#238: A cloud-based file system for Python and a new GUI!
Watch the live stream:
About the show
Sponsored by Sentry:
- Sign up at pythonbytes.fm/sentry
- And please, when signing up, click Got a promo code? Redeem and enter PYTHONBYTES
Special guest: Julia Signell
Brain #1: Practical SQL for Data Analysis
- Haki Benita
- Pandas is awesome, but … “In this article I demonstrate how to use SQL to perform fast and efficient data analysis.”
- First part of the article.
- SQL is faster than Pandas
- But they are great together
- Then tons of examples showing exactly how to best use SQL queries and Pandas in data analysis::
- Basics including random data and sampling
- Descriptive statistics
- Subtotals including rollup and groupign sets
- Pivot tables, both conditional expressions and aggregate expressions
- Running and cumulative agregation
- Linear Regression
- Interpolation
- Super cheat sheet for useful SQL queries
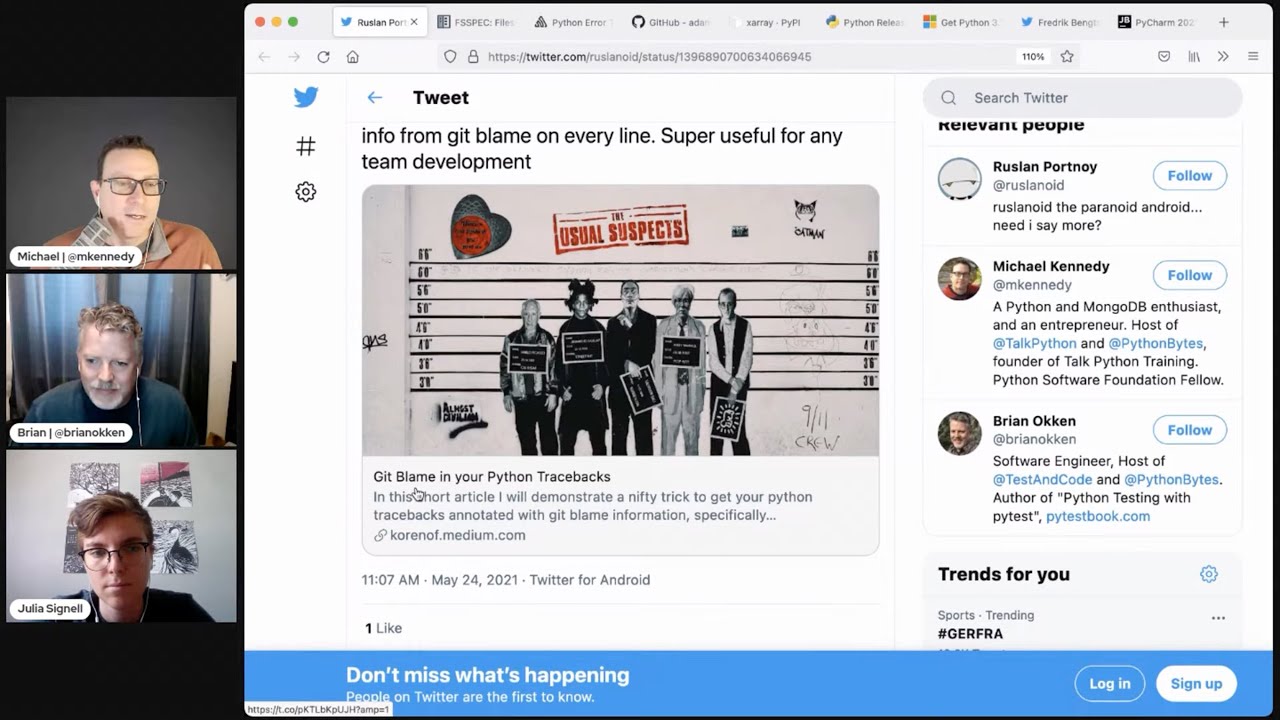
Michael #2: Git Blame in your Python Tracebacks
- via Ruslan Portnoy, by Ofer Koren
- Helpful Modules: traceback & linecache
- traceback uses linecache, and we can change linecache line’s text
- They create a git blame bit of functionality to add to line’s source
- Turns out this flows to things like PDB.
- Ripe for a proper package we can add to requirements-dev.txt
Julia #3: fsspec: a unified file system library
- Martin Durant
- Other libraries conform to the interface so that each part of the analysis pipeline is like an interchangeable building block (for example s3fs, gcsfs)
- With the cloud providers competing to host data, fsspec makes it easy to swap out the read layer so that you can hop clouds.
Brian #4: The need for slimmer containers or I’m even more confused now as to the usefulness of official base images on Docker Hub
- Ivan Velichko @iximiuz
- I read this article recently and it had me concerned. Then just yesterday read it again and there are some updates. I’m still concerned, but now also confused. So let’s run it down.
docker scancan be run on official Python images.- It uses Snyk Container. We talked about one form of Snyk on Episode 227.
- Spoiler, all of the official Python containers have vulnerabilities except alpine.
- But. In an update, the author says that Alpine has a bunch of problems.
- The update includes some discussion on Hacker News
- vulnerability scanners tend to have lots of false positives
- official base images are rarely updated
- some people suggest adding an upgrade command in the beginning of every Dockerfile.
- but others object saying that the practice leads to unrepeatable builds
- So, I’m left with wondering if using official Python images are even worth it.
- Michael: Python’s official image on docker hub
- Michael: PEP 656 -- Platform Tag for Linux Distributions Using Musl
- Michael: We dive a lot into this in our latest Talk Python recording (not out yet, but live stream is available)
- Some stats:
- Ubuntu: Found 32 vulnerabilities, 31 with upgrade.
python:latest: Found 364 vulnerabilities, 353 with upgrade- Ubuntu with source Python: 35 total, 28 low, 7 medium, several from intermediate tools such as wget, gcc, etc.
- Removing many dev tools SHOULD lower the count, but doesn’t (e.g. wget, gcc)
- Switching from
python:3-9topython:3.9-slim-busterdropped the issues to 69.
Michael #5: PandasGUI: A GUI for analyzing Pandas DataFrames
- Features
- View DataFrames and Series (with MultiIndex support)
- Interactive plotting
- Filtering
- Statistics summary
- Data editing and copy / paste
- Import CSV files with drag & drop
- Search toolbar
- Best way to see what it’s about is to watch the video.
Julia #6: xarray: pandas-like API for labeled N-dimensional data
- We’ve been talking a lot about the pandas API and how it’s a common target for dataframe libraries.
- Xarray is not a dataframe library, it’s for labeled N-dimensional data.
- People use it in geosciences, and in image processing where they don’t have tabular data, but the axes mean something (lat, lon, time, band…)
- You can select, aggregate, resample, using the real dimension labels.
- It can be backed with dask arrays or numpy arrays (or other types of arrays).
- It supports plotting with
.plot
Extras
Michael
- Python 3.10.0b2 is available (even windows store)
- Django security releases issued: 3.2.4, 3.1.12, and 2.2.24
- Another method overloading library?
- Recently moved to pip-compile requirements.in style after last week
- I’m running PyCharm EAP
Brian
- Someone responded to me the other day on twitter with an emoji that I was not clear on the meaning of. So I looked it up on emojipedia.org. Super useful for occasionally out of touch people like myself.
- pytestbook.com (redirects to pythontest.com/pytest-book/) has a facelift and a new home, to get ready for an announcement later this week. It’s built on markdown, hugo, github, and Netlify, so changes can be done super quick with just a commit and push. I just needed a nice readable theme, and Pradyun’s blog looked great, so I copied his choices.
- The blog will eventually also have writing, the legacy posts worth keeping from pythontesting.net, and probably transcripts from Test & Code.
Julia
- GH CLI
- entrypoints - they are so cool! Example - with pandas you can plot with different backends not just matplotlib and the logic for those backends is contained in the plotting libraries not pandas.
Joke
From https://upjoke.com/programmer-jokes
- I asked a programmer what her New Year's resolution will be.
She answered: 1920x1080.
How does a programmer confuse a mathematician?
x = x + 1
Why do Python programmers have low self esteem?
- They're constantly comparing their
selftoother.
Episode Transcript
Collapse transcript
00:00 Hello and welcome to Python Bytes, where we deliver Python news and headlines directly to
00:04 your earbuds. This is episode 238, recorded June 15th, 2021. I'm Michael Kennedy.
00:09 And I'm Brian Okken.
00:11 And I'm Julia Sidnell.
00:12 Hey, Julia. Thanks for coming on the show.
00:14 Yeah, thanks for having me.
00:15 Yeah, it's great. Why don't you tell folks a bit about yourself?
00:19 Yeah, so I'm the head of open source at SaturnCrowd and a maintainer of Dask. So I split my time
00:25 half and half. I spend half my time just doing regular like maintenance stuff on Dask. And then
00:31 half my time doing like engineering and product management on SaturnCrowd. SaturnCrowd is a
00:37 data science platform that really specializes in distributed Dask clusters in Jupyter and making
00:42 it really easy for people to get up and going with those things on AWS.
00:46 Yeah, Dask is really interesting. You know, when I first heard about it, I thought, okay,
00:52 this is a like a grid computing scale out thing, which I probably don't have a lot of use for.
00:57 But then I was speaking with Matthew Rocklin about it. And it has a lot of applicability,
01:01 even if you have not huge data, huge clusters, right? Like you can say even on your local machine
01:07 scale this out across my cores or, you know, allow me to work with more data than will fit in RAM
01:12 on my laptop and stuff like that. Right. It's a cool.
01:15 Yeah. Yeah. It has like a whole different, a whole number of different ways of interacting with it.
01:19 Right. Like there's that there's like, just make this thing go faster by paralyzing it. There's all the data
01:25 framey stuff. There's all the array stuff for more dimensional data. So it's got a, it's got a large API.
01:30 Yeah. Cool. And we're going to touch on a couple of topics that are not all that unrelated to, to those things
01:36 here. And so, yeah. Speaking of data science, Brian, you want to kick us off?
01:41 Sure. Yeah. The first thing I want to cover is an article called the practical SQL for data analysis.
01:48 This is by Aki Benita. So I, one of the things I like, liked about this is it was, it's kind of talking
01:57 about the first bit of the article was talking about basically that with, with data science,
02:03 you've got pandas and, and numpy and stuff. And you also have often you're dealing with a database.
02:08 So the, and SQL on the backend. So there's the first part of the article talks about how some
02:17 things you can do both in pandas and in, in, in SQL, like SQL queries it's faster in SQL. So there's a big
02:26 chunk that's just talking about how that's faster. But then, but then, you know, he also talks about just
02:33 basically there's, there's a lot of benefits to the flexibility and the comfortableness you can have with
02:38 pandas though. So trade offs as to where, you know, you can, where you're going to push the, push it too far
02:44 into SQL or, or have a nice split is good. But then he goes through and talks about a whole bunch of
02:50 great examples of different things like pivot tables and roll-ups and, and choices and different things
02:57 you can do with either pandas or SQL. And really what his recommendations are for whether it should be
03:02 in pandas or in, in SQL query, and then how to do those queries, because I mean,
03:08 really the gist of the articles and, and this problem space is people are comfortable with pandas,
03:15 but they don't really understand SQL queries. So this sort of a good cheat sheet for, for, for how to do
03:21 the queries is a, is a, I think really kind of a cool thing. So.
03:24 Yeah. I think it's really neat. And you, you have these problems, you know how to solve them in one
03:30 or the other. And I think this compare and contrast is really valuable, right? Like I know how to take
03:35 the mean of some column and SQL, but I haven't done it in pandas yet. Let's go see how to do that. Or
03:40 I'm really good at doing pivot tables and pandas, but boy, always kind of avoided joins in SQL. They
03:45 scared me. And then how does that even translate? Right. I think that back and forth is really valuable.
03:49 Yeah. Yep. And I, then it covers, covers things that I don't even know what they are,
03:53 like aggregate expressions. I don't even know what that is, but currently that's a, that's a thing
03:58 that people do. So I can help you out at aggregate stuff. No, just kidding. Julia, what do you think
04:03 of this? Yeah, no, it seems, it's really cool. Like, I agree that like the, having the, the,
04:08 having independence and then in SQL, that like comparison is super helpful. Like SQL is always super
04:13 scary to me. And I always end up like Googling a bunch of stuff whenever I have to mangle my SQL.
04:18 but I know it's so fast, so it's cool to see a way to access that.
04:23 Yeah, absolutely. This is a good one, Brian. I think a lot of people will find it useful.
04:26 I also want to just give a quick shout out to the past a little bit, not too long ago. We caught,
04:31 we talked about efficient SQL on pandas with duck DB, where you actually do the SQL queries against
04:37 pandas data frames. So if you're finding that you're trying to do something and maybe it would be
04:43 better in SQL, but you don't want to say completely switch all your, your data over to a relational
04:47 database, you just kind of want to stay in the panda side, but is that one or two things like,
04:52 this is really cool. This sort of upgrade your data frame to, execute SQL with the duck DB query
05:00 optimizer is also a kind of a nice intermediary there. Yeah. Dask also does some, I'm going to try not
05:06 not to make everything about Dask, but, Dask does some things that are kind of, that kind of
05:11 take some of the ideas in the, from this article of like doing predicate push down of like, of
05:16 pushing down some of the like filters into the read because it, because it evaluates lazily. It doesn't
05:22 have to like grab all the data greedily upfront. It can like do that later. so you can get some
05:27 of the benefits. That's cool. And it can also distribute the filter bit, I guess at that point.
05:31 Yeah. Nice. All right. I want to talk about the usual suspects. So, okay. That was, that was a
05:37 pretty good show. Was that Quentin Tarantino or something like that? It was not actually about
05:41 this. This comes to us from wrestling port port. Noy. And thank you for sending this in mentioned
05:47 an article that has this really interesting idea. How do you apply get blame when you encounter a
05:55 Python traceback? So here's the scenario, your code crashes and you either print out the traceback or
06:01 Python does it for you because it's just crashed. And normally it says, here's the value. Here's the
06:06 line of code. Here's the file. It's in here's the next line in the call stack. Here's a line of
06:12 code. It's in the idea is you can take get blame, which is a command that says, show me who changed
06:18 this line of code or who wrote this line of code, at least touched it last on every single line of
06:24 code. And I love this whole idea of like, all right, who did this? And sometimes I'll come across code.
06:28 I'm like, this is so crappy. Like who did this? Oh wait, that's me. Okay. Well, at least I know
06:33 what I would feel about it. But the idea is what if your traceback on each line where it had an
06:38 exception could also show who wrote that line of code. Cool. Huh? Yeah. So let's check it out.
06:45 It's pretty straightforward. This is an article by offer core or in, and it basically uses two libraries
06:51 that are themselves both pretty straightforward. So like here's a straightforward example of a traceback,
06:57 like trying to pop something off of an empty list says on this line in the function pop some,
07:02 you know, there's this line here in the call stack. And then the next line, this line,
07:06 the call stack and eventually raise a value error, you know, empty range, can't pop nothing off,
07:12 you know, something off of nothing basically. But this doesn't show you any information about like
07:16 maybe who wrote that line and who wrote this other line up here. Right. So, what they did is they
07:22 took a couple of modules traceback and then line cache. And it turns out when traceback shows you this
07:28 traceback that line, it uses line cache to figure out, okay, from this actual, I'm guessing,
07:34 bytecode that it's going to run this, CPython interpreter code. Where did it like,
07:41 what line of file did this actually come from? Right. So here's the insight or the thing
07:48 you can actually change what's in the cache. And because it's a cache, once it's figured out what
07:54 the lines are, it's not going to read it again. So it's like, like a list for each line that you
08:00 get back and you can just change the value. So it said, okay, well, here's like return random.
08:05 That's what the line of text was. They're like, no, no, no, there's nothing to see here. Move along.
08:08 If you make that and then you cause it to crash again, what comes out is, if you go a little
08:13 bit further down, normal code, normal code, or normal traceback, normal traceback, then it just,
08:17 instead of the line of code, it says nothing to see here. Please move along.
08:21 All right. So what are you going to do with that? Now that you realize like you can actually
08:25 change what appears in the traceback. So you write a little regular expression to go and execute,
08:33 get blame on the various files, and then to re-inject that back into line cache. And so what they do is
08:39 they just put, if they know the blame, they just put, you know, like 80 lines, 80 characters up to 80
08:45 characters of the line and then edited on such and date, such and such date by such and such person.
08:50 And here's the, commit message. Right. And so just basically shelling out to get blame when it
08:56 crashes. Now you get some really cool stuff. Like on this line, it says this is edited by, you know,
09:02 many, many days ago by so-and-so in this, get commit and so on. And what's interesting,
09:07 like this is already in itself useful, I think, but what's more interesting is other tools use this as
09:13 well. So for example, if you use PUDB, which is a sort of visual debugger, kind of, it's like a
09:19 command line one that I know visual in the sense of like Emacs is visual, not like PyCharm is visual,
09:24 but it will actually pull up that data. So you can see they, they jumped into the PUDB bugger and it's
09:29 actually showing all of this get blame attribution as well that they've added. So yeah, pretty interesting.
09:35 What do you all think? Yeah, I think that looks really cool. I mean, I always do get blame whenever I run
09:40 into something that's weird with the hope that someone else will be able to explain it to me.
09:43 Exactly. Who knows about this or who do I talk to about breaking this?
09:47 Right. Yeah. You could even put like PR numbers and stuff in here. Right. And that'd be pretty cool.
09:51 Yeah. Yeah. That'd be super cool.
09:54 Yeah. One of the things I like, I don't really like that the name get blame, but it's there.
10:00 But I agree with Julia that the main thing I use it for isn't to try to figure out who broke it,
10:05 but who to ask about this, this chunk of the code.
10:09 Yeah. I agree. Cause usually when you see something that's really confusing and weird, you're like,
10:13 I know they didn't just pick the hard way of doing this because they didn't want to do the easy way.
10:19 There's something that I don't fully understand. Some edge case that's crazy here. I'm going to go talk to
10:24 that person. So yeah. Also the, how long ago it was edited. So if there was something edited
10:29 yesterday, that's probably the problem. Yeah, exactly. Like in this little screenshot here,
10:33 some of these are edited like 1,427 days ago. That's probably not the problem. Maybe, but probably not.
10:41 I feel like I have the opposite assumption. Like if something is from six years ago and it's weird,
10:44 I'm like, well, probably things were different back then. And like, you know.
10:48 Yeah. Yeah. Yeah. It's no, no longer applicable to the new data, new situation. Yeah.
10:53 Oh, that'd be an interesting thing also is to have like a tool that would tell you if something's like
10:58 over a thousand days old or something like that, you probably should go refactor it to make sure
11:02 somebody understands that code. Yeah. Yeah. For sure. All right. Jumping back to the first item
11:08 really quick and the live stream, Alexander out there. Hey, Alexander says, I wonder if graph databases
11:13 with Gremlin queries could be more suitable for data science. You know, SQL joins are way harder.
11:18 Yeah. Graph databases are pretty interesting. If you're trying to understand the relationships,
11:22 that may well be better. I don't know. Hila, do you got any thoughts on this?
11:25 I don't know anything about graph databases. So out of my league.
11:30 I didn't have a desire to understand graph databases until I found out that there were Gremlin queries.
11:36 Now I think I want them.
11:38 Well, Brian, they don't start out as a Gremlin queries. They're Mogwai inserts. And then if you
11:44 insert them after midnight, then they become a Gremlin query. I mean, come on, we all know how it goes.
11:49 You definitely don't want to get them wet. Oh, that's an old show. I'm not sure if everyone's
11:53 going to get that reference, but yeah, that was, I love that show. Okay. Anyway, let's,
11:57 let's move on to the next one. The next one is you, Julia.
12:01 Yeah. So I wanted to highlight FS spec. So file system spec for people who can't hear letters very well.
12:08 So this is the basis for S3 FS. FS, I'm not getting the letters right, but there's, there's one for GCP.
12:19 There's one for S3 and basically it's a file system storage interface or like the basis for a file system.
12:28 And so you can do things like you can open just files as you can just take a path and open it as a, as a, as a file object in Python and read it with all the normal, like read, write operations.
12:41 Oh, interesting.
12:43 But from anywhere. So like there's all these different ones for S3 for GCFs and for, for like, even for like HTTP and just basically anything you've, you can imagine anywhere you can imagine a file being either there's already been one of these written.
13:04 It's kind of like a, it's an interface and then you write different packages on top of it that are like drivers or some, they have some name for it.
13:11 And it allows you to treat the file system as like this interchangeable building block.
13:18 So you don't get, you don't end up writing like photo three code or something that's like very specific to a specific cloud storage.
13:26 You write like this more general code and then it's really useful for like a lot of free datasets that are hosted on different clouds, but like they'll sometimes be on one cloud and sometimes be on another, but like basically it's the same data.
13:38 Or if you're at a company and you want to like switch clouds, it just makes that whole thing so much easier.
13:45 It looks really, really useful, especially for avoiding cloud lock-in.
13:50 Yeah. Yeah.
13:51 And you can always write, like you can always write your own one.
13:54 If something else pops up, you can write your own implementation of that.
13:57 Right.
13:58 So there's an example here talking about using a file system in the docs that says something to the effect of, well, you want to open up a CSV and feed it off to pandas, read CSV.
14:08 So normally you would say open CSV file, and then you just say pandas, read CSV and give it the file stream.
14:14 But what if that's on the internet?
14:16 What if that's on S3 with authentication?
14:18 What's that?
14:18 What if that's somewhere else?
14:20 Right.
14:21 And so with this one, you can just say FS, file system spec, open.
14:25 Here's a URL.
14:26 And now that's a stream, right?
14:28 Or that could be, here's an S3 location, S3 bucket.
14:32 Go get that, right?
14:32 Yeah.
14:33 Yeah.
14:34 So instead of passing the path directly into the read function, you pass in the file object.
14:39 And it's really powerful.
14:43 It seems like a thing that we shouldn't need.
14:45 But files get like the file locations can get so crazy so quickly.
14:50 And this just really helps simplify and like, make it so you don't have to think about this stuff, which I think is what most people want.
14:57 It's what I want.
14:58 Yeah, for sure.
15:00 So like there's a local file system option.
15:02 But then you could also have an FTP file system.
15:05 Or you could have something else, right?
15:07 All sorts of different options.
15:08 Yeah.
15:09 Yeah.
15:09 All sorts of stuff.
15:10 Yeah.
15:11 Okay.
15:11 That's cool.
15:12 Brian, what do you think?
15:13 Does it have any applicability for you?
15:15 Oh, yeah.
15:15 Definitely.
15:16 And that's a great abstraction layer to put in place to just have reading as if it was a file and have it moved.
15:24 It also helps you develop tools locally and then be able to deploy them into a larger space.
15:30 So it's cool.
15:31 Yeah, for sure.
15:32 One of the things that always makes me a little hesitant when I hear people say things like, we're cloud native.
15:38 Like my app is cloud native.
15:40 That's always code word for me.
15:41 Like I will never be able to run my app unless I'm connected to the internet.
15:44 You know, it's like it depends on all these services together.
15:47 And there's no way I can recreate that locally.
15:49 But something like this could allow you to say, well, we're going to have a local file system version.
15:54 But then when we go to production, we'll switch to S3 or, you know, pick it.
15:57 Pick something.
15:58 I've always wanted to make it either a t-shirt or a sticker or both that says not a cloud native, just visiting.
16:03 Nice.
16:06 I also think, Brian, there might be testing opportunities here.
16:09 Yeah, definitely.
16:10 Give it a test file system.
16:12 That'd be cool.
16:13 Yeah.
16:13 And like Julia said, swapping things out to just have your logic not have to care where it's coming from.
16:20 But I guess you'd have to make sure all of the interfaces, the different storage systems really are equal.
16:29 But I guess you should try that out yourself.
16:32 Yeah, there's like kind of a bucket, right?
16:35 There's kind of like a dict that you can pass, which is like storage options.
16:38 So I think that can, that might get a little wonky depending on what the different backends need.
16:44 But the general principles are the same.
16:47 And it also, I should have said this originally, but it also allows, like FS spec itself can contain logic to do things that are general to all the different libraries, like caching and things like that.
16:58 It's all the different.
16:59 Oh, interesting.
16:59 Like you could put a caching layer on top of arbitrary things like S3.
17:03 Yeah.
17:04 Google storage and Azure buckets or blob storage.
17:07 Yeah.
17:07 Yeah.
17:08 Maybe even save money on bandwidth there if you can do some caching.
17:12 Yeah.
17:12 If you can do it right.
17:13 Yeah.
17:14 Super, super neat.
17:15 Brian, you're going to tell us about how to slim down our Docker containers.
17:18 But before you do, I want to tell people about our sponsor for this episode brought to you by Sentry.
17:23 So how would you like to remove a little stress from your life in addition to just abstracting your file system?
17:28 Maybe tracking down some errors.
17:30 So do you worry that your users may be having difficulties or encountering errors with your app right now?
17:35 And would you even know it until they send that support email?
17:38 How much better would it be if you got the error or performance details sent right away with all the call stack?
17:44 Maybe you would get blame in there.
17:46 The local variables, the active user who was logged in while this happened, all that kind of stuff.
17:51 So with Sentry, it's not only possible, it's actually really simple.
17:55 I've used this on Sentry.
17:57 I've used Sentry on our websites before.
17:59 So it's on Python Bytes, Talk Python Training, all those different sites.
18:02 And I've actually had someone encounter an error trying to buy a course over on Talk Python Training.
18:07 I got the Sentry notification.
18:08 I said, oh, geez, I can't believe this problem crept in here.
18:12 And I fixed it really quick and started to roll out the fix and actually got an email.
18:16 They said, hey, we're having this problem buying a course.
18:18 I know.
18:18 I've almost got it fixed.
18:19 Just give me a moment and try again.
18:21 And they were just like, what?
18:23 That doesn't make sense.
18:24 So they were very surprised.
18:25 And so it's surprising to let your users create your Sentry account at pythonbytes.fm slash
18:30 Sentry.
18:30 And when you sign up, there's a little got a promo code.
18:32 Make sure that you put Python Bytes, all one word, all caps with a Y in there.
18:37 And you'll get two free months plus a bunch of extra features and so on.
18:41 So also, it really lets them know that you came from us rather than just somewhere else.
18:45 And that helps support the show a lot.
18:46 So pythonbytes.fm/sentry and promo code Python Bytes.
18:50 Awesome.
18:50 Thanks for supporting the show, Sentry.
18:53 And Brian, let's talk Docker.
18:55 Yeah, let's talk Docker.
18:57 I mean, I'm starting to use Docker more and more.
19:00 And I like the experience.
19:02 But I was interested when this article came up.
19:05 So it was in June.
19:07 I saw this article called The Need for Slimmer Containers.
19:11 And this is from somebody, Ivan.
19:15 Ivan, I'm not going to try his last name.
19:17 Ivan something.
19:17 But anyway, it's an interesting discussion.
19:20 And the idea around the original post was that there's now a Docker scan that you can use.
19:29 So you can use Docker scan to scan for vulnerabilities in your Docker containers.
19:35 And this, Ivan thought, well, I'll look at some of the standard Python containers that are available.
19:40 Right.
19:40 Theoretically, some of the things that are nice is I can just go and say Docker or in my Docker container, I can say from Python colon three nine.
19:49 And I don't have to think about how do I install Python?
19:51 How do I keep it up to date?
19:52 You know, make sure that pip is there and that I'll be able to, you know, pip install stuff that needs to do build things.
19:58 All that stuff will be there, right?
19:59 So it seems like, of course, this is what you want.
20:02 Yeah.
20:02 Well, and also, that's kind of one of the neat things about Docker.
20:06 I can just say I have these standard parts.
20:08 Now I just want to put my custom stuff on top of it.
20:11 And it's great.
20:13 So, well, what did he find?
20:16 So he used, so Docker scan apparently uses a third party tool called Snake, S-N-Y-K container.
20:23 And we've covered Snake before, not the container version, but we covered Snake in episode 227.
20:30 But so it's looking for vulnerabilities, and that's a good thing.
20:35 But he found them in everything.
20:37 And he found them in all of the standard Python ones, except for Alpine, I guess.
20:44 And so he didn't really know what to make of it, really.
20:47 He was just sort of reporting his results that maybe Alpine is the only one with few vulnerabilities.
20:53 But then this went out on Hacker News, and there was a big discussion around it.
20:59 So he updated the article, which I appreciate, with some of the feedback that he got.
21:06 And so some of the feedback was that these vulnerability checkers sometimes give you false positives.
21:11 And I don't really have enough experience to know what that means, but I don't have enough experience to know if these really are false positives or if they're actual vulnerabilities or not.
21:24 The other thing that maybe some people suggested that these standard ones really aren't updated very much.
21:33 So I don't really know much about that either.
21:35 And if they're not, that's kind of a bummer because I think people are relying on them.
21:40 So I actually just kind of am left with a little bit of a confusion as to what to do.
21:45 I want to also mention that the Alpine, in his current one, or his original article, he says Alpine's pretty good for vulnerabilities.
21:54 But then his follow-up says it doesn't really...
21:57 Well, there's a lot of applications that can't run on Alpine because of some issues or another.
22:01 So anyway, I'm not sure what to make of it.
22:03 So I was hoping Michael might give us some insight.
22:06 I did some thinking about this morning.
22:08 And in fact, I recently spoke a lot about this over on Talk Python.
22:14 So I had Itamar on the show, and we talked about best practices for Docker packaging.
22:21 And we talked a lot about both security and package size.
22:25 So I can try to relay a couple of things from that.
22:28 So we've got our official image over here, our Python official image.
22:32 There's actually a bunch of options.
22:34 As you can see, there's a few, like 310 beta 2 Buster or the 310 RC Buster.
22:42 That sounds bad, but I think it's actually good.
22:44 No, I'm just kidding.
22:44 I know what it is.
22:45 So these are by default based on Debian.
22:49 And Buster is the latest version of Debian.
22:51 And so you can do a Buster, which is like full Debian with 310, or you can do a 310 Slim Buster, which is like a slimmed down version of Debian Buster that supports Python 310.
23:02 Okay.
23:02 So there's a lot going on here in terms of the options.
23:07 One of, so the article talks about how Alpine had the fewest security vulnerabilities.
23:14 And I actually, so the Python latest, if you run the sneak package scanner thingy on it, it says there's 364 vulnerabilities.
23:23 If you just do Python latest, three, nine, and 353 after you run apt update, apt upgrade.
23:32 So if you try to get the container to update itself, there's still 353 in the, that one.
23:38 I don't use that.
23:39 I use Ubuntu.
23:39 So I use the Ubuntu latest and the bare version of that one had 31 vulnerabilities.
23:46 But then if I either install Python through apt or, or build it through source and put it in the necessary foundational bits, like build essentials and stuff to build Python, it goes up to 35 total problems.
23:58 We're at 28 of Merlot.
23:59 So seven or medium, nothing major.
24:01 One thing I thought was weird was I actually ran another step where I said, okay, let's uninstall those intermediate tools like GCC and Wget and stuff like that, that I needed to get stuff on the machine, but I'm not going to use again.
24:13 And I took them away.
24:15 And almost all those warnings were about those tools that I had apt uninstalled.
24:19 So I don't know why sneak is still showing them.
24:21 Cause if I go into the container, I type Wget, it says, Nope, this thing is not installed.
24:26 Sorry.
24:27 But it still says the warning is that Wget has a vulnerability in it, for example.
24:31 Right.
24:31 So there's like, there's like this over-reporting for sure.
24:34 But I mean, the difference between 28 and 350 is not trivial.
24:38 Right.
24:39 Right.
24:39 So like running an apt install Python three type of thing is not, you know, it's probably worth it.
24:44 For example.
24:45 When I switched from Python three, nine to Python three, nine slim buster, it went from 350 to 69.
24:54 So that's a lot better.
24:56 Right.
24:56 Yeah.
24:57 it's still not as good as a moon two, but it's a lot better.
25:00 The it's still twice as many.
25:02 I mean, you can't, it sounds better, but it could be like 359 low problems and then 69 critical ones.
25:09 it totally could.
25:10 It totally could.
25:11 Yeah.
25:11 Also if the reporting, like if the, if, if we can't trust snake necessarily, then like maybe,
25:19 you know, if you can't trust your reporting system, then like maybe that, maybe none of this is means anything.
25:25 Right.
25:25 Yeah.
25:25 Yeah.
25:26 I think one of the things the article originally started out to address was if you have fewer subsystems,
25:32 there's no chance the missing subsystem could get hacked because it's not there.
25:36 Right.
25:37 So if there's a vulnerability in SSH, but you literally don't install SSH, who cares?
25:42 Whereas if you, you know, you're going to have a lot of things that you're going to have to do with your own.
25:46 You're going to have to do with your own.
25:47 You're going to have to do with your own.
25:48 You're going to have to do with your own.
25:49 Yeah.
25:49 And then it went down this rattle of like, well, let me scan it.
25:52 And so on.
25:52 So I want to add one more thing.
25:54 Like Alpine did result in the best outcome from the scanner, but there's a lot of issues with Alpine and Python.
26:01 So for example, there's this PEP here, 656, that right now, if I try to pip install something on Alpine.
26:10 So especially in the data science world where things are large and the compiling takes a lot of steps and so on.
26:15 The wheels that are built for Linux are built for, is it GLib?
26:21 GClib?
26:22 I mean, hold on.
26:23 I'll look over here.
26:24 I wrote it down.
26:25 So I know.
26:25 No, I didn't write it down.
26:27 Sorry.
26:27 There's like, I think it's GLib or GClib, which is the C runtime on like Ubuntu and Debian.
26:32 But there's one MUSL, Muscle, on Alpine.
26:36 And the wheels are not built for Muscle.
26:39 They're built for GClib.
26:41 And so you can't pip install that.
26:44 You've got to download everything and then compile it.
26:46 And it's like compiling matplotlib and Jupyter from scratch can take a really long time versus just downloading the wheel.
26:53 And it takes up a lot of space.
26:54 And there's a bunch of issues and things around that that make it slightly not Python friendly.
26:59 That's why there's this pep, pep656, to allow wheels to be tagged as supporting Muscle, not GClib.
27:08 Is that more than you wanted, Brian?
27:10 Are you good?
27:10 Okay.
27:11 So the takeaway that I'm getting is probably not panic on some of these, but maybe at least pay attention to them.
27:18 And it is good, like you said, to remove tools out of your Docker images that you're not using.
27:27 If you're not using Wget in your application, take it off.
27:30 Things like that.
27:31 Yeah, exactly.
27:31 I think Julia's point was great, right?
27:33 It's if you it might be a false positive.
27:35 But at the same time, if you're not going to use it again, because Docker, a lot of times you pip install all your stuff and then it's kind of ready to run.
27:43 But you're not going to go and pip install something again.
27:46 You're going to do a new Docker build from scratch.
27:48 Right.
27:49 Like one of the final lines could be remove, remove all those intermediate things that could have problems and make it larger and whatnot.
27:56 Yeah, I thought so I've only thought about this from like package from like image size.
28:02 Right.
28:02 Like that.
28:02 Yeah.
28:03 That you want some more images just because it takes forever to get them around.
28:07 But it's interesting to think about from the vulnerability perspective.
28:10 And I've always seen it done as you do whatever installation you need and then you do all these like cleaning steps.
28:17 But what you said, Michael, about like not ever putting certain things on your image was is interesting.
28:23 I haven't heard of that before.
28:24 Yeah, thanks.
28:25 I also had Peter McKee from who works at Docker on Talk Python a little while, like six months ago or something.
28:31 And he talks about having these multi-step builds, something to the effect of doesn't make as much sense with Python.
28:36 I'll try to put it together.
28:38 But like imagine you're building a Go library.
28:39 You could put the Go runtime and build tools on a container, build your thing.
28:44 But the thing you get from Go is an actual binary that's all self-contained.
28:48 You could throw that container away and just copy the output of that into your actual container and never even put all those tools on the
28:55 actual system that goes to production.
28:57 With Python, that might look something like maybe using PEX to package up all the stuff inside of a virtual environment.
29:04 And long as Python, the runtime is there, then you can like PEX run on your other machine.
29:08 But you could potentially not even ever install those, which might be good.
29:11 Yeah, that makes sense.
29:12 There's a lot there that is sort of beyond my comfort level.
29:17 But that's what I thought as I looked at this, Brian.
29:20 Well, thanks for taking a look.
29:21 There you bet.
29:22 All right.
29:23 We'd like to talk about GUIs on the show every now and then.
29:26 And we want to talk about pandas and data frames and data science and all that.
29:32 So let's put those together.
29:33 There's this project over here called Pandas GUI.
29:37 And the documentation is sparse, let's say.
29:41 It's pretty easy.
29:41 There's a couple of examples or two.
29:43 So I could come down here and I could like do my panda stuff and create a data frame.
29:46 And I could just import show from the pandas GUI.
29:49 And within my notebook, it will pop open a separate window that it then allows me to cruise around and check it out.
29:56 So it does, you know, you can print out the data frame in a notebook and you get kind of a static Excel grid looking thing.
30:04 And that's nice.
30:05 But with this, you get a interactive one that lets you sort and select.
30:10 You can actually copy and paste chunks out of there as if it was Excel and then paste it in other places.
30:15 It also has a plotting library with like pictures.
30:18 So I'm going to go click on the bar graph picture.
30:20 And then there's a list of all the columns and the things that the bar graph needs.
30:24 And you can drag and drop this column is the X axis and this column is the Y axis.
30:29 And I want to group by color and have, you know, group by color it by some other aspect of the data.
30:35 And, you know, like group into multiple charts or multiple lines or plots on a chart.
30:40 All sorts of cool stuff like that.
30:42 There's a statistics section.
30:43 There's you can export important export, I guess, import CSV files with drag and drop.
30:49 And there's also search that you can do.
30:51 So it's a pretty neat, quick way to explore pandas.
30:54 Yeah.
30:55 It's a neat idea.
30:57 Like when you, when you first encounter a data frame, like you really want to, you really want to just be able to like look at it without any assumptions.
31:05 And there's a lot of stuff that like kind of goes towards that with like the dot plot API and pandas and making that, making it really accessible to make plots really quickly.
31:15 But this is like kind of like the step beyond that, right?
31:18 Of just visualizing it immediately.
31:21 Yeah.
31:21 Like one thing you get when you view the data frame as, you know, like I said, it looks kind of just like printing DF in or just typing DF in the notebook.
31:29 But then on the right, you can say, oh, I want to see the filters.
31:32 And you could type in these filter expressions, these query expressions, and then turn them all, like pile them on.
31:38 You can have little checkboxes to like optionally turn them off, but not delete them.
31:42 And then of course you can sort within there like that.
31:45 And the graphing, I think the support for the graphing part is really, really helpful.
31:49 So the fact that you can just go and click and say, oh, I want a box plot.
31:53 And then the box plot needs these things.
31:56 You can just drag and drop from the column, from your data frame definition over, and it just live updates.
32:02 Yeah.
32:02 I think that really like lets people visualize the data in the way that they want to sometimes, rather than like the way they already know how in that plot loop.
32:11 Which I think is what people end up doing, at least for exploratory stuff.
32:15 Yeah, exactly.
32:16 You could real quickly switch between a bar, a box, a scatter plot, back and forth without having to actually be familiar with how those works.
32:23 Can you tell if there's a way to export the filters or is there any mechanism for that?
32:29 There is, I don't think so.
32:31 At least in the YouTube explainer video, there were some comments like, you know what would be awesome?
32:36 Export this as code from here so that I can just turn it back into Python.
32:41 I didn't see anything like that.
32:43 Yeah.
32:44 Sometimes GUIs are a little weird for me because of that.
32:47 You know, like you end up in this GUI world and it's not, you can't reproduce anything.
32:51 I clicked on a whole bunch of stuff and then it looked great, but don't touch it.
32:56 Yeah, exactly.
32:57 I can't do it again.
33:00 Okay, but to be fair, it is a fairly quick way to look at the data and know what you, maybe you can't produce that exact plot again, but you know what the data looks like and you can use a different plotting mechanism to do that.
33:13 Yeah.
33:14 And the visually it's pretty clear.
33:15 Like, okay, well, X is assigned to speed and we know it's a histogram.
33:18 And so you could pretty quickly, you know, with some Googling stack overflowing, go, all right, how do I map plot live a histogram and get that going?
33:26 You know?
33:26 Right.
33:27 That's a huge time saver.
33:29 Yeah.
33:29 But some, some, some sort of export of like, okay, give me the code to make this plot in my own code.
33:34 That would be great.
33:34 Yeah, absolutely.
33:36 Absolutely.
33:37 All right.
33:38 On to the next.
33:39 But before we get there, I do want to call out just a shout out by Pylang that FS spec is sweet.
33:45 Good mention.
33:45 Yeah.
33:46 I like it as well.
33:47 Cool.
33:48 All right.
33:49 X-Ray.
33:49 X-Ray.
33:50 Okay.
33:51 So X-Ray is, it's my favorite library.
33:57 It's a, it's like a pandas.
33:59 So it's a pandas like API, but it's for N dimensional data.
34:04 So if you have like a lot of times people talk about in like geospatial data where there's that long time and others, but also for image data where there's maybe a bunch of different bands from like satellite imagery or other disciplines where you just have labeled data.
34:21 That's not tabular.
34:23 So the axes like mean something, but there's not just one or two of them.
34:28 Then X-Ray is like great for that because it lets you do things like you can select a certain subset of time or a certain subset of whatever your dimension is.
34:39 And you can also aggregate across different dimensions.
34:43 And you can use the labels directly.
34:45 So if you don't have a tool like this, I see people doing this a lot with like machine learning workflows where they'll be, they'll have like separate, like a list of all their, they'll have like a list of all their labels and then they'll have their data and they'll do some manipulation and they'll try to like reattach them at the end.
35:04 And it's just, it just turns into a mess.
35:08 And it's actually just like takes care of that all for you.
35:12 It's pretty great.
35:13 And I think that it has applications that have not been fully realized yet.
35:18 And it's starting to like take off in other spaces, but it really comes from this geospatial world.
35:23 But I think it could be useful for all sorts of people.
35:25 Right.
35:26 Because in geospatial, sometimes you have three dimensions, not just two.
35:29 Yeah.
35:30 You almost always have three.
35:31 Right.
35:32 Sorry, Brian.
35:33 Go ahead.
35:34 No, the documentation looks great too.
35:35 The documentation has like getting started guides and tutorials and videos and galleries and stuff.
35:42 So definitely check out the documentation.
35:44 Yeah.
35:45 I think it got a major, it seems like I looked at it for this too, and it seems like it got a major facelift.
35:49 So it looks really nice.
35:52 It also has like plotting.
35:55 It supports the dot plot API or some different version of it that's like the pandas version.
36:01 But you can plot in different, you know, three dimensions or aggregate and then plot.
36:06 And so that's like a really nice way to get the visuals quickly.
36:11 And then the last thing that I wanted to say about it is that it's normally backed by NumPy arrays, but it can also be backed by Dask arrays or Sparse arrays or all sorts of different arrays natively.
36:23 So it's a, it's a really cool, it's another one of these like building block things where you can have X arrays like you're labeling and you're indexing and all the like nice stuff.
36:32 And then down inside it can be NumPy or QPy or Dask.
36:38 How interesting.
36:39 So it's, it can do that juggling and piecing back together that other people are manually doing and you just have this simple API.
36:45 And if it has to do that, it'll figure it out.
36:47 Yeah.
36:48 Yeah.
36:48 That's pretty cool.
36:49 Nice.
36:50 And you talked about QPy and Dask.
36:52 Like those are some pretty interesting backends for this.
36:55 Yeah.
36:56 Yeah.
36:56 The Dask one is, I said QPy.
37:00 And now I'm wondering if maybe it's just like Dask and then QPy.
37:04 So don't quote me on that.
37:05 But, but yeah, the Dask one is, is like really integrated with X-Ray code.
37:11 So you do like, they do just do some special things to make it so that it works with paralyzing and things.
37:16 But, but from the user experience, it's the same.
37:19 Yeah.
37:19 Fantastic.
37:20 And then also noticed it requires Python 3.7.
37:23 Really nice to see tools sort of keeping up with the latest, not, not, not really old stuff.
37:28 Well, hopefully it's 3.7 and above.
37:30 Well, yeah.
37:31 Yeah.
37:31 Greater than or equal to.
37:32 Well, I mean, I ran into a library.
37:35 It was an internal thing that, that was only 3.7.
37:38 So I tried it on, I'm like, I assumed or above and I tried it on 3.9 and it like fell over.
37:44 Like what's going on?
37:45 It was only 3.7.
37:46 It's weird.
37:47 Okay.
37:49 That is weird.
37:50 That'd be interesting to think about what special features of 3.7 there, depending on that broken 3.8.
37:56 Yeah.
37:56 That's what I was thinking.
37:57 Like, how do you do that without just checking for equal, equal 3.7 on version?
38:01 Yeah.
38:02 So anyway.
38:03 Yeah.
38:03 All right.
38:04 Well, that's it for our six main topics.
38:06 Brian, you got anything else you want to throw out there quickly?
38:09 Yeah, actually.
38:09 So I didn't have this up, but there was a, on Twitter, somebody like reacted to me with an emoji and I didn't, didn't know what they meant.
38:22 So I looked up, let me, let me pop this up.
38:28 And it was helpful and you can just, you can just copy and paste the emoji that somebody uses in there and it tells you what it means.
38:37 And the, you know, kind of not just what it's supposed to mean, but also what people are using it for.
38:44 Anyway, for somebody that's sort of an old, old guy that is out of touch sometimes, this was helpful.
38:49 Anyway.
38:51 Yeah.
38:51 I mean, sometimes it's obvious, like a heart, we know what a heart means.
38:54 Right.
38:55 But, you know, like hands together, it's not necessarily that that's like a thank you sort of bow type of thing.
39:00 I mean, there's certain ones where you're like, ah, what does that mean?
39:03 It was like a hands together with like arrows coming out of the top.
39:06 And I'm like, I don't know what this is, but apparently it's just raising hands.
39:10 Like, like you're saying hooray for somebody.
39:12 Oh, okay.
39:13 That's nice.
39:14 So.
39:14 Okay.
39:15 It's good.
39:15 I use Emojipedia all the time, but I think I use it in the opposite way.
39:18 Like I use it to get an emoji to like put somewhere because I don't have like an emoji keyboard or whatever.
39:24 Oh yeah.
39:25 That would be good too.
39:25 The other thing I wanted to bring up is I hopefully have some cool news to share tomorrow about the pytestBook and the news will show up on a revamped pytestBook site.
39:38 So if you go to pytestBook.com, you get redirected to this Pythontest.com page where I'll talk about the second edition.
39:48 Hopefully there'll be news about the second edition coming out tomorrow.
39:51 Is your new static site magic?
39:54 Yeah.
39:55 Yeah.
39:56 Static site.
39:56 And I totally, and it goes dark and light.
39:58 But I totally stole from Pragyun.
40:01 So Pragyun has the same, he's got a really nice site.
40:06 So it's a bunch of great, great.
40:08 It looked great.
40:09 And I'm like, that'll work.
40:10 I'll just do what he's doing.
40:11 So that's what I did.
40:12 Yeah.
40:13 Yeah.
40:13 Very cool.
40:14 I think we have exactly the same stack for our Saturn Cloud site now.
40:17 Oh, how neat.
40:18 So it's cool.
40:19 Awesome.
40:20 How about you, Julie?
40:21 Anything else you want to give a shout out to?
40:22 Well, I've been really into entry points recently.
40:26 Just like the concept of them is very cool.
40:29 As in like Python packages, you can give them almost like CLI command type entry points?
40:34 Yeah.
40:34 But the thing that I think is really cool is like, like, like Matplotlib.
40:39 This is an example that, that made me first realize about entry points is Matplotlib has
40:43 this .plot.
40:44 I think I mentioned this three times now.
40:45 But you can swap out the backend.
40:47 So you don't have to have Matplotlib.
40:49 You can use other backends.
40:50 And all the logic for that is in the other visualization libraries themselves, not in
40:57 Pandas.
40:57 So it's, it's just like, you can swap out other things.
41:02 It's not just for CLIs.
41:03 Okay.
41:04 Yeah.
41:05 How neat.
41:05 All right.
41:06 Yeah.
41:06 I learned about entry points a year, year and a half ago.
41:09 And ever since I'm like, oh yeah, this is awesome.
41:11 I can now create these little commands that'll be part of just my shell.
41:14 I love it.
41:14 Yeah.
41:15 The other thing I wanted to say was GitHub CLI is really cool.
41:18 I think that's standalone, but it's, I've been using it a lot.
41:22 I'm sure people know the Git CLI, but what's the story of the GitHub CLI?
41:27 Oh, well, the GitHub CLI is, makes it, so if you have ever tried to check out a branch on
41:34 someone else's fork, like if you want to like evaluate a PR that someone has put on a fork.
41:38 Yeah, exactly.
41:39 Yeah.
41:39 That is the situation where the GitHub CLI is really great because you can just do like
41:44 GH checkout PR or a GH PR checkout, whatever the number is, and that you're just on their
41:51 branch then.
41:51 And if you can push, if you have push access to their branch, if you're a maintainer and
41:55 they've allowed it, you can just push directly.
41:58 And you don't, I mean, I was always looking at that sequence of commands before, like I
42:03 know people have like Git aliases and stuff, but yeah, I'd really recommend checking it
42:08 out if you do a lot of GitHub stuff.
42:09 Okay.
42:09 Awesome.
42:10 Yeah.
42:10 That's great advice.
42:11 Yeah.
42:11 I often want to like check out some, so a pull request, I want to be able to like play with
42:15 it and run their code.
42:16 And yeah.
42:17 And so, yeah.
42:18 It's the best.
42:19 Yeah.
42:20 Awesome.
42:20 All right.
42:21 I got a couple of things to add, by the way, first of all, just that first practical SQL
42:24 analysis that you talked about.
42:26 It also is a similar theme that you were talking about, Brian.
42:29 One of the things I thought was cool though, as you scroll through it, it has a progress bar
42:33 for reading at the top.
42:34 And that just made me so happy.
42:35 I don't know why that was, that was really neat.
42:38 All right.
42:38 But I have a bunch of hear all about it sort of things.
42:40 So really quick, Python, B2, I just got the center.
42:44 Yeah.
42:44 Okay.
42:45 Live update.
42:46 Python 310 beta 2 is out if people want to check that out.
42:50 And you can go download that.
42:52 It also highlights all the major features like the pipe operator for writing unions and type
42:59 specifications and a bunch of other stuff that people might care about.
43:03 Structure pattern matching.
43:04 It's probably a big one.
43:06 Yeah.
43:06 Go to the completely different down.
43:07 Is that on here?
43:09 And now for something completely different.
43:10 I love that part.
43:11 So right above the files.
43:12 Yeah.
43:14 Oh, interesting.
43:16 The Aaron Fest paradox concerns the rotation of a rigid disk in the theory of relativity.
43:21 It's original 1909 formulation presented by.
43:24 Yeah.
43:25 Okay.
43:25 That is unexpected, but very cool.
43:27 And completely different and irrelevant.
43:29 Yeah.
43:30 Yeah.
43:30 Awesome.
43:31 Okay.
43:31 So takeaway 310 beta 2 is out.
43:34 People can check that out.
43:35 There's also some security patches for Django.
43:37 So be sure to check that out.
43:38 One thing that surprised me is the Microsoft install Python from the Windows store is already
43:45 like has a 310 beta store install.
43:49 So, okay.
43:50 That's pretty cool that they're keeping that up to date.
43:52 And it's rated E for everyone.
43:54 Yeah.
43:54 Even kids can pip install.
43:56 Awesome.
43:57 So Frederick Bankston sent a message in response to our last show where we talked about the
44:03 method overloading by type.
44:05 Like if it takes an int or a string, it calls different functions.
44:08 It's also pointed us towards this multi-method other library that is similar.
44:13 So people can check that out.
44:14 That's cool.
44:14 Yeah.
44:14 Neat.
44:15 Speaking of the GitHub stuff, I've been starting to use PyCharm 2021 to early access
44:22 version, early access program version one.
44:24 And it's been working fine.
44:25 So if people want to try out the new features, there's a bunch of cool stuff.
44:28 You have support for Python 310 and new stuff for pytest.
44:32 I don't remember if this came in here, but one thing that I did learn about that recently
44:38 that's in there that's super cool is they have in PyCharm, if you log in PyCharm into
44:44 your GitHub account, there's a pull request section and you can just click it and it'll
44:48 do those same steps that Julia was talking about.
44:50 Like right there in PyCharm, just go, I want to try that PR before I accept it and just click
44:55 that and go.
44:55 You can even have comments.
44:57 You see the conversation inside there and everything.
44:59 It's cool.
44:59 Never go to GitHub again.
45:01 Exactly.
45:02 And don't just forget how to use it basically.
45:05 All right.
45:05 That's it.
45:07 That's all the items I got.
45:08 So yeah, I've got other stuff that's just hanging around from before.
45:11 Cool.
45:11 All right.
45:12 Well, you want to close it out with a joke?
45:14 Yeah.
45:14 A couple of jokes.
45:15 Always.
45:16 All right.
45:16 So over at upjoke.com slash programmer to ask jokes, you'll find many bad jokes.
45:22 Some even that are not very appropriate or whatever, but there's a few that are funny.
45:26 So I pulled out three here.
45:27 I'll do the first one.
45:29 Brian, you can do the second.
45:31 Julie, you can do the third, I guess, if you're up for it.
45:33 Okay.
45:33 So this one we should have saved for six months from now.
45:36 But I asked a programmer what her new year's resolution would be.
45:39 She answered 1920 by 1080.
45:41 That's so bad.
45:42 No, that's awesome.
45:44 It's really bad.
45:45 All right.
45:45 Well, you got to do the next one.
45:46 How does a programmer confuse a mathematician?
45:51 I don't know how.
45:53 Just saying that X equals X plus one.
45:55 All right, Julia.
46:00 Okay.
46:00 Why do Python programmers have low self-esteem?
46:03 They're constantly comparing their self to other.
46:06 Also bad.
46:10 Probably the worst.
46:11 Sorry we gave you that one.
46:12 That's okay.
46:13 I saw this.
46:15 I saw the one that Brian did and I was like, oh, it should be X plus equals one.
46:19 And I was like, no, that ruins the joke.
46:20 Exactly.
46:22 Yeah.
46:24 Yeah.
46:25 I actually often do the slow way or the non-obvious way.
46:30 The proposed way.
46:30 Yeah.
46:31 X equals X plus one just to make it more obvious to people reading it sometimes.
46:35 Yeah.
46:36 Yeah.
46:36 No, I agree.
46:37 Yeah.
46:38 At least it's not C++ with X, plus plus X.
46:41 I love that.
46:43 No, no.
46:44 We should have that.
46:46 I'm okay with X plus plus, but not that also plus plus X.
46:50 Oh, the pre-increment.
46:51 Yeah.
46:52 The pre-increment.
46:53 The slight.
46:53 That's weird.
46:54 Yes.
46:55 Exactly.
46:55 Exactly.
46:56 But I could go for it.
46:57 X plus plus.
46:57 Come on.
46:58 All right.
46:58 Well, Julia, thanks for joining us this week.
47:01 And Brian, thanks as always.
47:02 Oh, it was a pleasure.
47:03 Thanks, Julia.
47:03 Yeah.
47:04 Bye.
47:04 Bye.





