#281: ohmyzsh + ohmyposh + mcfly + pls + nerdfonts = wow

About the show
Sponsored: RedHat: Compiler Podcast
Special guest: Anna Astori
Michael #1: Take Your Github Repository To The Next Level 🚀️
- Step 0. Make Your Project More Discoverable
- Step 1. Choose A Name That Sticks
- Step 2. Display A Beautiful Cover Image
- Step 3. Add Badges To Convey More Information
- Step 4. Write A Convincing Description
- Step 5. Record Visuals To Attract Users 👀
- Step 6. Create A Detailed Installation Guide (if needed)
- Step 7. Create A Practical Usage Guide 🏁
- Step 8. Answer Common Questions
- Step 9. Build A Supportive Community
- Step 10. Create Contribution Guidelines
- Step 11. Choose The Right License
- Step 12. Plan Your Future Roadmap
- Step 13. Create Github Releases (know release drafter)
- Step 14. Customize Your Social Media Preview
- Step 15. Launch A Website
Brian #2: Fastero
- “Python timeit CLI for the 21st century.”
- Arian Mollik Wasi, @wasi_master
- Colorful and very usable benchmarking/comparison tool
- Time or Compare one ore more
- code snippet
- python file
- mix and match, even
- Allows setup code before snippets run
- Multiple output export formats: markdown, html, csv, json, images, …
- Lots of customization possible
- Takeaway
- especially for comparing two+ options, this is super handy
Anna #3:
- langid vs langdetect
langdetect
- This library is a direct port of Google's language-detection library from Java to Python
- langdetect supports 55 languages out of the box (ISO 639-1 codes):
- Basic usage: detect() and detect_langs()
- great to work with noisy data like social media and web blogs
- being statistical, works better on larger pieces of text vs short posts
langid
- hasn't been updated for a few years
- 97 languages
- can use Python's built-in wsgiref.simple_server (or fapws3 if available) to provide language identification as a web service. To do this, launch python langid.py -s, and access http://localhost:9008/detect . The web service supports GET, POST and PUT.
- the actual calculations are implemented in the log-probability space but can also have a "confidence" score for the probability prediction between 0 and 1: > from langid.langid import LanguageIdentifier, model > identifier = LanguageIdentifier.from_modelstring(model, norm_probs=True) > identifier.classify("This is a test") > ('en', 0.9999999909903544) - minimal dependencies - relatively fast - NB algo, can train on user data.
Michael #4: Watchfiles
- by Samual Colvin (of Pydantic fame)
- Simple, modern and high performance file watching and code reload in python.
- Underlying file system notifications are handled by the Notify rust library.
- Supports sync watching but also async watching
- CLI example
- Running and restarting a command¶
- Let's say you want to re-run failing tests whenever files change. You could do this with watchfiles using
- Running a command:
watchfiles 'pytest --lf``'
Brian #5: Slipcover: Near Zero-Overhead Python Code Coverage
- From coverage.py twitter account, which I’m pretty sure is Ned Bachelder
- coverage numbers with “3% or less overhead”
- Early stages of the project.
- It does seem pretty zippy though.
- Mixed results when trying it out with a couple different projects
- flask:
- just pytest: 2.70s
- with slipcover: 2.88s
- with coverage.py: 4.36s
- flask with xdist n=4
- pytest: 2.11 s
- coverage: 2.60s
- slipcover: doesn’t run (seems to load pytest plugins)
- flask:
- Again, still worth looking at and watching. It’s good to see some innovation in the coverage space aside from Ned’s work.
Anna #6:
- scrapy vs robox
scra-py
- shell to try out things: fetch url, view response object, response.text
- extract using css selectors or xpath
- lets you navigate between levels e.g. the parent of an element with id X
- crawler to crawl websites and spider to extract data
- startproject for project structure and templates like settings and pipelines
- some advanced features like specifying user-agents etc for large scale scraping.
- various options to export and store the data
- nice features like LinkExtractor to determine specific links to extract, already deduped.
- FormRequest class
robox
- layer on top of httpx and beautifulsoup4
- allows to interact with forms on pages: check, choose, submit
Extras
Michael:
Joke:
Episode Transcript
Collapse transcript
00:00 Hello and welcome to Python Bytes, where we deliver Python news and headlines directly to your earbuds.
00:05 This is episode 281, recorded April 27th, 2022.
00:10 I'm Brian Okken.
00:11 I'm Michael Kennedy.
00:12 And I'm Anna Story.
00:13 Welcome, Anna.
00:15 Thank you.
00:16 Before we jump in, tell us a little bit about yourself.
00:18 Yeah, definitely.
00:19 So I'm a data engineer, or at least at the moment.
00:22 I'm a byte trainee.
00:25 I'm a linguist.
00:27 So I'm debating both theoretical linguistics and computational linguistics.
00:31 So I'm really about how the information is encoded in our brains and how we share this information.
00:37 And that's why I work in the tech.
00:39 Nice.
00:41 Since I got my master's in computational linguistics, I worked at Amazon, at thelex.ai.org for a while.
00:50 The first worked as a language engineer, actually.
00:52 So I was more on the side of linguistic side of things and dealing with extracting the semantic and the meaning really out of the data for Electrophone.
01:03 And then gradually I switched over to just data processing and been in the role of data engineer for about three, four years now.
01:11 And I'm currently with Decafone, which is the worldwide sports retailer.
01:16 So I'm still working with lots and lots of data there.
01:19 Okay.
01:20 Wow.
01:20 Interesting.
01:21 That is fascinating.
01:21 Yeah, it's been right.
01:22 Yeah, it's really neat how we can speak to our devices these days and they kind of actually work, do amazing things, right?
01:31 Like I know when Alexa first came out and Siri especially, it was like, I don't really want to, that thing is so not getting it.
01:38 And now I talk to my devices all the time.
01:40 It's amazing.
01:41 Yeah.
01:42 There are some things that are really sophisticated that they haven't been doing now.
01:48 Sometimes I can't even believe where we're actually getting there.
01:51 So it's pretty exciting.
01:53 Yeah.
01:53 And sometimes I admit that, you know, in several things that they're like, really, you can't do it.
01:58 Yeah.
01:59 But I realized that having worked on that, actually, I realized that sometimes it's just kind of thing that, you know, like from a professional standpoint, it might seem like kind of trivial to me.
02:10 But I realized that, you know, there's so much work with things.
02:14 And then they say, I love the actual device.
02:16 But sometimes just like you, you, you don't get, you know, go over the little like corners.
02:22 Right.
02:23 So one of the things that I got to work at some point was actually helping Alexa kind of know when she needs to stop.
02:31 When she needs to stop talking about things and telling you about things like whatever she thought on Wikipedia or whatnot.
02:37 So, yeah, it's funny.
02:41 Fantastic.
02:41 So, well, for our first item, Michael, do you want to kick it off?
02:46 I will definitely kick it off.
02:48 Let's take it to the next level with this one.
02:49 So this is an article by Eluda called Take Your GitHub Repository to the Next Level.
02:56 And there's kind of 13 levels, but, you know, I guess it's a spectrum.
03:00 You decide which level you want to take it to.
03:02 So here are basically 13 ideas on how your GitHub repository can be better.
03:08 So there was a topic I was going to cover after I explored more.
03:11 I decided, eh, not so much.
03:12 But as part of it, there was a conversation about some WebAssembly stuff in Python.
03:17 And I checked it out.
03:18 It's really cool.
03:19 They're like, we're going to use this library.
03:20 This is the fundamental thing that makes it work.
03:22 And I go to the GitHub repo for that.
03:23 And it says, here's how you build it.
03:24 And that's it.
03:26 I'm like, wait.
03:26 OK, great.
03:27 But why do I want it?
03:28 What can I do with it?
03:29 How do I use it?
03:30 I don't care about how do I build it.
03:31 Like, that's the last.
03:33 I'll just download the WASM file.
03:34 But what do I do with it once I get it?
03:36 Right.
03:37 It was just none of that.
03:38 And so that's kind of, you know, this article helps you think through those ideas.
03:43 Nice.
03:43 So number one, and you know it's Python friendly because it starts with zero, step zero, rather
03:49 than one, make your project more discoverable.
03:52 Now, every one of these comes with a recommendation, a bit of a description, and then examples, which
03:58 is cool.
03:58 Nice.
03:59 So for example, this one says, what you can do is to help people find your project.
04:03 If the name of your project does not carefully describe what it is, you can put tags, basically.
04:11 So like refactoring or science or things like that might be something you put on there that's
04:16 not immediately obvious from it, right?
04:17 So you can tag subject areas and whatnot, and they have some examples.
04:21 So for example, there's this thing called Well app, which is like a mindfulness app for the
04:27 Mac.
04:27 Of course, it's for the Mac, isn't it?
04:28 So it has tags such as macOS, productivity, happiness, mental health, but also Flutter and
04:36 web app if people wanted to check out a Flutter web app, right?
04:39 Okay, so that's, you know, there's other examples as well.
04:41 That's step zero.
04:43 Step one is choose a name that sticks.
04:45 Something that's available on PyPI, something that people can Google, something that people
04:52 want to say.
04:53 It doesn't sound silly or unprofessional if they were to use it.
04:57 You wouldn't call your web app Fancy Pants Server, right?
05:01 You wouldn't say, well, our Fancy Pants Server is really scaling today.
05:04 Like, you wouldn't want to speak that way necessarily.
05:06 So don't name it that way, right?
05:07 Yeah.
05:08 So choose a name that sticks.
05:10 And that we can say on air.
05:11 Yes, exactly.
05:13 And is, you know, somewhat predictable in the pronunciation maybe because that's also a
05:19 challenge.
05:19 But so there's some examples of like...
05:21 Yeah.
05:21 Yeah, yeah.
05:22 Anna, what do you think?
05:23 Yeah, absolutely.
05:25 Just thinking about the name, something that I ran into today, particularly with Python,
05:30 some of the services or applications and libraries as well that help them.
05:36 And in PY, and sometimes you don't know if it's PY or P in that case.
05:41 It's like, you know, confusing.
05:43 And then you're talking to somebody else who's looking about the same thing.
05:46 They're like constantly confused.
05:48 So, yeah.
05:49 Yeah.
05:50 I agree.
05:51 It matters a lot.
05:52 Let's see.
05:52 So some of the things are conduct a thorough internet search for the name, avoid hard to
05:57 spell names, get the dev or .io domain if you really, really care about it.
06:00 You know, is it some random small little package or are you trying to create the next FastAPI?
06:04 Right.
06:05 A name that conveys some meaning.
06:08 I was thinking about Jupyter, for example.
06:10 Like, Jupyter is pretty interesting because it's kind of hard to spell.
06:13 But once you know it, you just know it.
06:16 And it very clearly works well in a search.
06:19 There's probably no domain name that's like a misspelled planet type of thing.
06:23 You know, I mean, it was probably a really good choice, even though it kind of breaks the
06:27 maybe hard to spell at first.
06:29 Yeah.
06:29 But it's easier to search.
06:30 Right.
06:31 So.
06:31 Yeah.
06:32 Yeah.
06:32 So the example they get for this one is size limit is the name.
06:35 And what does it do?
06:36 It calculates the real cost to run your JavaScript app or lib.
06:39 Keep good performance.
06:40 It'll show an error in a PR if the cost, basically file size, exceeds the limit.
06:44 That's cool.
06:45 The next one, I'm all about this.
06:47 Display a beautiful cover image.
06:49 So if you go to a repo and it's just the text, that's not amazing.
06:54 You want some color and you don't necessarily have to have like an amazing logo.
06:59 So they come back to this well app and it's just a W with like a little connection smile
07:04 or something under it.
07:05 One thing I did learn about this, though, that I thought was interesting.
07:08 Like, how do they center this image but not have it go all the way across the readme?
07:12 If you go to the readme and you actually look at it, apparently GitHub will let you put full
07:17 HTML inside of your readme for the segments that need lots of formatting.
07:21 I thought I thought they wouldn't.
07:22 I know some markdown does fall back that way, but I didn't think GitHub did.
07:25 Anyway, apparently, yes, you can.
07:28 Also, this one's quick badges like a CI passing.
07:31 What's the license and so on.
07:33 Is there a YouTube link to like a YouTube channel that shows people how to use it?
07:37 Some more of those as examples.
07:38 Write a convincing description in a paragraph or two.
07:41 Add things like, what is this repo or project?
07:44 How does it work?
07:46 Who will use it?
07:46 What is the goal?
07:47 And so on, right?
07:48 Real simple one.
07:49 And again, they come back to the size limit.
07:51 It's a performance tool that'll crash your CI if it's too big.
07:55 Here we go.
07:55 Getting to the ones that Brian and I love.
07:58 Port Visuals to attract users.
07:59 Yes.
08:00 So you might think there's no UI aspect, but here's a full-on CLI example.
08:07 That is create Go app CLI.
08:09 And all it does, imagine this, it creates Go apps on the CLI.
08:13 It's a good name that can base what it does.
08:16 But if you go to see, it's like, how do I create one?
08:18 It has the option, but then under it, it has an animated GIF doing the things that creates
08:23 the app and showing you the tree structure that results, the file structure that results and so on.
08:28 Then a full video and a documentation to that thing and so on.
08:30 So that's pretty awesome.
08:31 And how about you?
08:33 Brian and I are always trying to quickly jump into a project and figure out what is it about?
08:38 Is it polished and so on?
08:40 But that's because we run this podcast.
08:42 How do you see this sort of pictures and animations for repos?
08:47 Yeah, that's super helpful.
08:49 I really like the idea with the animation.
08:53 Just basically taking you through the kinds of things that this particular app, for instance,
08:58 can do.
08:59 That's super helpful.
09:01 More and more people are doing it.
09:03 I don't think it's super popular yet.
09:06 I don't know about how about you guys, but I haven't seen it for a lot of times.
09:10 Yeah.
09:12 But it, yeah, it definitely looks nice.
09:14 Yeah, I really like it as well.
09:16 All right, let's see.
09:17 Another one is create a practical usage guide, like how to use it with some examples, some
09:23 templates, answer common questions like an FAQ.
09:25 I use it on Windows or does it require admin support?
09:29 I don't know.
09:29 Something like that.
09:30 Build a community.
09:31 So maybe you have a, this is probably further down the line, but like, do you have a Discord
09:35 community for your project?
09:36 Or you can even just enable discussions on the GitHub repository.
09:40 I'll end up with people opening issues on my various repositories saying, I have a question.
09:45 Like, okay, a question's not an issue.
09:47 An issue is the thing that is wrong or a thing to be improved, but they don't have another
09:51 way to communicate traditionally.
09:53 But GitHub now has, in addition to issues, they also have a discussion section that's more
09:58 open-ended.
09:59 So I think that's off by default, if I remember correctly, at least on the older ones it is.
10:03 So I go and turn that on.
10:04 Code of conduct.
10:05 That's all good.
10:07 Contributor guidelines.
10:08 Choose a license, the right license.
10:10 Remember, if you don't choose a license at all, that means it's unlicensed and people
10:14 can't really use it.
10:15 So add a roadmap.
10:17 Create GitHub releases.
10:18 One thing that I didn't pull up that's pretty cool is release drafter.
10:25 I'm not sure if you all are familiar with this, but this is a pretty cool thing as well.
10:29 Release drafter.
10:30 Drafts your next release notes as PRs are merged into master or main, depending on how you set
10:36 up your repo.
10:36 That's pretty cool.
10:39 Customize your social media preview.
10:41 So if somebody shares your project, you can control what is shown in that little Twitter
10:45 card or other cards.
10:47 So apparently that that can be customized inside of your GitHub repository and launch a website.
10:53 Off it goes.
10:54 You can use GitHub pages or Netlify is really easy for easy and free for static sites and
10:58 so on.
10:59 So anyway, there's a bunch of things people can do to take their repo to the next level.
11:03 What do you think?
11:04 I think it's great.
11:05 Yeah.
11:05 I love this list.
11:06 It looks very nice.
11:07 I don't do any of these things and I probably should.
11:12 So I might have a picture.
11:13 I have a usage guide.
11:15 Oh, there's also one that talks about how to install it that I somehow skipped, but most
11:19 things don't need.
11:19 So one of the things that I see a lot is, I don't know if this covers it, but I see documentation
11:26 that's on read the docs, which is great, but I still think a quick start or a little like
11:32 this is how you install it and this is how you can do a little bit of something with it.
11:37 That should be in the read me, even if you have other documentation, because I don't
11:42 want to have to just go to the documentation to see if this is the right project for me.
11:46 So, yeah, this is great.
11:48 So we have a question of does, how does one create a CLI animated GIF?
11:55 And I don't know if the dot, if this article covers that, but I don't think so.
12:00 Okay.
12:00 We'll have to, we'll have to research that and get back to you.
12:03 Yeah.
12:04 Well, Alvaro, what I do is I'll use Camtasia and you can record a Camtasia video of just
12:11 the window.
12:11 And then there's different output options like just audio or just the video or an animated
12:17 GIF.
12:17 So that's one of them.
12:19 Jeremy Page points out there are a few tools to record that in a cinema.
12:26 I don't know.
12:26 Like ASCII cinema, basically.
12:29 I don't know how to say that.
12:30 It's often used pretty cool.
12:33 And Dean, hello Dean.
12:35 You know, the hook of names.
12:36 Exactly.
12:37 I'm at a loss on that one.
12:38 Claudia, who I just had on Talk Python, has a blog post about many of those things.
12:43 And he has a better for release drafter and badges.
12:45 Yeah, I covered that on Talk Python just recently about hypermodern Python.
12:49 Awesome.
12:49 Well, that's probably way more than people want to know about their GitHub repository.
12:53 But so often GitHub repositories these days serve as your CV or your resume when you go to apply
13:01 for developer jobs.
13:02 And if you end up at somewhere that looks like what they described here, rather than a bunch
13:07 of things with like weird commit messages and nothing like that's going to make a different
13:11 impression.
13:11 Or if you want people to adopt it and start using it.
13:14 Yeah.
13:14 And if you don't, then don't put this stuff in.
13:17 Yeah.
13:17 Exactly.
13:19 All right, Brian.
13:21 Let's go faster.
13:22 Well, let's go faster.
13:23 Speaking of CLI.
13:24 So this is a fun tool.
13:27 We're talking about faster row.
13:29 Faster?
13:30 I don't know.
13:30 Faster row.
13:31 I'm going to go with that.
13:32 So this is a time.
13:34 It's like time it on the command line.
13:37 So but it's pretty neat.
13:40 So this is by Arian Wasi.
13:44 And we've had we've covered something of his before.
13:47 So it was the type explainer thing.
13:50 Right.
13:51 I don't remember its exact name, but type explainer where you put a typed thing in there and
13:54 would humanize what those meant.
13:57 So I this is a simple little tool, but I'm loving it already.
14:01 So this one of the it does either it times stuff, but it also compares times.
14:07 So like in this, we're showing the website here, but and it I can't I can't tell what
14:15 they're timing.
14:16 So let's just pull over in the documentation.
14:19 It does have a bunch of examples.
14:21 So if you ran faster row with with two code snippets and in this example, we're showing
14:28 is just either just showing either a string or an F string timing those.
14:33 So that's pretty neat.
14:34 And those so those two code snippets.
14:37 If you run those, it'll run both of those a whole bunch of times and do some statistics.
14:41 Like in this example, it's running it 20,000 and 50,000 times.
14:45 No, 20 million and 50 million.
14:47 Wow.
14:48 And then it shows you a little progress bar and and then who wins.
14:53 But if you don't if you're not comparing two things, it'll just show one with the same
14:58 graphics, but you can do more than two.
15:00 I did like three or four just trying this out to time different things and compare them.
15:05 And this often that's why I'm timing something.
15:08 I'm comparing two things and I want to see which one's faster.
15:11 So this is a really cool feature.
15:13 You can either pass in code snippets or you can give it to Python file names and it'll
15:18 run both both those things.
15:20 One of the it's kind of a whole bunch of really cool features, actually.
15:23 And one of the things I like is you can if you've got some code snippet that you are
15:30 need some setup, but that the setup part isn't the part you're timing.
15:34 You can give it some setup code to do before it does the time part.
15:39 So that's pretty neat.
15:40 Anyway, just a really nice looking command line interface timing tool.
15:45 Yeah, that's very cool.
15:46 So you can sort of isolate the thing that you really want to time.
15:50 So you don't care about.
15:53 Yeah, I haven't tried the setup part, but it's cool that it has it in there.
15:57 There's there's a documentation is pretty thorough, actually, as well.
16:03 Quite a bit of cost customization available.
16:06 That's cool.
16:06 Yeah, I agree that that is nice that setup stuff, because so often if I want to profile
16:11 like some web app or something, it's the thing I want to profile is dwarfed by just loading
16:16 up the framework and scanning all the files.
16:18 And you're like, all right, now I got to hunt down that little fragment that actually represents
16:22 what I'm really after.
16:23 So cool.
16:23 Yeah.
16:24 Maybe I'll try one of those sometimes.
16:26 Yeah.
16:27 And you can pass in strings of Python or you can pass in files.
16:29 Yeah.
16:30 And when I saw the strings a bit, I'm like, all right, there's a good use case for semicolons
16:34 in Python.
16:35 Right?
16:36 You can use them.
16:37 Do it.
16:38 Yeah.
16:39 So.
16:40 Exactly.
16:40 It makes you feel better.
16:41 Awesome.
16:42 That's a good one.
16:43 All right.
16:43 Anna, on to you.
16:44 What's your first one here?
16:45 Yeah.
16:46 So I wanted to talk a little bit about, well, data, my line of business.
16:51 And I was just thinking that something that could be really interesting, especially for
16:57 that part of our audience that works with data science projects.
17:04 Well, in general, you're collecting data.
17:07 You definitely, in most cases, you get some kind of noisy data that you need to clean up
17:16 and filter out in some way.
17:18 And particularly, so I imagine we have a pretty large international audience as well.
17:24 And also, on the other hand, if you're working with data from social media, which is very popular
17:31 right now, one of the questions that you have to solve there is identify the human language
17:38 of the data that you're working with on content.
17:41 You want to filter out the pieces of data that are maybe, for example, are not an individual
17:46 if you're going through social media posts or something.
17:51 All right.
17:52 You get that little, translate this to your language, little button at the end, if for some
17:56 reason the popular post is in Spanish or something, right?
17:59 Exactly.
17:59 Yeah.
17:59 And some of the platforms, their APIs rather, do provide this kind of filtering on their backhand.
18:08 I know Twitter does that.
18:09 But also, as I know, sometimes it's not as reliable, really.
18:17 I guess maybe, again, like I could imagine that maybe it's not really sort of the ultimate
18:22 goal.
18:23 That's either maybe not putting as much love and caring to this question.
18:28 So that's something that I had to do a few times also.
18:32 And a couple of libraries that I've worked with are LANGID and LANGDETECT.
18:39 There are a few more out there.
18:41 And these ones have been out there for a while, actually.
18:46 And LANGID hasn't been actually sort of worked on actually for a few years now.
18:53 But it's still kind of one of those benchmark libraries for this kind of questions.
18:59 And both of those are super neat, actually.
19:03 So LANGID is really popular.
19:06 And one of the things that I really liked about it is that it actually covers a lot of languages.
19:11 So I've actually had different pieces of information depending on the documentation that I was using,
19:19 either at Hi-Fi or at the GitHub page.
19:22 So at some point, I saw it was covering 97.
19:25 And I think there did have pages saying 97.
19:27 97 is a lot of languages.
19:30 I couldn't name 97 languages.
19:32 I'm a linguist.
19:35 I would have trouble naming, you know, 97 languages off the top of my head.
19:38 I definitely don't speak 97 languages.
19:42 And some of the nice things about it is that you can use it as sort of like a standalone, you know, module,
19:48 like a command line tool, for instance.
19:50 But you can also use it as launched as a web service.
19:54 So that's really neat about it.
19:57 And some more like needy-free things that were really helpful when I was trying it out for some of my project was that
20:04 when you try to identify the human language using one ID, it actually outputs the weight and the calculations done,
20:18 which is very typical in like a log space.
20:20 So you have like these funky numbers in the end, you know, truly speaking.
20:24 But the good thing is that you actually can convert them to a bit more confidence force that especially a data scientist are used to.
20:32 And that actually comes in super handy because sometimes you, when you're trying to filter out the data
20:39 and you know that this kind of tools are like obviously not, you know, 100% reliable,
20:44 you can also use this confidence force to maybe use it as again as like, okay, I'm taking this answer and I'm relying on that.
20:53 Or, okay, maybe I'll just like drop this piece of data altogether because it looks like the language identified is not super actually sure.
21:03 Like what kind of language this is, you know, if you're targeting a specific language.
21:07 And another...
21:09 Yeah, this is wild.
21:10 Yeah.
21:11 So you get, you basically might say we're 80% sure it's English, but it might also be Spanish or something.
21:19 Exactly.
21:19 Yeah.
21:19 Yeah.
21:20 Like English can be easily confused with maybe German or sometimes French just to use it so much of the vocabulary circling around with those two languages.
21:29 So, yeah.
21:31 So the identifier is not going to be like 100% sure that, you know, this is language.
21:37 And the funny thing is that I'm not so sure about Lang ID.
21:43 Yeah, Lang ID is also statistical actually.
21:46 No remembering.
21:47 And so Lang Detect as well.
21:50 And sort of the flip side of that is that it actually works very well.
21:56 The bigger piece of data that you're fitting into it, the more confidence going to be.
22:02 Like, right?
22:02 That's how specific work.
22:03 Yeah.
22:05 That's how machine learning works, sort of generally speaking.
22:08 And if you're working specifically with this kind of short tweet, social media posts, if it's like really short phrase, sentence, interspersed with like emojis and stuff, it's probably not going to be super confident.
22:24 So the bigger piece of data, the more confident, the better the performance of the languages.
22:30 And there will be something to keep in mind when you're working on data and you're trying to filter it by language.
22:36 Yeah, that makes sense.
22:37 If you have one word or something, it's very hard to go off.
22:40 Yeah, exactly.
22:41 Yeah, exactly.
22:42 So this being one file, sorry, right.
22:44 This being one file is insane.
22:45 Like it acts as a web server and does all sorts of stuff.
22:48 Crazy.
22:48 This is crazy.
22:49 Yeah.
22:50 And it's something that I really like about it.
22:54 It's a pretty lightweight, sort of, well, isolated, low dependency kind of package, which is fascinating.
23:00 Based on a kind of not a super sophisticated, naive-based Helgern, if I'm remembering it actually correctly.
23:09 And so, yeah, that's really, really fun.
23:12 It's really nice.
23:14 It works so nicely.
23:15 And the other one that I wanted to sort of kind of juxtapose to it was Lang Detect, which is in my second tab.
23:24 I wanted to do a lot of things.
23:24 I wanted to do a lot of things.
23:25 I wanted to do a lot of things.
23:26 I wanted to do a lot of things.
23:27 I wanted to do a lot of things.
23:28 I wanted to do a lot of things.
23:29 I wanted to do a lot of things.
23:30 I wanted to do a lot of things.
23:31 I wanted to do a lot of things.
23:32 I wanted to do a lot of things.
23:33 I wanted to do a lot of things.
23:34 I wanted to do a lot of things.
23:35 I wanted to do a lot of things.
23:36 And it's also really neat and easy to use.
23:43 And the great thing about the basic usage is very straightforward.
23:48 It's like one of those packages you discover, like, you know, we need to do what's doing,
23:51 how it's doing it.
23:52 And, you know, like, you really can understand in five minutes if it's going to be something
23:56 that, you know, is going to suit well in my project when I put it.
23:59 Sure.
24:00 So the main methods are the text and the text language.
24:05 So you can either just call it in a piece of data and try and get the most probable language
24:13 that this package thinks it is.
24:16 Or you can have returned a list of possible languages.
24:22 So it's going to actually to order them.
24:24 English and then there's a fraction of probability that's going to be in the German or something
24:32 like that.
24:33 And then you can decide for yourself.
24:36 And yeah, so overall, from my experience, language is a little bit better than language, but that
24:45 sort of looks, you know, empirical.
24:47 Yeah, that's great.
24:48 It seems super useful for anyone that needs to parse text and can't be sure it's all in
24:54 one language.
24:55 Yeah.
24:56 So if anyone else is working on some kind of data science project or working with human
24:57 language data, I would highly recommend.
24:58 And probably one of the things while I think it's a little bit more confident and robust,
25:02 I know that it covers fewer languages.
25:03 So I think it's 55 languages total compared to 97 for language I do with it.
25:09 But yeah.
25:10 Yeah.
25:10 Interesting.
25:11 It's both great.
25:12 Nice.
25:13 Well, Michael, let me tell you about our sponsor for this episode.
25:16 Before we move on.
25:18 It's a podcast.
25:19 Amazing.
25:20 So this episode of Python Bytes is sponsored by the Python Bytes.
25:24 Compiler Podcast from Red Hat.
25:25 So everyone out there, just like you, Brian and I, we're both fans of podcasts, listening
25:31 to podcasts all the time and stuff.
25:33 That's why we started some.
25:34 We like them.
25:35 And so I'm happy to share a new one from a highly respected open source company, Compiler
25:38 Interactive.
25:39 And I'm a fan of the Python Bytes.
25:40 And I'm a fan of the Python Bytes.
25:41 And I'm a fan of the Python Bytes.
25:42 And I'm a fan of the Python Bytes.
25:43 And I'm a fan of the Python Bytes.
25:44 And I'm a fan of the Python Bytes.
25:45 And I'm a fan of the Python Bytes.
25:46 And I'm a fan of the Python Bytes.
25:47 And I'm a fan of the Python Bytes.
25:48 And I'm a fan of the Python Bytes.
25:49 And so I'm happy to share a new one from a highly respected open source company, Compiler,
25:54 an original podcast from Red Hat.
25:56 With more and more of us working from home or being more disconnected, it's important to
26:00 keep our human connection with technology.
26:03 Compiler unravels industry topics, trends, and things you've always wanted to know about
26:07 tech through interviews with the people who know best.
26:10 So on Compiler, you'll hear a chorus of perspectives from diverse communities behind the code.
26:15 These conversations include questions like, "What is technical debt?" "What are tech hiring managers actually looking for?"
26:22 "Hint, see item one to some degree." "And do you know how to code to get started with open..."
26:29 "How do you know how to code to get started with open source?" All right.
26:34 I was a guest on Red Hat's previous podcast called Command Line Heroes.
26:38 And that was a super produced and polished podcast.
26:41 It was a really cool experience.
26:42 And so Compiler follows along in that excellent tradition and that polished style.
26:46 So I checked out episode 12, how we should handle failure, which I found really interesting.
26:51 I really value their conversation about making space for developers to fail,
26:55 so they can learn without fear of making mistakes, you know, like taking down the production website and so on.
27:00 Right?
27:01 People grow through experimentation, but they also fail.
27:04 They try new things.
27:05 So you got to make sure that they get a chance to grow.
27:08 So learn about the Compiler podcast at pythonbytes.fm/compiler.
27:12 The link is at your podcast player show notes right at the top.
27:15 You can listen to it on all the places that you would think.
27:17 So thanks to Compiler podcast for keeping this podcast going strong.
27:21 And Brian, also just real quickly want to point out, I know people can just go to their podcast app,
27:27 wherever that's Pocket Cast or Overcast or whatever and type in Compiler and search.
27:31 But please visit pythonbytes.fm/compiler and there's a place to subscribe with all of your various podcasts destinations.
27:38 That way they know it came from us rather than just out of the ether.
27:42 So if you're going to subscribe or check them out, please do through that link just so people know.
27:47 Nice.
27:48 Yeah.
27:49 So how about we talk about watching some things like files?
27:53 Yeah.
27:54 We were listening.
27:55 Now we're watching.
27:56 We were listening.
27:57 Now we're going to watch.
27:58 But watch them for changes, not watch what they are.
27:59 So this one comes to us from Samuel Colvin of Pydantic fame.
28:04 So you know, it's a pretty cool experience behind developing this API.
28:09 And the idea is it's a simple, modern and high performance ways to watch files for changes.
28:16 So there's a lot of reasons you might want to do that.
28:18 You might want to say if somebody drops a file into this directory, I'm going to kick off a job to like load it up and process it in some kind of batch processing.
28:26 Or I want to have my web framework automatically restart if this, any of the files in here get changed, right?
28:33 Any of the Python files or whatever.
28:35 So you could use it for things like that.
28:36 But the modern part's pretty interesting.
28:38 So that's a good thing.
28:39 It hooks into the underlying file system, the underlying OS notification systems, and is done through, that's done through the notify rust library.
28:49 So basically it's a low latency, high performance, native, non polling way of watching the files.
28:56 And then just goes to the operating system and says, hey, I, in this directory tree, if anything changes, call the callback.
29:01 Nice.
29:02 That's pretty awesome.
29:03 Yeah.
29:04 So there's real simple uses here.
29:05 Like I can say from watch files import watch, and then just for changes in watch some path, then you can process those changes.
29:12 So here's an example of an app that just starts and its job is to, as things change here, take them up.
29:18 That might be an example of what I said about kicking off something over to like load it and parse it and decide what to do, and then maybe pass it to Celery for background work, right?
29:27 On the other hand, you might want to do other things while you're watching for changes as well in your app.
29:34 In which case there's also an A watch, an asynchronous watch.
29:39 So if you're doing other work and it's all asyncio based, here you can just say, kick off the watching bit and await for the changes to happen.
29:48 And then do other async processing like FastAPI or web or database calls, you know, web with HTTPX or database calls with Beanie or whatever other asyncio things.
29:58 And it's sort of less you run them in parallel, which is cool, right?
30:01 Yeah.
30:02 And if you want to go even further, you can kick off a separate process and say, start a process that will watch for changes here and then call back this function if those things change.
30:13 So that's pretty cool too.
30:15 There's all these different ways in which you can use it, but yeah, it's pretty neat.
30:19 It's based on this REST library and it seems pretty powerful.
30:22 There's also a CLI, which I did want to point out one other thing over here.
30:27 Like this, I thought this might impress you, Brian.
30:29 Definitely.
30:30 I can do a command line.
30:32 Watch files command that will say, watch this directory.
30:35 And if anything changes, rerun the failing tests.
30:38 That's very cool.
30:39 That's cool, right?
30:40 So you just do watch files and you run the string, pytest - - lf, which is pytest, rerun the failing tests.
30:46 If anything changes.
30:47 I think that's neat.
30:49 The, the command line stuff is actually cool.
30:52 I check it out just for the command line usage, but the ability to use it
30:57 programmatically too with an API, that's impressive.
31:00 And I'm, I'm very happy they included that.
31:02 Yeah, absolutely.
31:03 This is, if you're going to use it through the CLI, this is the perfect pip X install type thing, right?
31:08 Yeah.
31:09 pip X install watch files.
31:10 And it's not really tied to any of your projects.
31:11 It's just always there.
31:12 Anna, what do you think?
31:13 Yeah, but that, that looks super neat.
31:15 just made me immediately think about, file triggers that are one of the things
31:22 that it's built in mostly, or at least widely used in, you know, and, cloud storage as well.
31:27 Yeah.
31:28 And it's like, yep.
31:29 I can imagine like all the possible ways that it can be used.
31:32 So yeah, that's really neat.
31:33 Yeah.
31:34 I wonder if they, in their documentation, they actually provide any popular use features or anything.
31:39 They might not do that, but I'm curious if they actually do.
31:43 Yeah.
31:44 I didn't see any, any in particular, just a couple of examples on how you might use it and all, but yeah.
31:49 Yeah.
31:50 There's an older project called watch God.
31:52 I don't know anything about that one, but I'm glad I didn't learn about it.
31:56 Cause now there's a new one called watch files.
31:58 But if you use an old one, this is the successor to that as well.
32:01 It's a funny name, but I could see why some people might not want to use it.
32:05 So yeah, well, I can see item one, right?
32:08 Pick a name that people are willing to talk about.
32:10 Exactly.
32:11 Yeah.
32:12 Well, I want to talk about a new tool as well.
32:15 Coverage, not.
32:16 So hopefully all of us are familiar with coverage.py.
32:20 So it's maintained by Ned Batchelder, a really cool tool, but there's a new guy on the scene
32:27 and the new person on the scene is slip cover.
32:30 So slip cover.
32:31 And actually I heard about slip cover through the coverage.py Twitter account, which was interesting.
32:37 And so not surprising though.
32:40 Ned's a pretty open-minded guy.
32:42 Okay.
32:43 but, so slip cover is, is coverage, but it's, it's pretty new.
32:49 So some of these, commits that's just within the last week or so that things, this came in.
32:53 So there's a, it's still at like, I think the version is 0.1.1 or something like that.
32:59 you even just got a new one out this morning.
33:02 So why would you want to use something different?
33:05 Well, the big selling point of this is it's really fast.
33:10 It uses a different, a different process for, for getting the coverage information.
33:16 And it supposedly is only a 3% overhead, which, depending on your code coverage that probably
33:23 can be, can sometimes slow down your code, significantly.
33:28 and if you've got a really long running test suite, making it even 20% faster, but sometimes
33:35 coverage can make it like twice as slow.
33:37 so if, if you've got a five minute test suite that makes it 10 minutes and that's a little
33:42 painful.
33:43 So, this might be worth checking out.
33:45 It's quite a bit faster.
33:46 I tried it against flask, as an example and the flask numbers.
33:52 so flask is, they've got a pretty tight test suite anyway, but, so just straight
33:58 pie test on my machine.
33:59 It was like 2.7 seconds.
34:01 with coverage was, about four, 4.3 seconds.
34:05 and then with slip cover, it was just a little slower than just pie test.
34:09 So pie test 2.7 with slip covers 2.88.
34:12 So just a little tiny bit more and you get coverage information.
34:15 That's pretty cool.
34:16 it is in the early stages though.
34:19 There's some, there's some kinks to work out still.
34:23 So, I would try it out and watch this space.
34:25 I think they're doing some really cool things.
34:27 Definitely worth watching.
34:28 But, like for instance, I ran into issues on projects that use pie test plugins.
34:35 I don't know why, but the plugins don't get loaded.
34:38 So the, like for instance, I tried to run this, this flask example, but with xdist,
34:45 so that I could run all the tests in parallel to see if it's sped up parallel runs.
34:50 Also, it didn't recognize the parallelism.
34:53 So I'm not sure what's going on there, but I am in communication with, Juan, one
34:59 of the maintainers of this or, let them know what, what I found out.
35:03 I'm not just griping, and not trying to make it better.
35:06 I'd love to have this be a really cool tool.
35:08 So it looks neat.
35:10 Yeah.
35:11 Go ahead, Anna.
35:12 Yeah.
35:13 And so the data near zero overhead is mostly due to how they, managed to, to provide that.
35:20 we talk about the involved recommendations.
35:22 It's really interesting.
35:24 Yeah.
35:25 Yeah.
35:26 With such a little overhead, I'm tempted to think of a more diabolical use of it.
35:30 Like I've got, I'm handed some crummy old app that doesn't really have tests.
35:35 And I got to figure out, well, what part of this is dead?
35:37 Cause I don't know if you've ever picked up some old app that's evolved and evolved.
35:41 And there's just stuff people don't take out cause they're afraid to just run this in
35:45 production for a while.
35:46 Oh yeah.
35:47 And just go, okay, these things don't look like they're doing it.
35:50 I mean, there might be some case I need to track down, but this gray area over here,
35:54 that's not touched.
35:55 Let me look for things to delete over here.
35:57 That'd be kind of fun.
35:58 That's my favorite use of coverage is looking for dead code.
36:01 yeah, exactly.
36:02 before we move off this, Brian of our ass, does it have a pie test plugin?
36:06 I know you said it doesn't work to run plugins, but this is the reverse question.
36:10 I don't, I don't think so.
36:12 So you're running, you're running a slip cover and pie test at the same time.
36:17 I don't think you really need a pie test plugin for it.
36:20 it, I w it, it does run it work with pie tests.
36:23 So you can run a pie test, operations on with it, but nice.
36:28 Just not the bells and whistles yet.
36:30 Right.
36:31 but I'm sure they'll get there.
36:32 Yep.
36:33 I would love to sort of circle back to the data.
36:36 Great.
36:37 Sound like a perfect record, but that's my favorite topic.
36:40 No, it's great to have you on to talk about it.
36:42 Cause Brian and I don't live in the data science world.
36:45 Right.
36:45 So it's really cool.
36:46 Yeah.
36:47 well, you're, you're welcome in our, in our world.
36:50 There's a lot of fun stuff happening here.
36:52 And, well, actually if you think about it from the actual, the very beginning, right.
36:56 Even before trying to wrangle the data and trying to, for any interesting information
37:02 of the data, you have to get it somehow.
37:05 And, sometimes if you're like particularly working on some, sort of, side projects
37:11 on your own, and you, you want to maybe try out a new tool or maybe new, you can, if you're
37:18 doing like a, machine learning project on modeling approach, you usually need,
37:24 some very specific data to, to work on.
37:28 and how do you get through the data?
37:30 Well, you have to actually go and maybe find some examples of the data on your own.
37:34 And so something I wanted to talk a little bit today was, actually webclawing,
37:38 webclawing, webclawing and a couple of, tools for that.
37:41 so one that is, quite popular and it's actually like, industrial grade kind of tool
37:48 is, well actually either scrapey or scrape by as for both, variants.
37:56 Yeah.
37:57 and it is a pretty great tool.
38:00 so one of the great things that you're doing, you're doing, you're doing, you're
38:03 a great tool.
38:04 Yeah.
38:05 One of the great things like from the get go about is that, it actually has a built
38:09 in shell.
38:10 so you can just, go ahead and sort of try out things in the CLI, get response
38:16 from a URL for instance, and then try to, look around it and then test out it behavior,
38:23 which is really nice.
38:24 And then see what kind of things you might want from there.
38:27 and if you're actually, sort of go ahead and, and, and use it, for your,
38:32 for your module to, to acquire, to get some data rather, it provides all sorts
38:39 of, reunite functionality to begin with.
38:42 for instance, the choice between using other, there's a selectors for the, the, the,
38:48 the content of the pages or an expat, which is, obviously a little bit more flexible.
38:53 It's more flexible.
38:54 Yeah.
38:55 It's more fragile though.
38:56 Cause if they make any change to the page.
38:58 That also, yeah.
38:59 but so yeah.
39:00 Well, it's part of the game.
39:01 Yeah.
39:02 yeah.
39:03 And then, some other really nice things about it is that actually, they do a lot
39:08 of like heavy lifting for you in terms of translating.
39:11 So you can, there's, built-in methods for start project and you can, you know, run
39:17 that and right away you have the whole structure and by cost of the boilerplate, kind of code.
39:23 You just fill in the, certain pieces for, I can processing, which is in there.
39:26 I plan modules, you think some of the setting, et cetera.
39:27 And, there you go.
39:28 You know, I have like a huge amount of work already.
39:29 So it's, pre set for you, pre done candidates for you.
39:32 and then, some other nice things about it is that, also provide you with, like,
39:39 a, a, pre set for you, pre done candidates for you.
39:44 and then, some other nice things about it is that, also provide you with, like,
39:52 numerous choices actually for, exporting the data and for storing the data as well.
39:59 I mean, in a few places and the format that you would love to, to use for it.
40:04 but all the typical standard things like PSA, JSON, some more, some, some left frequent options.
40:13 Yeah.
40:14 Another thing that's pretty interesting about this whole project is that there's a web scraping as a service company.
40:21 Yeah.
40:22 Behind it. Right. It used to be called scraping hub. Now it's Zite, Z-Y-T-E.
40:26 Zite.
40:27 Yep.
40:27 And you can basically, you can basically go in there and just, you know, sign up and hand it one of these, these, spiders and it'll just run it on the different servers, try to avoid getting blocked, all that crazy stuff.
40:38 Exactly. Yeah. so, therefore it's so elaborate and they really put a lot of, just like I was talking before, a lot of, loving carrots, like all those sorts of, functionality, like covering all those corners of like what you might want from, it's a web crawling, tool. and some other examples that, I found particularly useful for instance, the link extractor class is like really getting to like reading.
40:55 You know, parts of the tool where you can, extract further links from the page. but don't need those ones that, you know, to hear to a particular pattern for instance. and the list that you get is already. so once again,
40:57 tool.
40:58 Some other examples that I found particularly useful, for instance, is the link extractor
41:05 class is really getting to need reading parts of the tool where you can extract further links
41:13 from a page, but don't use those ones that adhere to a particular pattern, for instance.
41:19 And the list that you get is already decouped. So once again, it's already
41:26 so much of the dirty work on your part.
41:30 So that's really great. And they do provide, actually, ways to interact with
41:36 the pages as well. There's a format class that you can use as it does provide some functionality where you can interact with the page,
41:44 but I haven't used it as much myself, so I can barely show how fascinating it is.
41:51 But it's probably well done as well. And another library that I wanted to touch on briefly
42:00 today as well was Robux. That's actually something new for MacBoss. That's
42:06 something I'm in the process of exploring, so I haven't had a chance to work a whole lot
42:14 with it yet.
42:14 But it's been really, really interesting, and I would love, I would be happy if, you know,
42:19 I got to hear from somebody else to write it out or something.
42:22 Because it, well, in the first place, it's still some type of HTTPX and beautiful soup,
42:30 beautiful soup 4, rather.
42:32 They're super popular in sort of the data processing line of work and particularly web
42:38 and web scraping.
42:41 But it adds some, you know, really useful functionalities, and it looks like it
42:48 allows even more of this interruption with the pages in a, like, very neat
42:54 and clean way.
42:55 And you can probably find examples where you're here in the documentation.
43:01 It looks so, you know, nice and clean and straightforward.
43:05 looks lovely.
43:06 So, yeah, I'm really excited about this package.
43:09 I'm hoping to have an opportunity to test it out soon.
43:13 Yeah, Roblox looks very interesting.
43:15 It looks very Selenium-like where you can actually control the page as well,
43:19 like, fill in this, fill in the comments with this, fill in the first name
43:23 with that, and then submit.
43:24 The other thing that's cool about it is it has async support for doing all those things.
43:29 Exactly, yeah.
43:29 You can scale it.
43:30 Yeah, that's fantastic.
43:32 Awesome.
43:32 Thanks.
43:34 Nice.
43:35 Well, where are we at now?
43:36 We have Extras.
43:38 Extras.
43:39 Extra, extra, extra.
43:39 Here all about it.
43:40 I only got one.
43:41 How many you got?
43:41 I got zero.
43:42 Zero.
43:43 All right.
43:44 And anything else you want to give a quick shout out to while we're here?
43:47 No.
43:48 No?
43:48 Okay, cool.
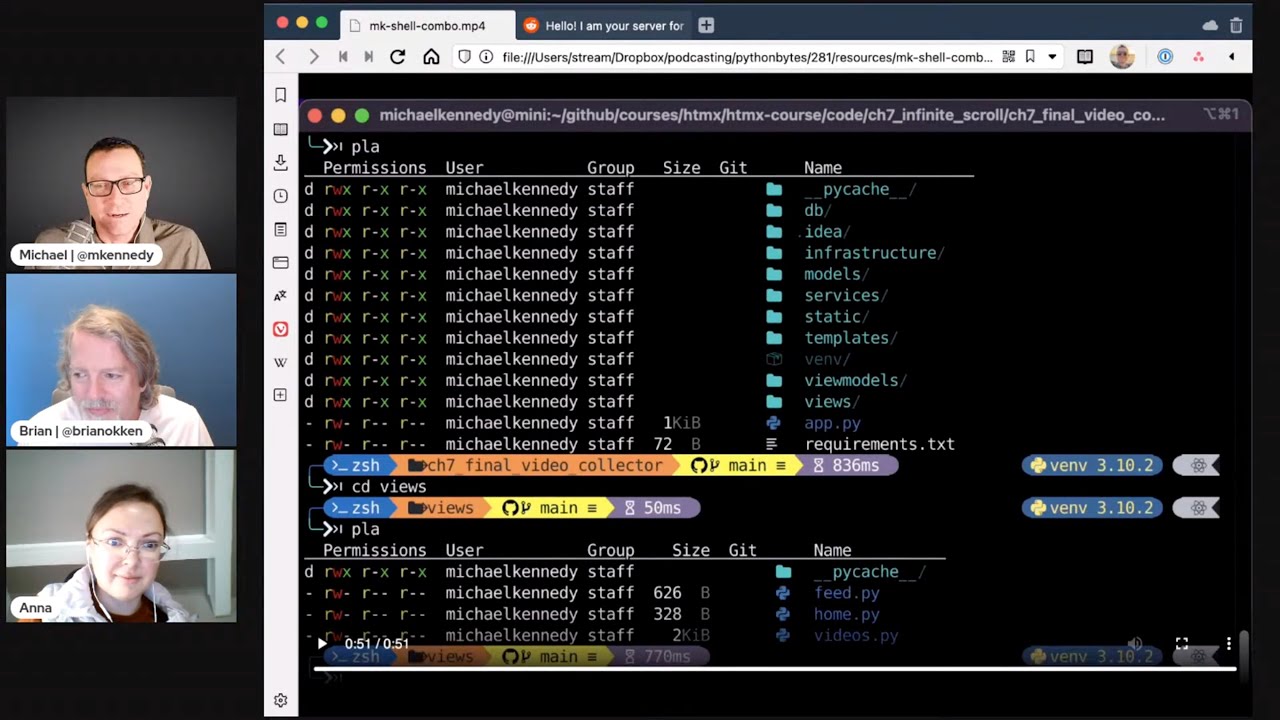
43:49 Well, I wanted to tell you all about my terminal adventures, I suppose we'll call them.
43:55 So I've been using Oh My Z Shell, which is amazing.
43:58 I love Oh My Z Shell.
44:00 But I also started playing with ohmyposh and Please and some of these other things.
44:05 And I thought, oh, well, how am I going to decide between say ohmyposh
44:09 and Oh My Z Shell?
44:10 Well, it turns out, Brian, you don't have to decide.
44:12 You get both.
44:13 So here's a little animated video I'll throw up for people who are watching
44:17 and I'll put it in the links as well.
44:18 So here's, you can see this cool prompt, which is all driven by ohmyposh,
44:23 but you can see like auto-complete into local Git branches through Oh My Z Shell
44:28 for either branch or checkout.
44:30 And then on top of that, we can do like PLS, which is amazing.
44:36 You can do, oh, and McFly.
44:37 We talked about McFly before, which gives you auto-complete into your history
44:40 and sort of a Emacs style editor type of AI complete.
44:45 Then PLS for LS replacement that is developer friendly with like little icons
44:51 for the file types and it uses Git ignore to hide stuff that you don't want to see.
44:55 And it's like Python friendly, like understands V and Vs and de-emphasizes them
45:00 and all that kind of stuff.
45:01 So anyway, people have been trying to decide between these things.
45:04 It turns out they all go well together.
45:06 You don't have to decide.
45:07 That's pretty cool.
45:09 Yeah.
45:09 Yeah.
45:10 Yeah.
45:10 I really go with VSH and that looks even, yeah.
45:14 Yeah.
45:14 All the stuff that works, you don't have to give up any of it.
45:17 The only thing that isn't there is the prompt and the prompt is not all that great,
45:20 honestly.
45:21 I mean, I know you can customize it, but I think it's better in ohmyposh,
45:23 which is pretty amazing.
45:25 So people who are listening, they can check out the little video.
45:28 I'll link to somehow find a way to do that in the show notes so you all can check it out.
45:33 Okay.
45:33 That's my extra.
45:34 Yeah.
45:35 Yeah.
45:36 How about a joke?
45:37 And I guess, how about a joke?
45:39 So we're all starting to go back out to dinner, restaurants, COVID's over,
45:44 I hear, not necessarily, but here's one from a slightly different perspective.
45:48 It says, hello, I'm your server today.
45:50 Brian, can you just describe for people listening what's in this picture?
45:54 there's two robots at a restaurant sitting down and there's a server rack
46:01 next to them.
46:02 Yeah.
46:03 Okay.
46:03 And the subtitle is when you go out for a bite, B-Y-T, he says, the server
46:08 is by the table where the robots are drinking.
46:10 He says, my name is D-H-X-005972 and I will be your server this evening.
46:15 I'll follow this one.
46:17 Thanks.
46:18 All right.
46:20 That's what I got for us for our joke today.
46:21 Nice.
46:22 Well, thanks, Anna, for joining us today.
46:26 Thank you.
46:26 Thank you for having me.
46:28 Yeah, it was great.
46:29 Thank you, Brian, as always, and everyone out there listening.
46:31 Thanks so much.
46:32 Very good on our own.



