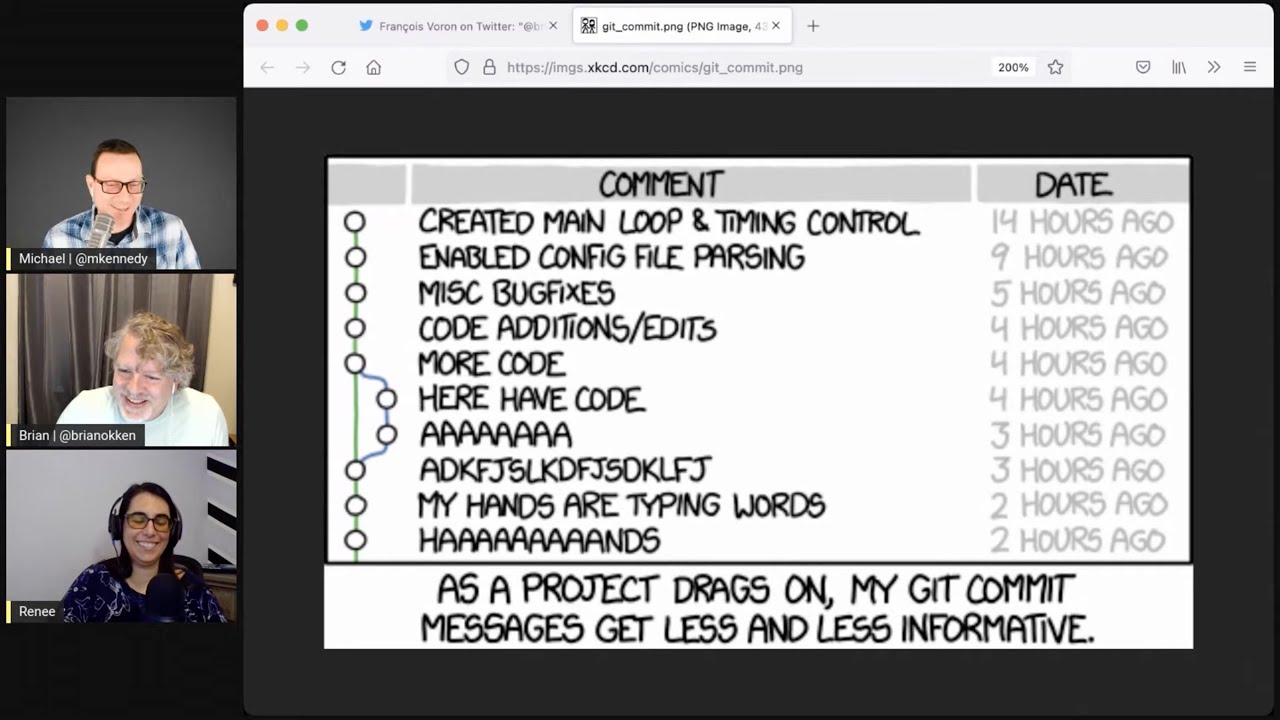
44:41 So Francois Voron said, time for a classic XKCD link here.
44:47 Yeah.
44:48 Oh, yeah.
44:48 Yeah.
44:49 And so this is like the commit history throughout the project as you get farther into it.
44:55 So it starts out with very formal, proper comments like created main loop and timing control.
45:01 The next commit is enabled config file parsing.
45:04 And then starts to miscellaneous bug fixes and then code additions and edits.
45:09 And then a branch, more code.
45:12 You have code, just eight letter A's.
45:16 It comes back with screaming.
45:18 Exactly.
45:19 Just A-D-K-F-J-S-L-K.
45:22 Just a bunch of home row.
45:23 And then my hands are typing words.
45:25 And then just hands.
45:27 And the title is, as a project drags on, my Git commit messages get less and less informative.
45:33 We've all been there, right?
45:34 Yeah.
45:34 Yes.
45:35 It happens to me with branch names too.
45:39 Because if I'm working on one feature and push part of it and then I go and I'm still working
45:44 on it, I like to use a new branch name.
45:47 And I just, I can't, it's hard to come up with good branch names for a feature.
45:51 I'm branching.
45:52 Exactly.
45:54 I try, I try to be more formal on the branches at least so I know I can delete them later.
45:59 And so when I'm working on projects that are mostly just me, I'll create a GitHub issue
46:04 and then create the branch name to be like a short version of the issue title and the issue
46:08 number.
46:09 So then when I commit back in, I can just look at the branch name and put a hash that
46:13 number and it'll tag it in the commit on the issue and GitHub.
46:17 Yeah.
46:17 If I'm working with someone like a team, I might put like my name slash branch name.
46:23 And then actually in some of the tools like source tree, you have like little expando widgets
46:26 around that on the branches.
46:28 So you can say these are Michael's branches and these are Renee's branches and so on.
46:32 Yeah.
46:32 We got into the habit of doing that too.
46:34 It helps a lot to see right up front whose branch is this?
46:37 Yeah.
46:38 I can get, can get out of control.
46:39 Right.
46:39 All right.
46:40 A quick couple follow-outs, Brian.
46:41 Anthony says, the book looks great, Renee.
46:44 I'll check it out.
46:45 Great.
46:46 Thank you.
46:46 Chris May likes it as well.
46:48 It's a great book idea.
46:49 I do like it.
46:50 Especially when I keep working long after I should have gone home.
46:53 No, this is the joke.
46:54 This is me.
46:55 Especially after I keep working long after I should have gone home and gone home.
46:58 Yeah, absolutely.
46:59 And Sam, oops, forgot to stage this as a common message in my repositories.
47:04 Nice.
47:06 Indeed.
47:06 So, cool.
47:07 It was a fun episode.
47:09 Thanks, Renee, for coming on.
47:10 Yeah, thanks for having me.
47:12 It's fun.
47:12 Don't get to dive into Python too often.
47:15 I mean, I'm using the same type of things over and over.
47:17 So it's nice to see what's new and what's on the horizon.
47:19 Awesome.
47:20 Yep.
47:20 Thanks, Mike.
47:21 Thanks, Brian.
47:22 Bye.
47:22 Bye.
47:22 Bye.
47:22 Bye.
47:22 Bye.




