#265: Get asizeof pympler and muppy
Watch the live stream:
About the show
Sponsored by us:
- Check out the courses over at Talk Python
- And Brian’s book too!
Special guest: Matt Kramer (@__matt_kramer__)
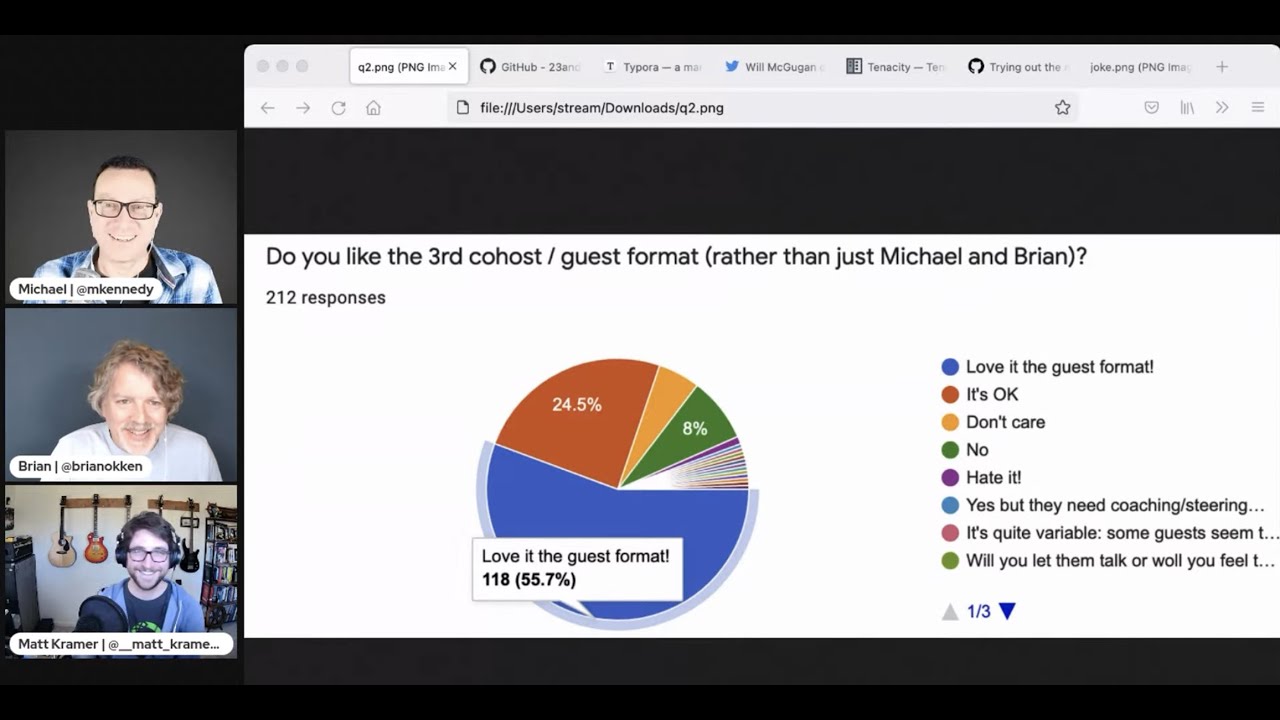
Michael #1: Survey results
- Question 1:

Question 2:

- In terms of too long, the “extras” section has started at these times in the last 4 episodes:
- 39m, 32m, 35m, and 33m ~= 34m on average
Brian #2: Modern attrs API
- attrs overview now focus on using
@define - History of attrs article: import attrs, by Hynek
- predecessor was called
characteristic. - A discussion between Glyph and Hynek in 2015 about where to take the idea.
attrspopularity takes off in 2016 after a post by Glyph: The One Python Library Everyone Needs- In 2017 people started wanting something like attrs in std library. Thus PEP 557 and dataclasses. Hynek, Eric Smith, and Guido discuss it at PyCon US 2017.
- dataclasses, with a subset of attrs functionality, was introduced in Python 3.7.
- Types take off. attrs starts supporting type hints as well, even before Python 3.7
- Post 3.7, some people start wondering if they still need attrs, since they have dataclasses.
@define,field()and other API improvements came with attrs 20.1.0 in 2020.- attrs 21.3.0 released in December, with what Hynek calls “Modern attrs”.
- predecessor was called
- OG attrs:
import attr
@attr.s
class Point:
x = attr.ib()
y = attr.ib()
- modern attrs:
from attr import define@define class Point: x: int y: int
- Many reasons to use attrs listed in Why not…, which is an excellent read.
- why not dataclasses?
- less powerful than attrs, intentionally
- attrs has validators, converters, equality customization, …
- attrs doesn’t force type annotation if you don’t like them
- slots on by default, dataclasses only support slots in Python 3.10 and are off by default
- attrs can and will move faster
- See also comparisons with pydantic, named tuples, tuples, dicts, hand-written classes
- less powerful than attrs, intentionally
- why not dataclasses?
Matt #3: Crafting Interpreters
- Wanting to learn more about how Python works “under the hood”, I first read Anthony Shaw’s CPython internals book
- A fantastic, detailed overview of how CPython is implemented
- Since I don’t have a formal CS background, I found myself wanting to learn a bit more about the fundamentals
- Parsing, Tokenization, Bytecode, data structures, etc.
- Crafting Interpreters is an incredible book by Bob Nystrom (on Dart team at Google)
- Although not Python, you walk through the implementation of a dynamic, interpreted language from scratch
- Implement same language (called lox) in two interpreters
- First a direct evaluation of Abstract Syntax Tree, written in Java
- Second is a bytecode interpreter, written from the ground up in C, including a compiler
- Every line of code is in the book, it is incredibly well-written and beautifully rendered
- I highly recommend to anyone wanting to learn more about language design & implementation
Michael #4: Yamele - A schema and validator for YAML
- via Andrew Simon
- A basic schema:
name: str() age: int(max=200) height: num() awesome: bool() - And some YAML that validates:
name: Bill age: 26 height: 6.2 awesome: True- Take a look at the Examples section for more complex schema ideas.
- ⚠️ Ensure that your schema definitions come from internal or trusted sources. Yamale does not protect against intentionally malicious schemas.
Brian #5: pympler
- Inspired by something Bob Belderbos wrote about sizes of objects, I think.
- “Pympler is a development tool to measure, monitor and analyze the memory behavior of Python objects in a running Python application.
- By pympling a Python application, detailed insight in the size and the lifetime of Python objects can be obtained. Undesirable or unexpected runtime behavior like memory bloat and other “pymples” can easily be identified.”
- 3 separate modules for profiling
- asizeof module provides basic size information for one or several Python objects
- muppy is used for on-line monitoring of a Python application
- Class Tracker provides off-line analysis of the lifetime of selected Python objects.
- asizeof is what I looked at recently
- In contrast to
sys.getsizeof,asizeofsizes objects recursively. - You can use one of the asizeof functions to get the size of these objects and all associated referents:
- In contrast to
>>> from pympler import asizeof >>> obj = [1, 2, (3, 4), 'text'] >>> asizeof.asizeof(obj) 176 >>> print(asizeof.asized(obj, detail=1).format()) [1, 2, (3, 4), 'text'] size=176 flat=48 (3, 4) size=64 flat=32 'text' size=32 flat=32 1 size=16 flat=16 2 size=16 flat=16- “Function flatsize returns the flat size of a Python object in bytes defined as the basic size plus the item size times the length of the given object.”
Matt #6: hvPlot Interactive
- hvPlot is a high-level plotting API that is part of the PyData ecosystem, built on HoloViews
- My colleague Phillip Rudiger recently gave a talk at PyData Global on a new
.interactivefeature - Here’s an announcement in the HoloViz forum
- Allows integration of widgets directly into
pandasanalysis pipeline (method-chain), so you can add interactivity to your notebook for exploratory data analysis, or serve it as a Panel app - Gist & video by Marc Skov Madsen
Extras
Michael:
- Typora app, recommended!
- Congrats Will
- Got a chance to solve a race condition with Tenacity
- New project management at GitHub
Matt:
- Check out new Anaconda Nucleus Community forums!
- We’re hiring, and remote-first. Check out anaconda.com/careers
- Pre-compiled packages now available for Pyston
- We have an upcoming webinar from Martin Durant: When Your Big Problem is I/O Bound
Joke:

Episode Transcript
Collapse transcript
00:00 Hey there, thanks for listening. Before we jump into this episode, I just want to remind you
00:03 that this episode is brought to you by us over at Talk Python Training and Brian through his pytest
00:09 book. So if you want to get hands-on and learn something with Python, be sure to consider our
00:14 courses over at Talk Python Training. Visit them via pythonbytes.fm/courses. And if you're
00:21 looking to do testing and get better with pytest, check out Brian's book at pythonbytes.fm slash
00:27 pytest. Enjoy the episode. Hello and welcome to Python Bytes, where we deliver Python news and
00:32 headlines directly to your earbuds. This is episode 265, recorded January 5th, 2022. I'm Brian Okken.
00:41 I'm Michael Kennedy. And I'm Matt Kramer. Matt, welcome to the show. Thanks. Happy to be here.
00:46 Yeah, welcome, Matt. Who are you? Oh, so a huge fan. I've listened to every episode. I actually,
00:53 I'm one of these folks that started their career outside of software. I've heard a similar parallel
00:58 story a bunch of times in the past. So I have my degree actually in naval architecture, marine
01:03 engineering, which is design of ships and offshore structures. In grad school, I started, I was started
01:09 with MATLAB, picked up Python, thanks to a professor. And then over time, that's just grown and grown.
01:14 Spent eight years in the oil and gas industry and using Python mostly for doing engineering analysis,
01:20 a lot of digital type stuff, IoT type monitoring work. And about three months ago, I joined Anaconda
01:28 as a software engineer. And I'm working on our Nucleus cloud platform as a backend software.
01:33 Very cool. Awesome. Yeah. Congrats on the new job as well. That's a big change from oil and gas.
01:38 A couple of years. I mean, it is in Texas and all, but it's still, it's still on the tech side.
01:43 Yeah. No, it's, it's related, but obviously a different focus. I wanted to make writing code
01:49 my job rather than the thing I did to get my job done. So.
01:52 Fantastic. I'm sure you're having a good time.
01:55 Yeah. Well, Michael, we had some questions for people last week.
01:58 We did. I want to make our first topic a meta topic. And by that, I mean a topic about Python
02:04 bytes. So you're right. We discussed whether the format, which is sort of, I wouldn't say changed.
02:12 It's, I would rather categorize it as drifted over time. It's sort of drifted to adding this little
02:18 thing and do that different thing. And we just said, Hey, everyone, do you still like this format? It's
02:22 not exactly what we started with, but it's, it's where we are. So we asked some questions.
02:26 The first question I asked, which I have an interesting follow-up at the end here, by the
02:30 way, is, is Python bytes too long at 45 minutes? That's roughly the time that we're, we're going
02:36 these days, probably about 45 minutes. And so I would say, got to do the quick math here. I would say
02:42 70, 65%, let's say 65% are like, no, it's good. With a third of that being like, are you kidding me?
02:48 It could go way longer. I'm not sure we want to go way longer, but there are definitely a couple of
02:52 people that get, it's getting a little bit long. So I would say probably 12% of people said it's
02:57 too long. So I feel like it's actually kind of a decent length. And one of the things I thought it's
03:03 like, as we've changed this format, we've added things on, right? We added the joke that we started
03:08 always doing at the end. We added our extra, extra, extra stuff, but the original format was the six
03:13 items. You covered three, I covered three. Now it's two, two. And we got Matt here to help out with that.
03:17 So what is the length of that? And it turns out that that's pretty much the same length still. So the last
03:24 episodes, 39 minutes, 32 minutes, 35 minutes, 33 minutes, that's how long are our main segments up to the
03:30 end of the minute. So it's kind of like, for people who feel it's too long, I wanted to sort of say, like, feel free
03:34 to just delete it. Like you hear the six items, like delete it at that point. If you don't want to hear us ramble
03:39 about other things that are not pure Python, you don't hear us talk about the joke or tell jokes, no problem.
03:44 Yeah. Just, just stop. It's at the end for a reason. So if you're kind of like, all right,
03:50 well, I'm kind of done, then, then be done. That's totally good. Yeah. we'll put the important
03:53 stuff up first. the other one was, do you like us having a third coast like Matt or, shell
04:01 or whoever it is we've had on recently? And most people love that format or, you know, it's okay. So
04:07 that's like, I think that that's, that's pretty good. I do want to read out just a couple of comments as
04:11 well. There's stuff that you always get that are like, you just can't balance it. A couple of people
04:16 are saying like, you just got to drop the joke. Like, don't do that. The other people are like,
04:19 the joke is the best. Who doesn't want to stay for that? So, you know, like, well, again, it's at the
04:24 end. So, you, you can do that. But I also just wanted to say, thank you to everybody. They,
04:29 they wrote a ton of nice comments to you and me at the end of that Google forum. So, one is,
04:35 I can't tell what counts as an extra or normal, but it's fine. I love it. By the way,
04:39 it's such an excellent show. Fun way to keep current. Brian is awesome.
04:44 Oh, good. I asked my daughter to submit that.
04:47 She's good. I think your third grass, having a third guest is great. Like I said, drop the jokes,
04:53 keep the jokes for sure. Ideal. I, so anyway, there, there's a bunch of, nice comments.
04:58 I think the other thing, that I would like to just speak to real quick and get your thoughts on
05:03 and maybe you as well, Matt, cause you've been on the receiving end of this a lot is us having the
05:08 live audience. Right. I think having a live audience is really interesting. I also want to just acknowledge,
05:14 like we knew that that would be a slight drift of format, right? So if you're listening in the car
05:19 and there's a live audience comment, it's kind of like, well, but I'm not listening to it live.
05:23 That's kind of different, but I think it's really valuable. One time we had four,
05:28 maybe four Python core developers commenting on the stuff we were covering relative. Like that's a
05:34 huge value to have people coming and sort of feeding that in though. For me personally, I feel like it's,
05:39 yeah, it's a little bit of a blend of formats, but I think having the feedback from the audience,
05:44 especially when people are involved in what we're talking about, I think that's worth it.
05:47 Brian, what do you think?
05:48 Well, we, we, we try not to, to let it interrupt the flow too much, but there's some great stuff.
05:54 Like if somebody, if we say something that's just wrong, somebody will correct us. And that's,
05:59 that's nice. the other thing is, sometimes somebody has a great question on a topic that like,
06:07 we should have, we should have talked about, but we didn't, we didn't, we didn't. Right. We don't know
06:11 everything. We certainly don't. so I do want to add one more thing. the, there was a comment
06:18 like, Hey, we as hosts should let the guests speak. We should be better interviewers. I'm like,
06:23 this is not an interview format, you know, like talk Python is a great interview format. Oh,
06:28 that's where the guest is featured. Testing code is a great form interview format where the guest is
06:31 featured. This is sort of just three people chatting. It's not really an interview format. So,
06:37 and, and we always tell the guests to interrupt us and they just, they don't much. So, yeah. Yeah.
06:42 So Matt, what do you think of this live audience aspect? Like, do you feel like that's tracks or is it good?
06:47 Well, yeah. First of all, thank, I'm, I'm, I'm glad that, people generally like having a guest.
06:52 Otherwise this would have been very awkward. but no, I do like it. I think.
06:56 Well, where'd Matt go? Oh, he must've disconnected.
06:58 There was one. Occasionally there is a kind of a, a little bit of a disruption,
07:02 but I think in general it's been great. Yeah. I've definitely been listening when times when,
07:07 you know, a bunch of people are chiming in because there's always, as you know, that you,
07:11 you mentioned a GUI library and then there's about 12 other options that you may not have
07:15 covered in. Instead of waiting 12 weeks, you could just get them right out. so I think that's
07:20 great. And I, I'm, I'm generally a audio listener. I listen when I'm walking my dogs, but, but I love
07:26 having the video because when I am very, when I'm interested in something, I can go hop to it right
07:30 away and see what you're showing, which I really like. So. Yeah. Awesome. Thank you. two other
07:36 things that came to mind. Someone said it would be great if there's a way where we could submit
07:40 like ideas and stuff like that for guests, and whatnot. right here at the top in our menu,
07:47 it says submit. So please, reach out to us on Twitter, send us an email, do submit it there.
07:53 The other one was, if we could have time links, like if, if you go to the, the, to listen and at some
08:00 certain time, a thing is interesting that's mentioned, be cool. If you could like link at,
08:04 at a time, if you look in your podcast player, it has chapters and each chapter has both a link
08:10 and a time. So, like the thing that Brian's going to talk about next interpreters, if you want
08:15 to hear about that during that section in your podcast player, you can click the chapter title
08:20 and it will literally navigate you to there. So it's already built in. Just make sure you can see it in
08:26 your device. Yeah. All right. I think that's it, for that one, but yeah, thank you for everybody
08:31 who had comments and took the time. Really appreciate it. Yeah. And just the comment,
08:35 if you, if you want to be a guest, just email on that form and you might be able to do it.
08:40 That's right. That's right. Yeah. Great to have you here.
08:43 actually I didn't want to talk about interpreters. No, that's me.
08:47 Oh, wait, you're right. Well, you're talking about it now because I've changed. No,
08:51 let's talk about Adder. Sorry. I saw the wrong screen.
08:54 Go for it.
08:55 Apparently we're not professional here, but, no, it's okay. I wanted to talk about
09:01 Adder's. We, we haven't really talked about it much for a while because there are lots of reasons,
09:06 but Adder's is a great library and it just came out with Adder's, came out with a release 21.3.0,
09:14 which is why we're talking about it now. And there's some documents. There's a little bit
09:18 of change. There's some changes and some documentation changes. And I really,
09:23 in an article I wanted to cover. So one of the things you'll see right off the bat, if you look at the,
09:27 the overview page of the Adder's site is, is it, is it highlighting the define, decorator.
09:35 It's a different kind of way that if you've used Adder's from years ago, this is a little different.
09:41 So the, there's a, there's, there was a different weighted to a different API that was added in the
09:49 last release. And this is, or one of the previous releases. And now that's the preferred way. So this
09:56 is what we're calling modern Adder's. but along with this, I wanted to talk about an article,
10:01 that Hinnick wrote, about, about Adder's. And it's a little bit of a history and I really love this
10:08 discussion. So, and I'll try to quickly go through the history. early on, we didn't have
10:16 data classes. Obviously we had, we could handcraft classes, but there were problems with it. And there
10:21 was a library called characteristic, which I didn't know about. This was, this was, before I started
10:27 looking into things, that, and then glyph and Hinnick in, in 2015, we're discussing it ways to
10:34 change it. And that begat the old original Adder's, interface. And there were things like
10:41 Adder.s and Adder attribute that were partly out of the fact that the old way of characteristic
10:49 attribute was a lot of typing. So they wanted to something a little shorter. and then it kind of
10:55 took off. Adder's was pretty, pretty popular for a long time, especially fueled by a 2016 article by
11:02 glyph called the one Python library. Everyone needs, which was a great, this is kind of how I
11:08 learned about it. and then, there was a, you know, different kind of API that we were used to
11:15 for attrs and it was good and everything was great. And then in 2017, Guido and Hinnick and Eric
11:22 Smith talked about, at, in the Python 2017, they talked about how to make something like that
11:29 in the standard library. and that came out of that came PEP 557 and data classes and data classes
11:36 showed up in, in Python three seven. and then, so what, then a dark period happened,
11:43 which was people were like, why do we need attrs anymore? If we have data classes? Well,
11:50 that's one of the things I like about this, this article. And then there's an attached article
11:54 that is called why not, why not, why not data classes instead of attrs? And, and this
12:02 is, it's, it's important to realize that data classes have always been a limited set of
12:09 attrs. Adders was a, is a super set of functionality and there's a lot of stuff missing in data classes,
12:15 like, like, equal equality customization and validators. Validators and converters are very
12:22 important if you're using a lot of these. and then also people were like, well, data classes
12:28 kind of a nicer interface, right? Well, not anymore. the pound defines pretty, or they at
12:35 defines really nice. This is a really easy interface now to work with. So anyway,
12:40 yeah. And it has typing and it has typing. and, and I'm glad he wrote this because I'm,
12:46 I kind of was one of those people of like, am I doing something wrong? If I'm, if I'm, using
12:52 data classes, why should I look at attrs? And one of the things that there's a whole bunch of
12:57 reasons. One of the things that I really like is attrs, has, slots, the slots are
13:03 on to by, by default. So you have, you kind of define your class once instead of, keeping
13:09 it growing. Whereas the default Python way and data classes is to allow classes to grow at runtime,
13:15 have more, more attributes, but that's not really how a lot of people use classes. So if you, if you
13:21 came from another language where you have to kind of define the class once and not at runtime,
13:26 attrs might be a closer fit for you.
13:28 I like it. And it's whether you say at define or at data class, pretty similar.
13:32 Yeah. Yeah. Adders is really cool. I personally haven't used it, but I've always wanted to try it.
13:38 we're using FastAPI and, and Pydantic. So I've really come to like that library, but
13:42 attrs is something that looks really full featured and nice. definitely something I want to pick up.
13:47 Yeah, it's cool. And Pydantic also seems very inspired by data classes, which I'm learning now.
13:53 I suspected, but now learning that is actually inspired by attrs and they kind of sort of
13:58 leapfrog each other in this, this same trend, which is interesting.
14:01 Yep. So yeah, cool. Good one, Brian, Matt. I thought Brian was going to talk about this,
14:07 but you can talk about it.
14:07 This would be me. Yeah. so this one's not strictly Python related, but I think it's very
14:12 relevant to Python. so I mentioned earlier, I came from a non CS background. and I've always,
14:20 I've just been going down the rabbit hole for about 10 years now, trying to understand everything and pick
14:25 it up and, and really connect the dots between how do these very flexible objects that you're
14:30 working with every day, how do those get actually implemented? and so the first thing I did,
14:34 if you heard of this guy, Anthony Shaw, yeah, I think he's been mentioned once or twice. He wrote
14:39 a great book, shout out CPython internals. Really?
14:42 Anthony's out in the audience. He even says happy, happy new years. Hey, happy new years.
14:46 So this book is great. If you want to learn how CPython's implemented. but because I don't have a
14:52 traditional CS background, I've always wanted, you know, I felt like I wanted to get a little bit more
14:56 to the fundamentals and I don't remember where I found out about this book, but crafting interpreters,
15:01 I got the paperback here too. I highly recommend it. It's, it's, it's a, implementation of a
15:07 language from start to finish. Every line of code is in the book. it's a dynamic interpreted language,
15:13 much like Python. but I really like how the book is structured. So it is, it was written
15:19 over, I think five years in the open. I think the paperback may have just come out last year,
15:25 but you walk through every step from tokenization, scanning, building a syntax tree, and all the
15:31 way through the end. But what I really like about it is, is you actually, you develop two separate
15:37 interpreters for the same language. So the first one is written in Java. it's a direct,
15:42 evaluation of the abstract syntax tree. so that was really how I got a lot of these bits in my
15:48 head about what is an abstract syntax tree. How do you start from there? How do you represent these
15:52 types? But the second part is actually very, where I think it becomes really relevant for Python
15:56 because you, the second part is written in C it's a bytecode virtual machine, with garbage
16:02 collection. So it's not exactly the same as Python, but if you want to dig down into how would you
16:07 actually, you know, implement this with the types that you have available for you in C, but get
16:13 something flexible, much like Python, I really recommend this. so again, it's not directly,
16:18 there's some good side notes in here where they, he compares, you know, different implementations
16:23 between different languages like, Python and JavaScript, et cetera, Ruby. But I really liked
16:29 this book. I devoured it during my time between jobs and, yeah, I keep telling everyone about
16:34 it. So I thought it would be good for the community to hear. Yeah. Nice. Yeah. I didn't study this
16:39 stuff in college either. I mostly studied math and things like that. And so understanding how virtual
16:45 machines work and all that is just how code executes. I think it's really important. You
16:49 know, it's, it's not the kind of thing that you actually need to know how to do in terms of you
16:54 got to get anything done with it. But sometimes your intuition of like, if I asked the program to
16:59 work this way and it doesn't work as you expected, you expect, you know, maybe understanding that
17:04 internal is like, Oh, it's because the, it's really doing this and all, everything's all scattered
17:08 out on the heap. And I thought numbers would be fast. Why are numbers so slow?
17:11 But okay. I understand now. Yeah. I really liked the, I mean, it answered a lot of questions
17:17 for me. Like how does a hash map work? Right. That's a dictionary in Python. What is a stack?
17:22 Why would you use it? What is the, when you do a disassemble and you see bytecode, what does that
17:27 actually mean? Right. I really, I really enjoyed it. And he's got a really great, books open source.
17:33 It's got a really great build system. If you're interested in writing a book, it's very cool
17:37 how the adding lines of code and things like that are all embedded in there. And he's got tests,
17:43 written for every part where you add a new, you know, a new bit to the code, there's tests written
17:48 and there's ways where he uses macros and things to block them out. It's pretty, pretty interesting.
17:52 Nice. Testing books.
17:54 That's pretty excellent. Yeah. Yeah. So Matt, now being at Anaconda, like that world,
18:00 the Python world over in the data science stack, and especially around there has so much
18:05 of like, here's a bunch of C and here's a bunch of Python and they kind of go together. Does this
18:10 give you a deeper understanding of what's happening? Yeah, for sure. I think, CPython internals
18:15 gave me a really good understanding a bit about a bit more about the C API and why that's important.
18:20 it is, I'm sure you, well, as you know, and the listeners may know, like the binary compatibility
18:25 is really important, between the two and dealing with locking and the, the,
18:29 global interpreter lock and everything like that. so it's definitely given me a better conceptual
18:35 view of how these things are working. As you mentioned, I don't, you don't need to know it
18:39 necessarily on a day-to-day basis, but I've just found that it's given me a much better mental model.
18:43 Having an intuition is valuable. Yeah. quick audience feedback. Sam out in the live audience
18:50 says, I started reading this book over Christmas day and it's an absolute joy. So yeah, very cool.
18:55 one more vote of confidence for you there. Cool. Brian, are we ready for my, my next one?
19:01 Yes, definitely. A little, Yamale. Yeah, I'm hungry. So this one is cool. it's called
19:09 Yamale or Yamaly. I'm not a hundred percent sure, but it was suggested by Andrew Simon. Thank
19:14 you, Andrew, for sending this in. And the idea of this is we work with YAML files that's often used
19:22 for configuration and whatnot. But if you want to verify your YAML, right, it's just text. Maybe you
19:29 want to have some YAML that has a number for a value, or you want to have a string, or maybe you want to have
19:37 true false, or you want to have some nested thing, right? Like you could say, I'm going to have a person
19:42 in my YAML. And then that person has to have fields or value set on it, like a name and an age
19:48 with this library. You can actually create a schema that talks about what the shape and types of these
19:55 are much like data classes. And then you can use Yamaly to say, given a YAML file, does it validate?
20:02 Think kind of like Pydantic is for JSON. This is for YAML, except it doesn't actually parse the
20:07 results out. It just tells you whether or not it's, it's correct. Isn't that cool?
20:10 I think it looks neat. yeah.
20:13 Yeah. So it's, it's a pretty easy to work with, obviously requires modern Python. It has a CLI
20:20 version, right? So you can just say, YAML, give it a schema, give it a file, and it'll go through and
20:26 check it. It has a strict and a non-strict mode. It also has an API. So then to use it, just say,
20:32 YAML.validate schema and data, either in code or on the CLI. And in terms of schemas, like I said,
20:39 it looks like data classes. You just have a file like name:str, age:int. And then you can even add
20:44 additional limitations. Like the max integer value has to be 200 or less, which is pretty cool.
20:50 then also, like I said, you can have, more complex structures. So for example, they have what
20:55 they call a person, but then the person here, actually you could nest them. So you could have
21:01 like part of your YAML could have a person in it and then your person schema could validate that person.
21:06 So very much like Pydantic, but for YAML files, like here, you can see, scroll down, there's a, an
21:11 example of, I think it's called recursion is how they refer to it, but you can have like
21:16 nested versions of these things and so on. So if you're working with YAML and you want to validate
21:21 it through unit tests or some data ingestion pipeline or whatever, I just want to make sure
21:28 you're loading the files correctly, then you might as well hit it with some YAML-y guessing.
21:32 One of the things I like about stuff like this is that, things like YAML files, sometimes people
21:38 just sort of edit it in, in the Git repo, instead of making sure it works first and then
21:45 it gets, and then having a CI stage that says, Hey, making sure the animals valid syntax is,
21:52 is pretty nice so that you, so that you know it before it blows up somewhere else with some weird
21:57 error message. So yeah, exactly. Yeah. This is really cool. The validation of these types of input files,
22:03 especially YAML files is really tough. I've found just cause it's indentation based and, white space
22:09 is not a bad thing, obviously, but for YAML, it's tough. I can't tell you how many hours I've banged
22:15 my head against the wall in the past life. trying to get Ansible scripts to run and things like that.
22:20 So this is really neat. And anytime I see something like this, I just wish that there was one way to
22:25 describe those types somewhere like, and if preferably in Python, just cause I like that more, but this is
22:31 really cool. Yeah. I wouldn't be surprised if there's some kind of Pydantic mapping to YAML instead of to
22:36 JSON. and you can just kind of run it through there, but yeah, I think this is more of a challenge
22:41 than it is safe for JSON because JSON, there's a validity to the file, regardless of what the schema is,
22:48 where YAML less so, right? Like, well, if you didn't indent that, well, it just, that means it's,
22:53 it belongs somewhere else, I guess, you know, it's a little, a little more freeform. So I guess that's
22:57 why it's popular, but also nice to have this validation. So yeah. Thank you for Andrew. Thank
23:02 you to Andrew for sending that in. yeah. So next I wanted to talk about Pimpler, which is
23:08 great name. and I honestly can't remember where I saw this. I think it was a post on or something by Bob
23:15 Belderbos, or something he wrote on five bites. I'm not sure. anyway, so I'll give him credit. Maybe it was
23:23 somebody else. So if it was somebody else, I apologize. But anyway, what is Pimpler? Pimpler is a little tiny library,
23:28 which has a few tools in it. And it has, one of the things that says is, one of the things I saw, it does a few
23:37 things, but what I, it measures monitors and analyzes memory behavior and Python objects. but the, it's the memory
23:45 size thing that, that was interesting to me. So, you've got, like for instance, it has three, three tools
23:54 built into it, a size of and muppy, which is a great name, and class tracker. So a size of is a, provides a basic
24:03 size information for one or a set of objects. And muppy is a monitoring. I didn't play with this. I
24:11 didn't play with the grass, the class tracker, either class tracker provides offline analysis of
24:15 lifetimes of Python objects. Maybe if you've got a memory leak, you can see like there's a hundred
24:21 downs of my hundreds of thousands of this type. And I thought I only had three of them.
24:25 Yeah. And so one of the things that I really liked of, with a size of is, it's,
24:31 it, I mean, we already have, sys get size of in Python, but that just kind of tells you the
24:39 size of the object itself, not of the, like later on. So a size of will tell you not just what the size
24:48 of the object is, but all of the recursively, it goes recursively and, and, looks at the size of all
24:53 the stuff that it contents of it. So, right. And people haven't looked at this, you know,
24:57 they should check out Anthony's book, right? But if you've got a list and say, the list has a hundred
25:02 items in it and you say, what is the size of the list? The list will be roughly 900 bytes. Cause it's
25:09 108 byte pointers, plus a little bit of overhead. Those pointers could point at megabytes of memory.
25:15 You could have a hundred megabytes of stuff loaded in your list. And if it's really only a hundred,
25:19 like, no, that's 900 bytes, not 800 megabytes or whatever. Right. So you really need to,
25:24 if you actually care about real whole memory size, you got to use something like a size up. It's cool
25:28 that this is built in. I had to write this myself and, it was not as fun.
25:32 Yeah, this is awesome. I also, I hit this, sometime in grad school, I remember when I was
25:38 going to add a deadline or something. And, just, I hit the same thing about the number of bytes in a
25:44 list being so small and just writing something that was hacky to try to do the same thing,
25:48 but to have it so nice and available is great. And the name is awesome. I love silly names.
25:54 Yeah, for sure.
25:56 one of the example, and I was confused that the example we're showing on the screen is,
26:01 just a, there's, you've got a, a list of, a few items, some of it's a text to, some of them are
26:07 integers and some are lists of integers or tuples of integers and being able to go down and do the
26:13 size of everything. But then there's also a, you can get more detailed. You can, give it,
26:19 a sized, a size, with, with a detail numbers. I'd have to look at the API to figure
26:25 out what all this means, but the example shows each element, not just the total, but each element,
26:31 what the size of the different components are, which is kind of cool, but it lists like a flat size.
26:36 And I'm like, what's the flat thing? So I had to look that up and a flat, the,
26:41 flat size returns the flat size of a Python object in bytes determined as the basic size.
26:47 So like in these examples, it's, like the tuple is just a flat, the tuple itself is 32 bytes,
26:53 but the tuple and its contents is 64.
26:56 I see. So flat is like sys.get size of, and size is a size of that bit.
27:03 I think that's what it is.
27:05 It is. but yeah, not sure, but that's what I'm thinking.
27:08 Yeah. So for people who are listening, they don't see this. You should check out
27:11 the docs page, right? Like a usage example, because if you have a list containing a bunch of stuff,
27:15 you can just say, basically print this out and it shows line by line. This part of the list was this
27:21 much. And then it pointed at these things. Each of those things is this big and it has constituents
27:26 and, and so on. my theory is that the detail equals one is recurse one level down,
27:32 but don't keep traversing to like show the size of numbers and stuff. Yeah.
27:35 Yeah. Cool. Yeah. I love it. This is great. Yeah.
27:37 Oop.
27:39 All right. Take it all.
27:41 Okay. So, I'm going to talk about HV plot and, HV plot dot interactive, specifically. so this is something I actually wasn't very aware of until I joined Anaconda,
27:53 but one of my colleagues, Philip Rodeger, who I know is on talk Python, work point,
27:58 is our, is the developer working on this. And there's basically there's, you know,
28:02 when you're working in the PI data ecosystem, there's pandas and X array and tasks, there's all
28:06 these different data frame type interfaces, and there's a lot of plotting interfaces. And there's
28:11 a project called hollow views or HV plot, which is a consistent plotting API for that you can use. And,
28:19 and the really cool part about this is you can swap the backend. So for example, pandas default
28:25 plot, we'll use dot plot and it'll make a mat pot lib. But if you want to use something more
28:29 interactive, like bokeh or hollow views, you can just change the backend and you can use the same
28:35 commands to do that. so that's, that's cool. And you set it on the, on the data frame.
28:40 Yeah. Yeah, exactly. So what you, what you do is you import HV plot dot pandas. And then on the
28:46 data frame, if you change the backend, you just do data frame dot plot. and there's a bunch of
28:51 kind of, you know, rational defaults built in for how it would show the different
28:55 columns in your data frame, versus the index. And then I like that. Cause you could swap out
29:00 the plots by writing one line, even if you've got hundreds of lines of plotting and stuff,
29:05 right. And it just picks it up. Exactly. Yeah. And, and the common workflow for a data scientist is
29:11 you got, you're reading in a lot of input data, right? Then you want to transform that data. So
29:15 you're doing generally a lot of method chaining, is a common pattern where you want to do things like
29:21 filter and select a time and maybe pick a drop a column and do all kinds of things. Right.
29:26 At the end, you either want to show that data or write it somewhere or plot it, which is very common.
29:31 now there's interactive part. Philip demoed this or he gave a talk at PI data global about two
29:37 months ago. I think, it kind of extends on that. And this blew my mind when I saw it. So,
29:43 if you had a data frame like thing and you put dot interactive after it, then you can put your
29:49 method chaining after that. So this is an example where you say, I want to select a discrete time and
29:55 then I want to plot it. And this is, this particular example is not, doesn't have a kernel running in the
30:00 backend, so it's not going to switch. But if you were running this, in an actual live notebook,
30:06 it would be changing the time on this chart. And again, this is built to work with the, a lot of the
30:12 big data type APIs that match the pandas API. Nice. so for people listening, if you say
30:18 dot interactive and then you give the parameter that's meant to be interactive, that just puts
30:22 one of those I Python widget things into your notebook right there. Right. That's cool.
30:27 Yeah. So, a related, library is called panel, which is, it is for building dashboards
30:35 directly from your notebooks. so you can, if you had a, a Jupyter notebook, you could say panel
30:41 serve and pass in the notebook file. and it'll make a dashboard. That's the thing I want to show
30:46 in a, in a, in a second here, but the way the interactive works is really neat. So wherever you
30:51 would put a number, you can put one of these widgets. And so you can have time selectors, you can have
30:57 things like, sliders and you can have input boxes and things like that. And all you do is you would
31:04 change the place where you put your input number at, put one of those widgets in. And then it sort of,
31:09 it, it, I actually don't know how it works exactly under the hood, but from what I understand,
31:13 you put this interactive in, and then it's capturing all the different methods that you're adding onto
31:18 it. And anytime one of those widget changes, it will change everything from that point on.
31:22 and so the demo here was from another panel contributor, Mark Skoff, and that's in,
31:29 and I'm just going to play this and try to explain it. So we have a data pipeline on the right where we've
31:33 chained methods together. and what he's done here is he's just placed a widget in as a parameter
31:39 to these different methods on your data frame. And then this is actually a panel dashboard that's been
31:44 served up in the browser. And you can see this is all generated from the, a little bit of code on the
31:49 right. So if you want to do interactive data analysis or exploratory data analysis, you can really do this,
31:56 very easily with this interactive function. And when I saw this, I kind of hit myself in the head
32:02 because the, normally my pattern here was I had a cell at the top with a whole bunch of constants defined.
32:07 And, you know, I would manually go through and okay, change the time, start time from this time to this
32:13 time, or change this parameter to this and run it again. And over and over.
32:16 You got to remember to run all the cells that are affected.
32:18 Exactly. So the fact that the fact that you can kind of do this, interactively while you're working,
32:24 I could see how this would just, you know, you don't break your flow while you're trying to work.
32:30 And the method chaining itself is, I really like too, because you can comment out each stage of that,
32:35 as you're going and debugging what you're working on. So, yeah, this is really neat.
32:40 And I definitely, I put a link in the show notes to the actual talk, as well as this gist that
32:45 Mark Skobmatson put on GitHub. And, yeah, it's, it blew my mind. It would have made my life a lot
32:51 easier had I known about this earlier. So, yeah. And one of the important things I think
32:56 about plotting and, interactive stuff is it's not, even if your end result isn't a panel or an
33:02 interactive thing, sometimes getting to see the, see the plot, seeing, seeing the data in
33:10 the visual form helps you understand what you need to do with it.
33:13 Yeah, no, exactly. I mean, I did a lot of work in the past with time series data and
33:18 time series data, especially if this was sensor data, you had a lot of dropouts. you might
33:23 have spikes and, and you're always looking at it and trying to make some judgment about your filter
33:28 parameters and, and being able to have that feedback loop between, changing some of those and seeing
33:33 what the result is, is a huge game changer. So yeah. Yeah. And you, you can hand it off to someone
33:39 else who's not writing the code and say, here, you play with it and you, you tell, you know,
33:43 give it to a scientist or somebody.
33:44 Oh, that's exactly right. That's what panel's all about is what the biggest challenge that I
33:49 always had in many data scientists have is you do all your analysis in a notebook, but then you got
33:54 to show your manager or you got to show your teammates and going from that, going through that
34:00 trajectory is, can be very challenging. these new tools are amazing to do that, but that's how I
34:06 turned myself into a software engineer because that's what I wanted to do. But I went out,
34:10 went down the rabbit hole and learned Flask and dash and how to deploy web apps and all this stuff.
34:15 And yeah, well, I'm glad you did. Yeah. Maybe I wouldn't be here if I hadn't done that, but,
34:20 but yeah, this is really cool. And I definitely recommend people look at this. there was also
34:24 another talk this, sorry, this is an extra, but, there was another talk at PI data global,
34:30 hosted by Jim, James Bednar, who's our head of consulting, but he leads pyviz, which is a community
34:36 for visualization tools. And it was a comparison of four different, dashboarding apps. So it's
34:42 panel dash, voila and streamlit. And they, they just had, you know, main contributors from the four
34:50 libraries talking about the benefits and pros and cons of all of them. So if anyone wants to go look at
34:54 those, I definitely recommend that too. That sounds amazing. All those libraries are great.
34:59 Nice. Thanks. Oh, speaking of those extra parts of the podcast that make the podcast longer,
35:04 we should do some extras. We should, we should do some extras. Got any?
35:10 I don't have anything extra. Matt, how about you? Yeah. two things. So first, you can show my
35:17 screen. last year at a kind of hired the piston developers, piston is a faster implementation fork of
35:24 c python. I think it was at Instagram first. I can't recall, but anyway, before, right before the
35:29 holidays, they released, pre-compiled packages for many of a couple hundred of the most popular
35:35 python packages. So if you're interested in trying piston, I put a link to their blog post in here.
35:41 they're using conda right now. They were able to leverage a lot of the conda forge recipes for
35:45 building these. this is that binary compatibility challenge that we talked about earlier. So,
35:50 yeah, I know the team's looking for feedback on, on that. If you want to try that,
35:55 feel free to go there. And it mentions in the blog that they're working on pip. That's a little harder
35:59 to just because of how, you know, the build stages for all the packages aren't centralized with
36:04 pip. So it's a little more challenging for them to do that. and then just the last thing is,
36:10 you know, I don't want to be too much of a salesman here, but, we are hiring. It's an amazing
36:17 place to work and I definitely recommend anyone to go check it out if they're interested.
36:21 so fantastic. Yeah. And you put a link in the show notes. People want to, yeah,
36:25 it's anaconda.com slash careers. and we're doing a lot of cool stuff and growing. So if anyone's
36:31 looking for work in, in data science or just software and building out some of the things we're
36:37 doing to try to help the open source community, and bridge that gap, spelled it wrong, bridge that
36:42 gap between, enterprise and open source and data science in particular.
36:45 Yeah. And definitely seems like a fun place to work. So cool. People looking for a change or for
36:51 a fun Python job. Yeah. Yeah. Cool. People do reach out to Brian and me and say, Hey,
36:57 I really want to get a Python job and doing other stuff, but how do I get a Python job? Help us out.
37:02 So we don't know, but we can recommend places like Anaconda for sure.
37:07 Yeah. It looks like there's about 40 jobs right now. And, so check it out.
37:10 Fantastic. Oh, wow. That's awesome. All right. Well, would it surprise you if I had some extra things?
37:16 It would surprise me if you didn't.
37:17 All right. First of all, I want to say congratulations to Will McGugan.
37:23 We have gone the entire show without mentioning rich or textual. Can you imagine?
37:29 But no, only cause I knew you were going to talk about this. Otherwise I would have thrown it in.
37:34 Yeah. So Will last year, a while ago, I don't know the exact number of months back,
37:40 but he was planning to take a year off of work and just focus on rich and textual. It was getting so
37:46 much traction. He's like, I'm just going to, you know, live off my savings and a small amount of
37:50 money from the GitHub sponsorships and really see what I can do trying that. Well, it turns out he has
37:57 plans to build some really cool stuff and has actually all based around rich and textual in particular.
38:04 And he has raised a first round of funding and started a company called textualize.io.
38:11 How cool is that?
38:12 Well, we don't know because we don't know what it's going to do.
38:15 All you do is if you go there, it's like a command prompt. You just enter your email address. I guess
38:21 you enter something happens. Let's find out what happens. Yes, I'm confirmed. Basically,
38:25 just get notified about when textualize comes out of stealth mode. But congrats to Will. That's
38:29 fantastic. Another one we've spoken about tenacity. Remember that, Brian? Yeah. So tenacity is cool.
38:34 You can say here's a function that may run into trouble if you just put at, you know, tenacity.retry
38:40 on it and it crashes. It'll just try it again until it succeeds. That's probably a bad idea in production.
38:45 So you might want to put something like stop after this or do a little delay between them or do both.
38:51 I was having a race condition. We're trying to track when people are attempting to hack,
38:56 talk Python, the training site, the Python byte site and all that. And it turns out when they're
39:01 trying to attack your site, they're not even nice about it. They hit you with a botnet of all sorts
39:05 of stuff. And like lots of stuff happens at once. And there's this race condition that was causing
39:10 trouble. So I put retry, a tenacity.retry. Boom, solved it perfectly. So I just wanted to say I
39:15 finally got a chance to use this to solve some problems, which was pretty cool.
39:18 That's really cool. The other one that's similar to this, which I've used, and I think,
39:23 I don't know if you've used Brian, but it's called pytest Flaky. And it's awesome because
39:28 I was working with this time series data historian. I had a bunch of integration tests in my last job,
39:33 but you know, network stuff, it would drop out occasionally. And so you can do very similar
39:39 type things and wrap your test in an @flaky decorator and do similar type stuff and, you know,
39:45 give it three tries or something before you make it fail.
39:49 Yeah, exactly. That's cool. That's what mine, I think mine does three tries and it's like randomly
39:53 a couple of second delay or something. Remember that part, Brian, where we talked about,
39:57 it's really cool if people are in the audience while we talk about stuff and then get a little feedback.
40:00 So Will McGooghan says, "Hey, thanks guys. Can't wait to tell you about it." Yeah,
40:03 congrats, Will. That's awesome. Glad to see you out there.
40:05 All right. A couple of other things. Did you know that GitHub has a whole new project experience?
40:11 That's pretty awesome. Have you seen this? I haven't. I haven't seen this.
40:15 So you know how it's like this Kanban board, Kanban board, where you have like columns,
40:19 you can move your issues between them. So just last week, they came out with this thing called
40:24 a beta projects where it still can be that, or it can be like an Excel sort of view where you have
40:30 little drop down combo boxes. Like I want to move this one in this column by going through that mode
40:35 or as a board, or you can categorize based on some specification, like show me all the stuff that's
40:41 in progress and then give me that as an Excel sheet and all these different views you have for automation.
40:47 And then like there's APIs and all sorts of neat stuff in there. So if you've been using GitHub
40:52 projects to do stuff, you know, you can check this out. It looks like you could move a lot of,
40:57 a lot more work towards that on the project management side of software they used to.
41:01 This is really neat. Yeah. In my previous job, I was using Azure DevOps. I was always wondering
41:07 when some of those features might move to GitHub. I don't know if that's what happened here, but
41:10 being able to have this type of project management in there for this type of things, it's really,
41:16 really great. Yeah. Super cool. Yeah. One of the things I love about stuff like this is because
41:21 even, I mean, yes, a lot of companies do their project management on or projects on in GitHub or
41:28 places like that, but also open source projects often have their often have the same needs of project
41:36 management as, as private commercial projects. So, yeah. Yeah. I personally, I only have a few open source
41:44 projects that are kind of personal and no one would probably want to use them, but even just keeping
41:50 notes about to-dos and future stuff and it would be really nice. Yeah. Just for future you, if nothing
41:57 else, right? Yeah. Awesome. Okay. So this is cool. Now the last, yeah, this last thing I want to talk
42:01 about is Markdown. So, Roger Turrell turned me on to this. there's this new Markdown editor,
42:11 it's cross platform. Yes. Cross platform called Typora. And we all spend so much time in Markdown
42:19 that just, wow, this thing is incredible. It's not super expensive and it looks like a standard Markdown editor.
42:25 So you write Markdown and it gives you a whizzy wig, you know, what you see is what you get style of
42:31 programming, which is not totally unexpected. Right. But what is super cool is the way in which you
42:37 interact with it. And actually I am going to show you real quick. So you can, you can see it and then
42:42 you can tell people like, what do you think about this? here, I think that's it. I'm back.
42:47 Waiting.
42:48 There. Okay. Yeah. So here, here's, here's Mark, here's a Markdown file for my course, just the practices
42:52 and whatever you can say, you know what? I would like to view that in code style. Right. Well,
42:57 that's kind of cool. We want to edit this. You click here and it becomes,
43:00 Ooh, comes Markdown becomes Markdown. That's, but this is a boring file. So let's see about,
43:06 it has a whole file system that navigates like through your other Markdown stuff,
43:09 correctly. So like here, chapter eight, it's a good one. So we go over to chapter eight on this,
43:14 and now you can see some more stuff. Like you can go to set these headings and whatnot. But if you go to
43:18 images, like you can set a caption and then you could even change the image,
43:23 like right here, if it were a PNG, it's not, but so put it back as JPEG and then it comes back.
43:28 You can come down and write a code fence. use the right symbol and you can say def, a,
43:34 right, whatever. And then you pick a language. Isn't that, isn't that dope? Oh, this is so good.
43:41 So if, if you end up writing a lot of Markdown and if you need to get back, you just,
43:46 go back and switch back to raw Markdown and then go back to this fancy style. I think this is really
43:50 a cool way to work on Markdown. I'm actually working on a book with Roger and, it's got tons of
43:58 Markdown and it's been a real joy to actually use this thing on it. So yeah. Does it have VI mode?
44:03 VI mode? Probably not. I don't know about that, but it has themes. Like it has, it has,
44:08 like you can do like a, like a night mode or I could do like a newspaper mode or, you know,
44:13 take your pick. It's, it's pretty cool. The weirdo grad student in me is upset that this isn't LaTeX.
44:18 It has, it has built in LaTeX. It has like, you can do, yeah, you can do like inline LaTeX and you
44:25 can, there's a bunch of settings you can set for the LaTeX. It's got a whole, a whole math section
44:31 in there. Oh, that's sweet. Okay. Yeah. Let's see. So am I the only person that went all the way
44:35 through college pronouncing it LaTeX? I did too, but I just learned that the cool way of saying LaTeX.
44:40 LaTeX. Yeah. Yeah. It's French. No, I don't know. No. Yeah. It has, it has support for like
44:46 chemistry settings, like inline LaTeX and math and all sides of good stuff. So yeah, it's, it's,
44:51 I'm telling you, this thing's pretty slick. So, all right. Well, I got to do my screen share back
44:56 because so you all can see the joke because the joke is very good and we're going to cover it.
45:01 Where's the joke? But it's at the end. It's at the end. So if people don't want to listen to the joke,
45:05 they don't have to. Brian, I blew it. You did? I blew it. I blew it. Before I move off,
45:10 the Markdown thing though, Anthony Shaw says editorial for iPhone and iPad is really nice too.
45:14 Cool. So, but let's do, let's do the joke. So I blew it because I was saving this all year. I saw
45:22 this like last March and I'm like, this is going to be so good for Christmas. Yeah. And then we kind of
45:28 like had already recorded the episode. We're not going to do it. We'll just take a break over. So we
45:32 didn't have a chance to do it. So let's do it now. People are going to have to go back just a
45:36 little tiny bit for this one. Are you ready? Yes. Matt, you ready?
45:40 Yeah. So this goes, this sort of a data database developer type thing here. And it's on a, I don't
45:48 know why it's on a printout. Anyway, it's called SQL clause as in SQL clause. So it's, he's making a
45:56 database. He's sorting it twice. Select star from contract contacts where behavior equals nice. SQL
46:02 clause is coming. Nice. It would have been so good for Christmas, but we can't keep it another year. I got to
46:10 get it out of here. You're going to sing it. SQL clause is coming to town. Yep, exactly.
46:15 Okay. I want to share a joke that I don't have a picture for. All right. Do it. But,
46:20 but my daughter made this up last week. I think she made it up, but it's just been cracking me up for,
46:26 and I've been telling it to everybody. So it's a short one. Imagine you walk into a room and there's a
46:32 line of people all lined up on one side. That's it. That's the punchline.
46:38 I love it. Nice. We've got my, we had my, my cookie candle last time. Nice. My, I can't
46:48 all these cookies. We've got a dad joke of the day channel in our Slack at work. And it's,
46:53 it makes me oof every time. Nice. Nice. Okay. All right. Nice to see everybody. Thanks,
47:02 Matt, for joining the show. Thank you for having me. Good to see you, Michael, again, as always. Yeah.
47:06 Good to see you. Thank you. Thank you. Thanks for listening to Python Bytes. Follow the show on
47:11 Twitter via @pythonbytes. That's Python Bytes as in B-Y-T-E-S. Get the full show notes over at
47:17 pythonbytes.fm. If you have a news item we should cover, just visit pythonbytes.fm and click submit
47:23 in the nav bar. We're always on the lookout for sharing something cool. If you want to join us for
47:27 the live recording, just visit the website and click live stream to get notified of when our next episode
47:33 goes live. That's usually happening at noon Pacific on Wednesdays over at YouTube. On behalf of myself
47:39 and Brian Okken, this is Michael Kennedy. Thank you for listening and sharing this podcast with your
47:44 friends and colleagues.
- Many reasons to use attrs listed in Why not…, which is an excellent read.




