#192: Calculations by hand, but in the compter, with Handcalcs
Sponsored by us! Support our work through:
- Our courses at Talk Python Training
- Test & Code Podcast
Brian #1: Building a self-updating profile README for GitHub
- Simon Willison, co-createor of Django
- “GitHub quietly released a new feature at some point in the past few days: profile READMEs. Create a repository with the same name as your GitHub account (in my case that’s github.com/simonw/simonw), add a
README.mdto it and GitHub will render the contents at the top of your personal profile page—for me that’s github.com/simonw” - Simon takes it one further, and uses GitHub actions to keep the README up to date.
- Uses Python to:
- Grab recent releases from certain GH repos using GH GraphQL API
- Links to blog entries using feedparser
- Retrieve latest links using SQL queries
Michael #2: Handcalcs
- Created by Connor Ferster
- In design engineering, you need to do lots of calculations and have those calculation sheets be kept as legal records as part of the project's design history.
- If they are not being done by hand, then often Excel is used but formatting calculations in Excel is time consuming and a maintenance nightmare.
- However, doing calculations in Jupyter is not any better even if you fill it up with print() statements and print to PDF: it just looks like a bunch of code output.
- Even proprietary software like MathCAD cannot render math as good as a hand calculation because it does not show the numerical substitution step. No software does
- Why handcalcs exists:
- Type the formula once into a Jupyter cell
- Have the calculation be rendered out as beautifully as though you had written it by hand.
Write your notebooks once, and use them for calculation again and again; the formula you write is the same as the representation of the formula.
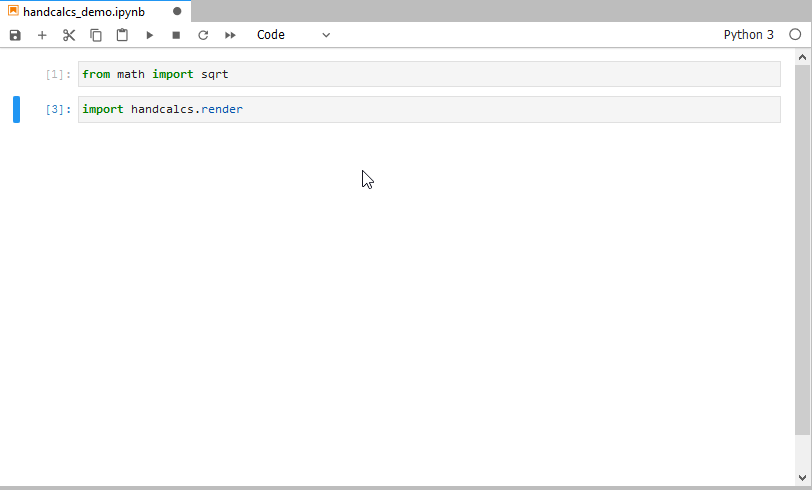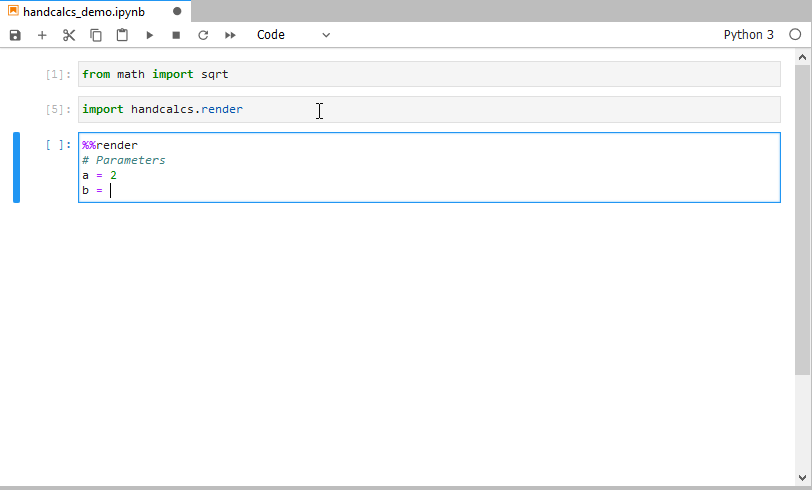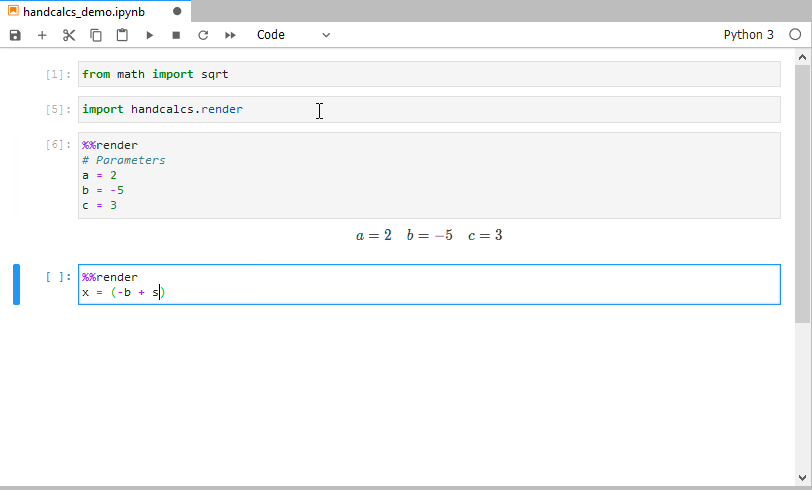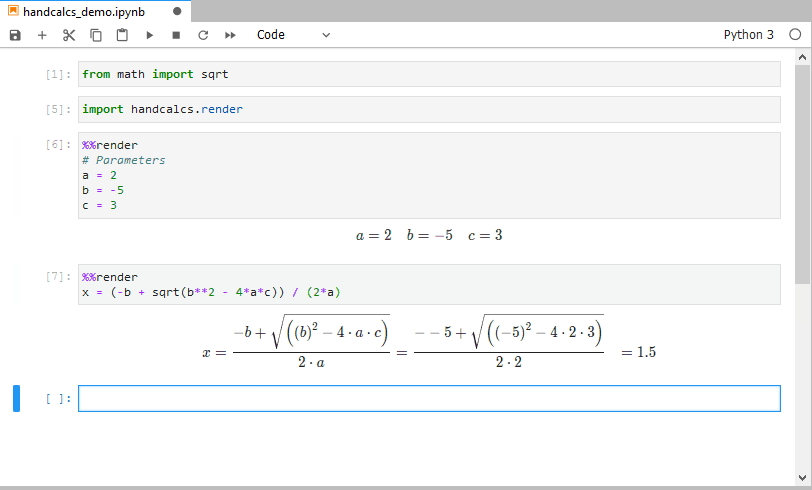
**Symbolic**The primary purpose ofhandcalcsis to render the full calculation with the numeric substitution. This allows for easy traceability and verification of the calculation.- However, there may be instances when it is preferred to simply display calculations symbolically. For example, you can use the
# Symbolictag to usehandcalcsas a fast way to render Latex equations symbolically. - Includes longhand vs. shorthand
- Use units (mm^3) for example.
Brian #3: The (non-)return of the Python print statement
- Article by Jake Edge
- Idea by Guido van Rossum to bring back the print statement.
- Short answer: not gonna happen
Michael #4: FastAPI for Flask Users
- Flask has become the de-facto choice for API development
- FastAPI that has been getting a lot of community traction lately
- Benefits
- Automatic data validation
- documentation generation
- baked-in best-practices such as pydantic schemas and python typing
- Running “Hello World” - super similar, but FastAPI is uvicorn out of the box
@app.get('/')vs@app.route('/')- FastAPI defers serving to a production-ready server called
uvicorn. URL Variables:
Flask
@app.route('/users/[HTML_REMOVED]') def get_user_details(user_id):FastAPI
@app.get('/users/{user_id}') def get_user_details(user_id: int):
Query Strings
- Flask
@app.route('/search') def search(): query = request.args.get('q')
- Flask
FastAPI
@app.get('/search') def search(q: str):Taking inbound JSON request in FastAPI:
def lower_case(json_data: Dict)Nice but if you define a
Sentencemodel via pydantic:@app.post('/lowercase') def lower_case(sentence: Sentence):Blueprints == Routers
- Automatic validation via pydantic
Brian #5: Tweet deleting with tweepy
- Chris Albon
- A useful and simple example of using tweepy to interact with Twitter
- Chris set up and shared a Python script that deletes tweets that are:
- older than 62 days
- have been liked by less than a 100 people
- haven’t been liked by yourself
Michael #6: Clinging to memory: how Python function calls can increase your memory usage
- by Itamar Turner-Trauring
- I had Itamar on Talk Python episode 274 to discuss FIL which was recently covered.
- This article basically uses FIL to explore patterns for lowering memory usage within the context of a function.
- With simple code like this, we expected 2GB of memory usage, but we saw 3GB:
def process_data(): data = load_1GB_of_data() return modify2(modify1(data))The problem is that first allocation: we don’t need it any more once
modify1()has created the modified version. But because of the local variabledatainprocess_data(), it is not freed from memory untilprocess_data()returns.Solution #1: No local variable at all
return modify2(modify1(load_1GB_of_data()))Solution #2: Re-use the local variable
data = load_1GB_of_data() data = modify1(data) data = modify2(data) return dataSolution #3: Transfer object ownership
- See article
Extras:
Michael:
- Pickle Use Example via Adam.
- I once had to work on an API that spoke to a 3rd party service that was a little unusual. That communication to the 3rd party service was over a raw socket connection, so we were responsible for crafting specifically formatted byte arrays to send to them, and we'd get specifically formatted byte arrays back which we'd then have to parse out to determine what pieces of data were in the message. The other wrinkle: that service wasn't available 24/7 but only during limited specific testing periods which had to be negotiated days in advance.
- We instrumented the code with a feature flag to enable pickling all received messages from that 3rd party service.
- Python 3.8.4 is out
- I'm an Arctic Code Vault Contributor over at GitHub. You might be too.
Joke:

Episode Transcript
Collapse transcript
00:00 Hello and welcome to Python Bytes, where we deliver Python news and headlines directly to
00:04 your earbuds. This is episode 192, recorded July 22nd, 2020. Had to look that one up.
00:13 I am Brian Okken. And I'm Michael Kennedy.
00:15 And I can't believe we're heading close to 200. This is crazy.
00:18 Oh yeah. Been at this for a while. That's going to be like four years almost.
00:21 Yeah. Again, this episode is sponsored by us and we'll tell you a little bit more about
00:26 other things that we're doing a little later in the show. But first, some of the ways that people
00:32 tell each other what they're up to is their personal GitHub readme on their GitHub profile,
00:38 right? Yeah, that's right.
00:39 So I was impressed by something that I saw recently. Simon Willison, he's the co-creator of Django.
00:45 He posted something called a blog post saying how to do a building a self-updating profile readme
00:53 for GitHub. So at the top of it, I'm going to quote this. It says, GitHub quietly released a new feature at some point in the past few days.
01:01 Profile readmes. This is news to me.
01:03 Yeah. So if you create a repository with the same name as your GitHub account.
01:07 So in Simon's case, it was Simon W. So github.com/Simon W slash Simon W.
01:15 So two, you go too deep and then add a readme.md or readme markdown file to it. GitHub will render
01:22 the contents at the top of your personal profile page. So that's neat. In that case, it's just one
01:29 up. So if you go to github.com/Simon W, you see his, but his looks really awesome. It's got a whole
01:34 bunch of cool stuff in it because he took it one step further. It's not a static markdown file.
01:41 He's got another article that talks about it, but this article here walks through exactly what he
01:46 does. And also it's all open source. So you can see his code. He uses a GitHub actions. There's
01:53 both a button that he can push to make it happen, but there's also any post to his own Simon W repo
02:00 will cause this to happen. But the GitHub actions run, he contributes to a lot of open source
02:06 projects. So he takes a certain set of repos that he has and pulls the latest releases and have like
02:13 latest release notes using the GitHub GraphQL API. So there's an example of that. There's an example
02:20 of using feed parser to pull blog entries off of his blog and an example of using a SQL query to grab,
02:27 guess he's got a site called TAIL for today. I learned grabs a few links off of that. So he's
02:33 got a three column setup for a read me that is kept up to date using GitHub actions. How cool is that?
02:39 That is awesome. Yeah. So normally you go to your GitHub repo and you have your picture
02:44 on how many followers you have and whatnot. Some other cool stuff we'll talk about later,
02:49 but then has your pinned repositories and that green ish heat map of how frequently you contribute to
02:56 various projects or just to get up in general. But now you can have right at the top, you know,
03:02 whatever you want to write, which that's pretty awesome. I think I might have to do this.
03:05 Yeah. I mean, you still get all that other stuff, but it's just that other stuff is below
03:10 this read me info. That's pretty neat.
03:13 Yeah. Very cool. And it's super simple, right? Anyone can write a readme.md file.
03:17 Yeah. And one of the reasons why I brought this up is I think there's a lot of people trying to
03:21 utilize, I mean, this day of COVID and quarantine and stuff, I'm glad I'm not looking for a job.
03:27 And I think that if you are looking for a job, making your GitHub profile look professional
03:33 and show the content that you want to show off and having things like, you know, blog posts on
03:39 your GitHub profile, that's pretty cool. It is really cool. And just, you know, you know that people,
03:43 employers say they check people's GitHub profile accounts, right? So how many people have, are going
03:49 to have these unique special ones that show they care, right? Not too many.
03:52 Well, the people that listen to our podcast.
03:54 Exactly. Yeah.
03:55 All the awesome people. Okay. So that's really cool. I definitely didn't know about that. Thanks for
04:00 sharing that. It looks neat. So we got this next one from Connor Furster and he works in engineering,
04:07 but also does data science-y things. And he sent over this project that he works on that is incredibly
04:14 cool. So a lot of times what people want to do is they want to take symbolic math or math that you
04:21 might write out by hand, turn it into Python code through pandas and numpy and whatnot, scikit learn
04:26 or scikit in general, and then run it through Jupyter and get an answer. But he says he works in design
04:33 engineering and you have to do a lot of calculations and those have to be kept as part of legal records
04:39 to show the project design history. And one, yeah, one thing you do is do them by hand. That's kind of
04:47 crazy. A lot of people use Excel. That's a nightmare. Like Excel is like unbounded go-to's you can't see,
04:53 which is always tricky. So you could do it with Jupyter, but then you just got this pile of code
04:58 and here's the answer and so on. Right. So you want to like the theoretical view to verify the formula
05:04 you're using. Right. So he created this thing called hand calcs and C-A-L-C-S like calculus or
05:12 calculations. Anyway, hand calcs. And the idea is you type in Python code into a Jupyter cell,
05:18 and then you can do a percent percent render from the hand calcs project and it will turn it into
05:25 symbolic math. This is beautiful. Yeah. As if you had written it out by hand. Yeah. With like,
05:30 as an example in the little video demo, we've said before we like those and everybody does,
05:36 but it has, has like square root symbols with a bunch of symbols underneath it and
05:41 all sorts of symbols that, yeah. Yeah. Looks like, like what you would have had to show if you were
05:46 in math class, right? Yep. Exactly. And it will show steps like symbolic steps from step A, step B,
05:51 step C. And you can say, show it shorthand or expand it out longhand and show me all the steps you
05:56 use to like solve these problems and all kinds of cool stuff. Wow. Yeah. The reason it looks so good
06:01 is it basically converts symbolic Python math over to latex and latex is like the de facto math
06:11 representation language for academic papers. So, you know, you want to have like integral signs,
06:16 you want to have infinite summations, all that kind of stuff. No problem. Oh, this is really cool.
06:20 Isn't it cool? And then you can also use the symbolic tag to get it to do other, like show more
06:26 symbolic stuff. You can do longhand, shorthand, you can have it do units. They'll put units like
06:31 millimeters cubed or whatever, and it'll carry the units through the calculation in symbolically.
06:36 Yeah. But looking at all these formulas, it's giving me nightmares. Don't look anymore. Okay.
06:41 Well, I guess the thing you would, you would want to think about the trade-off is would you rather
06:47 look at them in their proper mathematical form or in like programming meaning, not, you know,
06:54 where you turn it into like star star pow instead of, you know, proper exponents and stuff.
07:01 No, no, I was just kidding. This is beautiful stuff. But when we got into integrals, that's
07:05 where basically that's where my brain left and I never really caught integrals that way.
07:10 Yeah. Yeah. Cool. All right. So if people have to take programming math, but they want to represent
07:17 it more nicely, check out handcaps. Looks awesome.
07:20 Yeah. Nice. Oh, I'm next.
07:23 Actually, I'm not. I'd like to talk to all of us about our sponsor and our sponsor is a
07:30 Talk Python Training and a testing code today.
07:34 Tell me about Talk Python Training.
07:36 I'll tell you about what I'm working on this week. I started writing a new course.
07:39 We have a couple of new courses that are fun that are coming. And the one that I started working on
07:43 is called Python memory management and tips.
07:46 Tell me more.
07:47 Yeah. So if you ever wondered, like, what happens, like, how does it free up memory?
07:50 What algorithms make, like, work better with Python memory and what algorithms can make it
07:55 more expensive or slow? What are some of the tips and tricks you can do to, like, dramatically
08:00 decrease the memory consumption, like, two or three times with almost exactly the same code
08:06 type of thing? Well, I'm writing a course on that.
08:09 Oh, that's neat.
08:09 Yeah. Thanks.
08:10 Especially for people, like, talking about doing some more, we can get Python on smaller
08:15 operating system.
08:17 Yeah.
08:17 Architectures like CircuitPython and stuff. That's important.
08:20 Yeah. That's a really good point that on the small memory constraint pieces, you might care a lot
08:25 for sure.
08:25 Yeah.
08:25 How about testing code?
08:26 Well, I was interviewing somebody recently, David Lord. His actual interview will come out sometime
08:33 in August. But he said, I was looking at testing code and a lot of the recent episodes really haven't
08:39 been about testing. What's up with that? And I said, yeah, it's and code, test and code. But yeah,
08:45 so there is a lot of testing focus because primarily because I think that software engineering doesn't
08:52 talk about testing enough. But I do cover a lot of stuff. I'm going to highlight a few of the last
08:58 episodes. I talked to Sebastian Ramirez on episode 120 about Fest API and Typer. Talked with Brett Cannon
09:06 on episode 119 about packaging and pyproject.toml and what's going on there. 121 is a diversion. It's a
09:14 completely different sort of talk. I talked to somebody about 3D printing and finite state machines
09:20 and stuff. And it's just sort of a fun people doing Python and cool things.
09:25 Very cool.
09:25 And then again, talking, thinking about people possibly looking for jobs in episode 122, we talk about
09:32 better resumes for software engineers. So there's, yeah, there is a lot of stuff for everybody. Even
09:37 if you cringe when you think about testing, please check out testing code. We are still putting out
09:43 episodes. If you want to hear more, I'd love to hear what people want to hear about.
09:46 Yeah. It makes our job so much easier when we get suggestions.
09:49 Yeah. Suggestions and questions and things that can flow into things.
09:52 Yeah. Like a suggestion to return the print statement so you don't have to put the parentheses.
09:57 Yeah. So this is crazy and I don't really have much of a comment here, but I saw the thing by Guido
10:03 and then I saw this article by Jake Edge on LWN.net. I don't know what LWN stands for, but it doesn't matter.
10:11 Anyway, the non-return of the Python print statement. So this is odd, I thought. We have talked about the new
10:19 peg parser in Python that's going on. But one of the things that happened with that is, I guess, one of the reasons
10:26 why Python 2 to 3, they went from a print statement to a print function was it made the parsing easier.
10:33 But with the peg parser, you can do all sorts of crazy things and you can have functions that syntactically look like statements
10:41 and have it work just work, sort of. So as an example, we could use a print statement instead, instead of having to be, put the
10:51 parentheses in, you could avoid the parentheses. Anyway, he just put it out there as an idea and essentially people said, no, yuck. What do you think about this?
11:02 It's interesting. It would be one fewer things that has to happen to move to the next stage from a 2 to 3 conversion.
11:09 On the other hand, this looks like one of the easiest conversions for that step. To me, I'm not a fan of having statements and functions in the language
11:18 because it looks to me like functions basically solve the same problem with a little more
11:22 clarity.
11:24 They're a little more functional. You can span the multi-line if the arguments are super long
11:28 that you need to.
11:29 Like with the print statement, you'd have to use a continuation backslash and other weirdness like that.
11:34 So, you know, just because you can doesn't mean you should.
11:38 I guess that's probably how I feel about it, but I wouldn't use it if it were in the language. Let me put it that way.
11:43 Yeah, I'm for the no yuck camp. I think that print statement shouldn't have been a statement in the
11:50 first place. And then I think Python 3 fixed it. Having it be a function is the right thing to do.
11:54 I wish there were more statements that were functions instead. Also, I think I wish assert was a function
12:01 instead of a statement. Because people doing, thinking that it's a function and putting a parentheses
12:06 around assert causes problems. But that's not what this is about. It's interesting. I brought it up
12:12 because people should know about this weird, wacky discussion.
12:16 Yeah, that's funny.
12:17 I'm glad that it got thumbed down. And I don't think it's going to happen.
12:20 You're willing to make a statement about it?
12:21 Yes.
12:22 All right. Well, I'm going to make a statement about Flask. I think Flask, you just had David
12:29 Lord on the show, right? That's not out yet, but pretty cool. Yeah. And he's lead maintainer of
12:34 Flask these days. So Flask is, at least at the API level, got to be the most popular web framework
12:41 there is. Because it's slightly more popular than Django if you look at some of the recent surveys.
12:46 But if you look at the other frameworks, many of them are Flask-esque, if you will, right?
12:52 Yeah.
12:52 Things that are like Responder or Cynic or whatever. They have this idea of like sort of the same style,
12:59 right? So there's an article called FastAPI for Flask users. And I'm actually a big fan of
13:05 FastAPI. I'm hoping to have some opportunity to use it soon. Like the APIs that I've worked on,
13:12 they've been around for a while, they predate FastAPI. And I don't really want to go create a whole
13:16 new site just so I could use a different framework. That sounds like maintenance to me. So I haven't
13:21 got a chance to use it in production yet, but FastAPI looks awesome. So there's an article called Fast
13:28 FastAPI for Flask users. And it says, look, you probably know the Flask API. Here is the equivalent
13:33 for FastAPI.
13:35 Okay.
13:36 Yeah. And so there's talk about some of the advantages and they're pretty awesome. So automatic data
13:42 validation in FastAPI doesn't exist in Flask, generally speaking. Automatic documentation generation,
13:50 built in best practices like type annotations and Pydantic scheme schemas and whatnot.
13:57 It comes ships or recommend, I guess, as terms of like a requirement, you have to have a ASGI server.
14:05 So it comes with UVicorn, which is one of the, it's like Gicorn plus uv loop for async stuff.
14:11 And in a lot of ways, it's super similar. So if you want to create a view method instead of
14:16 app.route, you would say app.get. And so FastAPI, would you imagine the name indicates it's
14:23 mostly for building APIs?
14:24 Yes.
14:25 All right. So when you talk about functions and what they're going to do, you say not just
14:30 here's a URL, but here's a URL and an HTTP verb. So app.get forward slash or app.put slash account
14:39 or something like that, which is pretty cool. In the route, you can specify variables. So in Flask,
14:44 you would, you could have a user ID and in the string route, you would say int colon user ID. If
14:51 you want Flask to convert that to an integer, right? It's fine. It works. Okay. But that the rest of the
14:56 tooling doesn't help you know it's an integer just because Flask knows it's going to be an integer,
15:01 right? So in FastAPI, you put the variable up there as well. But then in the function,
15:07 you put the variable name as a type, and then it will actually convert that to an integer using the
15:13 Python language tools or specification rather than the string API thing. So that's handy. If you want a
15:22 query string in Flask, you just have a URL, you can go to request.args, and you can get the value out of the
15:27 query string. In FastAPI, you just put the query string values, or sorry, the keys as arguments, and they just get
15:34 passed in. That's pretty cool. Yeah. If you have a API that takes a JSON post, like, you know, it's
15:41 accepting a JSON document, you can just say it takes a dictionary, and that gets posted in. But you can go
15:46 way, way further, which is awesome. You can define a Pydantic model, which is a class that has types
15:52 and validation on the class, right? Yeah. And then you can say my view method or my API method takes,
15:58 like in the example they have is a sentence that has got like various components, nouns, verbs, and
16:03 whatever. You can say, here's a function, and it has an argument called sentence, and it'll take that JSON
16:09 document, parse it into the Pydantic model, and pass it to you pre-validated.
16:14 That's definitely one of the benefits of FastAPI is this data validation.
16:19 Yeah, this data, this is like built-in data validation, because how much, how many times
16:24 do you spend like effort, oh, I got a string, but I got to convert it to an integer. I got to make
16:29 sure that this value is here. I got to make sure that this one is, you know, like, whatever, like it
16:33 matches some, some set of sub strings or whatever. Just let, let the framework handle it. It also has
16:39 the equivalent of blueprints, which it calls routers, and this automatic validation I talked about. So
16:43 anyway, there's a nice article that says, you know Flask, let's teach you FastAPIs real quick by just doing a
16:51 this equals that.
16:52 Yeah, I love this, because there's a lot of people that have been writing APIs in Flask for a long time. And so it's
17:00 just second nature to them. And having something to say, hey, I want to try FastAPI, but is the learning curves going to be
17:06 a problem? Well, with something like this is decoder ring. And it is set up for, you can just sort of skim
17:12 through and go, well, how do I do URLs? Oh, this is, this is how you do it. And URL variables and
17:18 different things. It's set up really nice.
17:20 Yeah. Yep. Definitely fun. Definitely useful.
17:23 So do you use Twitter?
17:24 I do use Twitter. Sometimes happily. Sometimes I get dragged into stuff. Sometimes I use it in write only
17:31 mode where I want to make a statement, but I don't really want to go read it. But yeah, definitely.
17:35 Yeah, well, I have a, this is probably common, sort of a love-hate relationship with Twitter. I use it a lot
17:42 and like keeping track of other people. But sometimes I don't really like that it's a pain to delete old
17:49 stuff. Because I think of it as a current conversation. I don't really look at what somebody wrote a year
17:55 ago. And I don't really care what I wrote a year ago. So I have used Twitter deletion tools before.
18:03 They seem kind of weird that I have to go out and give my credentials to some other website or
18:09 something though. So, but I know.
18:10 I'm sure that'll be fine. It'll be fine. Don't worry about it.
18:13 Yeah. Anyway, but there's APIs. So you could use the Twitter API, but how? And so I thought it was
18:20 really cool that Chris Albin is somebody that tweets about data science a lot. And he posted a little
18:27 snippet that he said he uses. At least he did it first at one point. But it's a cool little example
18:35 of using a library called Tweepy to interact with Twitter and to delete old tweets for your account.
18:44 So it's just this really short little Python script. But it deletes tweets. There has defaults, but you
18:50 can change those. Obviously, it's just a Python script. So you can change whatever you want.
18:55 But it's set up to delete tweets that are older than 62 days and that have likes less than 100 people
19:02 and that you haven't liked yourself. So the idea being, if you go through some of your old tweets
19:10 and the ones that you're like, oh yeah, that was cool. I want to keep that around. Just like it,
19:14 like your own tweets and then run this script and it'll delete some old stuff. I would definitely
19:20 have to change that 100 count to something else because I don't think I've ever had a tweet liked
19:25 by 100 people.
19:25 That's a big number. You know, Twitter used to show how many tweets you actually had.
19:31 And I don't think it shows it anymore on my profile. At least I don't see it immediately.
19:35 How many tweets I had just followers and following and likes and stuff like that. But yeah, pretty cool.
19:43 It's like keep the highlights, right? Just keep my highlights. I don't need every random thing of,
19:49 oh, I went on, had a hamburger today. People don't need that as a piece of history.
19:54 Yeah. So when, and you don't know what's going to stick and what's going to not. And I was actually
19:58 reading an article recently about, about Twitter, about how that, what that says to you. If somebody
20:04 like, for instance, you're trying to get a job and somebody looks at your Twitter account, having the
20:09 junk in there that like nobody really related to having that automatically called out and just having
20:17 the highlight reel, that's not a bad idea for some of the old stuff.
20:20 Yeah. And you could turn it way down. You could say, look, if there's no likes or no retweets,
20:25 just drop it. Yeah. Yeah. It might even be good for me to like, just to go back a couple of days,
20:30 but if nobody's liked it in a couple of days, maybe just take it away.
20:34 That didn't happen.
20:35 Yeah. That didn't happen.
20:37 So people could end up clinging to their old tweets, but they probably shouldn't.
20:42 Right.
20:42 Yeah. So I want to talk about an article by Itamar Turner-Trowing. Now we spoke about him,
20:50 sort of, not by name, I don't think, but we talked about Phil, the data science memory
20:55 profiler a little while ago.
20:56 Okay. Yeah. Right.
20:57 So he's the guy who wrote that. I actually had him on Talk Python on episode 274 as well,
21:03 talking about that. So that was pretty cool. But he, independent of that, he wrote this article
21:07 that I came across that I liked called Clinging to Memory, How Python Function Calls Can Increase
21:13 Your Memory Usage. And this is part of my research for working on that course that I was talking about,
21:18 that memory, Python memory management stuff.
21:21 Okay.
21:21 So he talks about like, hey, we're going to have this thing. It's going to load up some NumPy data
21:26 and then it's going to pass it to a function. The function is going to make some changes,
21:31 take the return value of that, pass it to another function. It's going to make some more changes.
21:35 So basically three steps and said, look, we'd expect that we've loaded two gigs of memory.
21:40 And yet when you run Phil against it, you end up with three gigs of maximum memory usage,
21:45 which is a little bit weird. And the reason is those initial like intermediate values that you're
21:51 working with on step one and step two, the way Python decides a variable goes out of scope
21:57 is in this case, the function returns, not like it's never used again, but it's just the function
22:04 returns. In which case it's going to hang on to all the intermediate copies all the way to the end.
22:10 Interesting.
22:10 Right? Like some languages, they determine that and they get rid of it. Like in C#,
22:16 the JIT compiler will notice like, okay, a variable is not used after half the way. So we're going to
22:22 make it eligible for GC basically, unless it's in debug mode, then keep it around in case somebody
22:27 sets a break point. They want to see it. So there's a lot, a lot of the tricks that things can do.
22:30 Python doesn't do them. So it's going to stick around for this length of the function. So what can you do to make it not stick around as long? Because maybe
22:39 you only have two gigs and you don't want to use three gigs or whatever. Right? So he talks about
22:43 three different solutions. One is to don't hold onto the intermediate variables and just chain into
22:48 one massive function call, like pass the results of one to two to step two, pass the results of step
22:54 two to three. And there's no variables holding on. So it'll be gone. Right? That's an option.
22:59 Another one is to iteratively change the variable, say like data equals load data from first step.
23:06 Data equals step two of processing of data. Data equals step three of processing of data. And that
23:13 way you're dropping the reference count to the first, to the intermediate steps along the way.
23:20 Right? So that's an option. And then there's a third one that's more complicated about creating
23:24 like a sort of a ownership management type of thing that people can check out as well. But I just thought
23:29 it was interesting to think about, you know, when, how long do these things stick around and what
23:33 techniques might you use that are incredibly simple? Like just reuse the variable name, problem solved
23:39 in terms of having too much memory usage.
23:42 Interesting. Yeah. When I look at these, they all look kind of like the same, but having,
23:46 having the answer be that they, they use different amounts of memory is not obvious.
23:50 Right. It's not obvious at all, but it's, you could easily look at this one where you're iteratively
23:55 changing the variable and say, Oh, you shouldn't do that. You should name it more clearly. Cause
23:59 maybe the type is changing along the way and it would be weird, but you could say, yeah, but
24:04 this one works cause it will fit into Ram and the other one won't. So we're willing to accept this
24:10 like slightly imperfect code because it works better. Anyway, there's a lot of interesting trade-offs you
24:17 can make here, but I just, it's, it's only the tip of the iceberg for things like this you could do,
24:21 I think, but it's interesting to just put it on your radar.
24:24 Yeah. Yeah, it is interesting. Yeah. And actually, and like we said, I think that more and more as we
24:30 start using Python for other applications or non desktop kind of things, like when we're
24:36 a non-server things, if we're using it for, there's a couple ends of it. If you're using
24:41 small devices, like in circuit Python or something, you're going to care about this stuff. But also if
24:47 you're using very large data sets, then we care about it again. And, it doesn't matter how much
24:53 memory your computer has having multiple copies of gigabytes of data when you don't have to,
24:59 will slow things down. Yeah, for sure. Or even if it's like an API and you just happen to be doing,
25:04 it's not that extreme, but you happen to be doing a thousand of them at a time. Same story.
25:09 Yeah, exactly. And as we use Python more and more and more applications, we're going to start caring
25:15 about that again. Yeah, absolutely. That's the end of our six. I actually have been just so swamped
25:21 with stuff. I don't have anything extra to talk about. Do you have any extra items?
25:25 I do. And this is just a follow-up email we got from a listener named Adam. Thank you, Adam.
25:31 And you had talked about pickling things. Apparently you're a fan of dill pickles and
25:36 no wait, pickled strings, pickled lists, pickled dictionaries. No, we were talking about a pickling
25:42 and how it didn't make sense most of the time, but there might be some use cases and you're like,
25:46 what might be a use case that we really need? Right?
25:49 So Adam said, Hey, I got a use case that worked for us. I worked on an API that spoke to a third
25:55 party service that was wonky and it was over raw sockets. So you'd have to create these byte arrays
26:02 and send them along. And the thing was also not available 24 seven. It would sometimes crash,
26:09 things like that. So what they would do is they could set a flag in their app and it would pickle
26:13 all the messages that it would, would have sent. And if the site comes back, it can like rehydrate
26:20 those things and then ship them along, or you could pull them up for debugging and look at their
26:24 details and whatnot. So it was like, Oh, we got to save this exactly as we would have sent it.
26:30 Let's just pickle it.
26:31 That's pretty cool.
26:31 Yeah. That seems like a pretty good one.
26:33 Yeah.
26:33 And there was a feature flag they could turn on and off, which was kind of cool. Yeah.
26:36 They could also do that for the messages they got from the service. Pretty cool.
26:39 real quick. Python three, eight, four is out. I've already brew upgraded mine. So that's all good.
26:45 And big news, big news. I can't believe it. I've been selected.
26:49 For what?
26:49 I, if I go to my GitHub repo, I don't have the cool read me thing that you're talking about,
26:54 but under my picture, it says I have a pro account because I had to pay for some stuff,
26:59 but I noticed that I'm an Arctic code vault contributor.
27:03 Wow.
27:03 So remember we spoke about the Arctic code vault where GitHub is taking a bunch of the popular projects
27:08 and then like sticking them over in some vault in Norway or somewhere like that, Greenland,
27:16 to preserve it. And if the code that you've contributed to GitHub was selected, then now
27:23 you get this cool little highlight that's like a snowflake that says Arctic code vault contributor.
27:27 And you can hover over it and it'll say why. So yeah, I've contributed apparently to a couple
27:32 of things and you might be as well.
27:33 Well, yeah, you, the listener might, but I just checked mine and I am too. So that's neat.
27:38 Yeah. Awesome.
27:38 Neato.
27:39 Yeah. So.
27:41 I think we covered that once.
27:42 Yeah.
27:44 Yeah. We definitely covered the code vault, but yeah, I think this, you are a contributor
27:48 thing. The little badge is new and I don't know. It makes me happier than it probably should.
27:51 Yes. It's so cool.
27:55 It's cool.
27:59 Yeah.
27:59 Yeah. It's super neat.
28:01 Testing is cool.
28:02 I love testing and having good code coverage is cool.
28:05 Yeah.
28:05 So I've got a joke for you, a cartoon, if you will.
28:08 Okay.
28:09 From this place called geek and poke.
28:11 They have all sorts of good stuff there.
28:12 And, you can click on the picture and it'll take you to the actual comic.
28:17 So there's a two people, a woman developer and a man developer staring at each other.
28:23 And the woman is the more senior one.
28:25 They're looking at each other and it says QA best practices.
28:29 She's looking, looking at the guy and says, never just remove a failing test.
28:33 The guy stares back blankly for a second.
28:35 Says, only remove the assert statements.
28:38 Yup.
28:39 So how to sustain a decent code coverage.
28:43 yeah, you can fix a test.
28:46 You can make a test, not fail, remove the assert statements.
28:49 It's good.
28:50 Yeah.
28:50 That's funny.
28:50 You said you actually like test for failure though on yours that they potentially could
28:54 fail.
28:55 Yeah.
28:55 Well, I think that's one of the reasons why we do code coverage on all or not code
29:00 coverage.
29:00 We do code coverage, but we also do a review.
29:02 What's the word again?
29:03 Review.
29:03 Yes.
29:04 Code reviews.
29:04 Yes.
29:05 We do code reviews on tests because we have had a test show up before that exercise.
29:11 we, you know, with a test equipment, we do a lot of complicated things.
29:15 You set up everything, run some stuff, and then we've often have people forget to check
29:21 anything at the end.
29:22 And, and the, so it is important to look at the end to see, is there any way this can
29:28 actually fail?
29:29 Is it, or is it just exercising things?
29:31 I mean, actually exercising things isn't a bad thing because you can get a search in
29:36 your code or, except, or an exception.
29:39 Yeah.
29:39 You still test something, but you're not testing very much.
29:43 Yeah.
29:43 You're testing it runs basically.
29:47 Yeah.
29:48 So awesome.
29:49 Well, yeah, just never remove and fill in a test.
29:52 Only the search statements.
29:53 It's terrible.
29:54 We should not give that idea to people.
29:56 No, we should totally delete this joke.
29:58 It didn't happen.
29:59 It wasn't funny.
29:59 Yeah, it wasn't funny.
30:00 Thanks a lot, Michael.
30:02 Yeah, you bet.
30:03 Great to see you as always.
30:04 Thank you for listening to Python Bytes.
30:06 Follow the show on Twitter at Python Bytes.
30:08 That's Python Bytes as in B-Y-T-E-S.
30:11 And get the full show notes at Pythonbytes.fm.
30:15 If you have a news item you want featured, just visit Pythonbytes.fm and send it our way,
30:19 where I was on the lookout for sharing something cool.
30:21 This is Brian Okken, and on behalf of myself and Michael Kennedy, thank you for listening
30:26 and sharing this podcast with your friends and colleagues.





