#261: Please re-enable spacebar heating
Watch the live stream:
About the show
Sponsored by us:
- Check out the courses over at Talk Python
- And Brian’s book too!
Special guest: Dr. Chelle Gentemann
Michael #1: rClone
- via Mark Pender
- Not much Python but useful for Python people :)
- Rclone is a command line program to manage files on cloud storage.
- Over 40 cloud storage products support rclone including S3 object stores
- Rclone has powerful cloud equivalents to the unix commands rsync, cp, mv, mount, ls, ncdu, tree, rm, and cat.
Brian #2: check-wheel-contents
- Suggested by several listeners, thank you.
- “Getting the right files into your wheel is tricky, and sometimes we mess up and publish a wheel containing __pycache__ directories or tests/”
- usage:
check-wheel-contents [[HTML_REMOVED]] <wheel or dir> - ex:
(venv) $ pwd /Users/okken/projects/cards (venv) $ check-wheel-contents dist dist/cards-1.0.0-py3-none-any.whl: OK Checks
- W001 - Wheel contains .pyc/.pyo files - W002 - Wheel contains duplicate files - W003 - Wheel contains non-module at library toplevel - W004 - Module is not located at importable path - W005 - Wheel contains common toplevel name in library - W006 - __init__.py at top level of library - W007 - Wheel library is empty - W008 - Wheel is empty - W009 - Wheel contains multiple toplevel library entries - W010 - Toplevel library directory contains no Python modules - W101 - Wheel library is missing files in package tree - W102 - Wheel library contains files not in package tree - W201 - Wheel library is missing specified toplevel entry - W202 - Wheel library has undeclared toplevel entryReadme has good description of each check, including common causes and solutions.
Chelle #3: xarray
- Where can I find climate and weather data?
- Binary to netCDF to Zarr… data is all its gory-ness
- Data formats are critical for data providers but should be invisible to users
- What is Xarray
- An example reading climate data and making some maps
Michael #4: JetBrains Remote Development
- If you can SSH to it, that can be your dev machine
- Keep sensitive code and connections on a dedicated machine
- Reproducible environments for the team
- Spin up per-configured environments (venvs, services, etc)
- Treat your dev machine like a temp git branch checkout for testing PRs, etc
- They did bury the lead with Fleet in here too
Brian #5: The XY Problem
- This topic is important because many of us, including listeners, are
- novices in some topics and ask questions, sometimes without giving enough context.
- experts in some topics and answer questions of others.
- The XY Problem
- “… You are trying to solve problem X, and you think solution Y would work, but instead of asking about X when you run into trouble, you ask about *Y.”
- Example from xyproblem.info
- [n00b] How can I echo the last three characters in a filename?
- [feline] If they're in a variable: echo ${foo: -3}
- [feline] Why 3 characters? What do you REALLY want?
- [feline] Do you want the extension?
- [n00b] Yes.
- [feline] There's no guarantee that every filename will have a three-letter extension,
- [feline] so blindly grabbing three characters does not solve the problem.
[feline] echo ${foo##*.}
Reason why it’s common and almost unavoidable:
- Almost all design processes for software
- I can achieve A if I do B and C.
- I can achieve B if I do D and E.
- And I can achieve C if I do F and G.
- … I can achieve X if I do Y.
- Almost all design processes for software
- More important questions than “What is the XY Problem?”:
- Is it possible to avoid? - not really
- Is it possible to mitigate when asking questions? - yes
- When answering questions where you expect XY might be an issue, how do you pull out information while providing information and be respectful to the asker?
- One great response included
- Asking Questions where you risk falling into XY
- State your problem
- State what you are trying to achieve
- State how it fits into your wider design
- Giving Answers to XY problems
- Answer the question (answer Y)
- Discuss the attempted solution (ask questions about context)
- “Just curious. Are you trying to do (possible X)? If so, Y might not be appropriate because …”
- “What is the answer to Y going to be used for?”
- Solve X
- Asking Questions where you risk falling into XY
- Also interesting reading
- Einstellung effect - The Einstellung effect is the negative effect of previous experience when solving new problems.
Chelle #6: kerchunk - Making data access fast and invisible
- S3 is pretty slow, especially when you have LOTS of files
- We can speed it up by creating json files that just collect info from files and act as a reference
- Then we can collate the references into MEGAJSON and just access lots of data at once
- Make it easy to get data!
Extras
Michael:
- Xojo - like modern VB6?
- 10 Reasons You'll Love PyCharm Even More in 2021 webcast
- Users revolt as Microsoft bolts a short-term financing app onto Edge
Chelle:
- Why we need python & FOSS to solve the climate crisis
Joke: Spacebar Heating
Episode Transcript
Collapse transcript
00:00 Hello and welcome to Python Bytes, where we deliver Python news and headlines directly to your earbuds.
00:04 This is episode 261, recorded December 2nd, 2021.
00:09 And I am Brian Okken.
00:11 I'm Michael Kennedy.
00:12 I'm Shell Genteman.
00:13 Welcome, Shell. Could you let us know a little bit about yourself?
00:16 Yeah, I'm a research oceanographer.
00:19 So I study the sea from space.
00:21 And I've been doing oceanographic research for NASA for a little over 20 years.
00:26 I do almost everything using satellite data.
00:29 So I never have to leave the comfort of my, used to be office, but now office at home.
00:35 That sounds so fascinating.
00:36 Is it fun?
00:37 Super fun.
00:38 Cool.
00:39 It's like math and physics and computers all mushed together.
00:43 It's like all my favorite things.
00:45 And oceans.
00:46 Yeah, it's fantastic.
00:47 And oceans.
00:48 Yeah, that sounds like such a cool job.
00:50 Welcome to the show.
00:51 Well, Michael, what do you got for us to start?
00:53 Well, let's talk about our clone.
00:58 So this one was sent in to us by Mark Pender.
01:01 Now, our clone itself, I believe it's written in Rust or something.
01:06 It's not Python.
01:07 So the story here is not, oh, here's a cool thing created with Python.
01:11 But it is a cool library that I think will be useful for Python developers.
01:16 Okay.
01:16 So this our clone thing syncs your files to cloud storage.
01:21 Let me basically see my summary.
01:23 So imagine you wanted to put some files in AWS S3, or you wanted to store something in Azure blob storage, or there's actually 40 different places where this can go.
01:34 So like Backblaze, Backup, Box, Citrix, ShareFile, Dropbox, Google Drive.
01:42 Let's see.
01:43 Some stuff with OpenStack, KeyCloud.
01:45 All these different places and formats, even just web dev and whatnot.
01:50 So if you want to either read or write files to that location, what you can do with our clone here is it will basically mount those different locations as just something on your hard drive.
02:01 So if you want to write to S3, you can just write to a file with Open slash S3 slash wherever it goes, and then write to it with Python or set up some kind of cron job that moves stuff.
02:13 So if you're trying to move like large data for data analysis up to the cloud, so then you can connect it to a notebook, or you're trying to move files that are the back end of your website or your API through S3 or somewhere,
02:27 then you can just copy files over sync different locations, like I said, mount it as a drive.
02:34 And it has a lot of cool support for things like if the file transfer gets interrupted, it'll fall back to the last one that was working and then continue uploading.
02:44 So it can be kind of interrupted and unstable and whatnot.
02:47 I think this is so cool.
02:48 It was just like, you know, when I first moved to the cloud, it was so frustrating having to figure out whether I was using S3 or the, you know, the Google commands or the Amazon commands.
02:59 And all I wanted to do, get my data to where I could use it.
03:04 I am so, so with you.
03:05 And sometimes it's like, well, how do I copy files here?
03:08 Well, here's our API.
03:09 Like, I don't want an API.
03:10 I want to go to the Finder or to the Windows Explorer and draggy dropy the file.
03:14 Can I do that?
03:15 They're like, no, no, no, you can't do that.
03:17 No way.
03:17 You can run our app maybe.
03:18 Yeah.
03:19 So this is, you know, in theory.
03:21 This is so cool.
03:21 Yeah.
03:22 I'm glad you like it.
03:23 That's awesome.
03:24 I think it'll allow people to move data around from, especially it seems relevant to scientists who need to put a bunch of data in the cloud and run it.
03:32 But then they might be want that data locally and keep it in sync and stuff.
03:35 And it's really frustrating when your expertise is in something else.
03:39 It's not in computer science.
03:40 And like everything I pick up is because I'm only forced to learn it.
03:43 And I don't want to learn the Amazon API and I don't want to learn the Google API.
03:47 This like gives me maybe one tool that I can just be cloud agnostic and move my data around in a way that I'm already comfortable with.
03:54 Yeah, I agree.
03:55 Yeah.
03:55 Here's the thing I was looking at.
03:57 Yeah.
03:57 So the virtual backends wrap local and cloud file systems and apply encryption, compression, chunking, hashing, and joining.
04:04 And it looks after your data.
04:06 It preserves the timestamps, stamps, verifies checksums all the time, transferred over limited bandwidth, intermittent connections.
04:13 It can be restarted.
04:16 It checks the integrity of your files, all those kind of things.
04:18 So, you know, like if you're out, I know you don't leave the house anymore, but if you're out doing research and like on a boat and you needed to like, you had this rickety connection, you know, maybe you could get stuff uploaded well this way.
04:30 So I think it's neat.
04:31 How do you like configure it?
04:32 You have to put in all your cloud stuff.
04:35 I suspect you, when you set it up, you have to give it like, let's see, it's for your Amazon.
04:40 That's Amazon drive.
04:41 I forgot that that existed.
04:42 Okay.
04:42 Let's see.
04:47 Yeah.
04:48 You've got to give it like your, your AWS keys and stuff, of course.
04:51 But yeah, they have a whole configuration section on what you give it here to set it up.
04:56 It looks like you create a config file for it, I think.
04:58 But yeah, pretty neat.
05:00 Brian.
05:01 Yeah.
05:01 Brian, what do you think?
05:02 Well, so I'm trying to figure out like, even for something, for a mental model, is this like a Dropbox without version control or is it a completely different space?
05:12 Well, I mean, it does have some tie-ins to there, right?
05:16 It's got like Backblaze and things like that, which is just a pure backup system.
05:22 I think it's just trying to match like, how do I move files around to the cloud?
05:26 And you can also, you can move it between the cloud, right?
05:29 You can mount two places and copy from one to the other.
05:31 Like I can copy from Citrix share file over to box, neither of which I really know how to do.
05:36 Yeah.
05:36 Oh, it even has Dropbox as one of the configs.
05:39 Yeah.
05:40 Yeah.
05:40 But different.
05:41 This is actually pretty cool.
05:43 I like it.
05:44 Yeah.
05:44 Very cool.
05:45 Let's see.
05:46 Kim out in the live audience says, I like this.
05:49 Very few people really need to know or care that S3 doesn't have real files and directories, for example.
05:54 And Sam says, it's funny.
05:56 My group was just talking about how to transfer a huge amount of training data to our compute resources earlier today.
06:02 I'm guessing that's machine learning training.
06:04 Very cool.
06:04 When you still have to go to Amazon or Google and set up the bucket, right?
06:09 So you're not spared that particular pain.
06:12 Just like try to click public until it's public, but not too public.
06:16 That's my approach.
06:18 You still have to do that.
06:20 But this seems like a really nice solution.
06:23 Yeah, for sure it does.
06:25 I guess over to you, Ryan.
06:26 Yeah.
06:27 So this has been suggested several times by several listeners.
06:31 So thank you, everyone that sent this in.
06:34 Oh, I'm on the wrong thing, aren't I?
06:36 I wanted to talk about check wheels.
06:38 So check wheels are check wheel contents.
06:43 So the idea around it is that there's...
06:47 So I'm often using Flit, and it kind of does all this for me.
06:51 But there's other backends that you can use for building wheels.
06:55 And if you configure something wrong, it might get the wrong stuff in there.
07:02 So by wrong stuff, you might have like a PyCache in there, or you might deliver your tests with your wheels,
07:10 and that's just extra space.
07:12 You don't necessarily need that.
07:14 Maybe your documentation should be there, but maybe it shouldn't be, depending on that.
07:18 I don't think that...
07:19 Actually, I went on a tangent with the documentation.
07:21 I don't think this checks for that.
07:22 But so there's a...
07:24 It's just a pip installable tool, and then you can run check wheel contents.
07:27 And you can give it a wheel, but wheels are often long.
07:31 So I just...
07:31 When I've been trying it out, I've been just giving it my dist directory,
07:35 and it just looks all the wheels in there and checks things.
07:38 So what does it check for, though?
07:39 So it's checking for things like making sure that you don't have any PYC or PYO files in there
07:45 because you shouldn't have those in your wheels.
07:46 Checks for duplicate files, because maybe you've got, I don't know, copies your directories or something.
07:51 And there's actually, I don't know, like 10, 12, 13, 14, 15 checks or something like that.
07:58 I'm counting really quickly.
07:59 But there's...
08:00 What I really love about...
08:02 One of the things I like about this is there's a lot of things that you...
08:06 Like if you configured it totally wrong and your wheel's empty, it'll check for things like that.
08:10 And yeah, you probably could test this and try it, but it would be nice to actually have something in your pipeline
08:17 to automatically check for these things.
08:20 And it's really fast.
08:21 The other thing I like is the readme for this project lists of...
08:26 Has a very good description of all the checks and why something like that could go wrong.
08:32 So if, for instance, you happen to have your tests in there, but you don't want them in there,
08:38 how do you fix that?
08:40 Or it also says, if you actually do want your tests in there, how to go about putting it in there
08:45 so the check passes.
08:46 So interesting project.
08:48 Yeah, this looks really neat.
08:49 I think if you're going to be creating a package, you definitely don't want to be releasing things
08:54 that are not intended to be in there.
08:57 I was looking through it.
08:59 I wonder if it's possible to say, you know, check for certain files, make sure that they don't get in there.
09:05 Like I'm thinking like a settings file that has some sort of key, like an AWS key,
09:10 like we were talking about or something.
09:11 But nice.
09:13 Can you...
09:13 So I don't make lots of packages.
09:15 So what's the wheel?
09:17 When you're using that term, what does that mean?
09:19 It's the thing that you pip install.
09:23 It's the...
09:24 They used to be just tarballs.
09:26 It used to be tar, the JZs and whatever.
09:28 But what we do now for the most part is, or hopefully, is wheels are not...
09:36 If it's just pure Python, it'll be the same for everything and hopefully it will be.
09:42 But it can also specify that it runs on Python 2 or 3 and that some of those sorts of things
09:47 can be built into the name and what operating system.
09:51 Because if you're building on, like say, just simplifying the world, a couple versions of Unix
09:58 and Linux and maybe Windows and Mac and then also the new Mac with the different architecture,
10:09 those will all be different wheels.
10:11 But when you...
10:12 So when you pip install it, PyPI and pip will download the correct wheel
10:16 for your operating system.
10:17 And that makes it so that when you're installing something, none of...
10:22 You don't have to compile anything.
10:23 It just brings it all down.
10:25 So it's a cool format.
10:26 Yeah, it's especially important for the scientific community because there's so many weird libraries
10:32 that have to get compiled with things like Fortran, as we were joking about.
10:36 And so wheels will basically contain the pre-compiled version so you don't have to have
10:40 like a Fortran compiler on your machine to pip install it or whatever.
10:43 It just downloads and unzips really quickly without all that steps.
10:47 I was told a simple mental model of the difference of old and new is the old style
10:54 with setup tools and stuff would often have a whole bunch of stuff that you download
10:59 and then you run setup to like build some things and redo things.
11:03 Whereas a wheel is closer to mostly just a zip file that just unpacks things
11:09 and throws it in your site packages.
11:11 Nice.
11:12 And Sam also adds, you can also package extension modules in wheels, which is their greatest strength.
11:18 Very cool.
11:18 Cool.
11:19 All right.
11:20 Brian, is that it for the check wheel contents?
11:22 Yeah, I'm done there.
11:23 Right on.
11:24 All right, Shell, take it away.
11:26 All right.
11:27 So I thought we would talk a little bit about weather and climate data and Python
11:33 and we're really trying to get more Python programmers involved in weather
11:38 and climate research.
11:39 And the data, I think, it used to be really hard to get weather and climate data.
11:44 It was in these really weird, obscure formats that only scientists knew how to read
11:48 and they only wrote Fortran routines to read them.
11:52 But now with Python, it's becoming really, really easy to get these data.
11:55 So the first thing is like, where do you get the data?
11:58 So I'm just going to show the open data at Amazon, at AWS.
12:02 But really, you know, Google has the equivalent in the Earth Engine and Google has all sorts
12:08 of open data sets.
12:08 And that means that they're free egress.
12:11 So most of these you can get, you know, you can access data for free.
12:14 And Microsoft has the planetary computer and they're building up the same thing.
12:18 And like you can see lots of people are putting data on here.
12:22 Like NASA has a Space Act agreement.
12:24 There's the NOAA, which is our weather agency, the big data program.
12:27 And so like you can look for data.
12:31 And one of the biggest data sets that I work with is ERA-5.
12:36 And if you just sort of type in here and it brings up the data set and you can click on that
12:41 and see they have it in these two different formats.
12:43 So one is SAR and one is NetCDF.
12:46 And most people in sort of data science work with, you know, SQL databases
12:52 or maybe they're doing CVS files or tabular data.
12:56 So weather and climate data is a little different because it's three-dimensional.
12:59 And so there's these different data formats and really almost all of the weather and climate data
13:05 now is currently in this NetCDF format.
13:07 The goal is let's just write a Python library and make it so you don't care about the format, right?
13:13 The data formats, the people who produce the data should care about it.
13:16 But as a user, what we want is we want anybody to be able to use it and do anything
13:20 they can think of.
13:21 And so that's this sort of X-Array.
13:23 So X-Array is a Python library that is designed for sort of three-dimensional
13:30 structured data.
13:32 And all the data has labels and it has these things called data sets so that it organizes
13:37 your data for you and to read it you just sort of say open data set.
13:41 Nice.
13:42 And it understands these formats?
13:44 Yeah.
13:45 And like I'm going to bring up a little example here but this ERA5, I mean this is like
13:50 I think it's 35 terabytes of data.
13:53 So I took this off of the AWS.
13:57 why did it take it off?
13:58 I ran it on AWS and I subsampled it.
14:00 Because where are you going to put it, right?
14:02 Yeah.
14:02 I mean it used to be that like to get this data set you had to write a script
14:08 and then you would download it for like three months.
14:10 And now it's just on AWS which is like mind-blowing, right?
14:14 Like I log on and a few minutes later I actually have access to all this data
14:18 which is so cool.
14:20 So like with X-Array I'm going to run this cell and basically I just import X-Array
14:25 as X-Array to read the data I just say like open data set.
14:29 That's it.
14:30 And it figures it out.
14:31 And it'll read almost it'll read a lot of different formats and it just has your data.
14:38 And so this is like a really big data set and it tells you all about it and you can look
14:44 at the different data that it has.
14:46 and you know sort of the goal with this is to make it really really easy
14:50 for anybody.
14:51 Like let's say you want to look at you know sales patterns in San Francisco
14:55 or you want to work at ship traffic or you want to look at how weather is evolving
14:59 at your location.
15:01 Like you don't need to know about the data anymore.
15:03 Yeah.
15:04 Fantastic.
15:04 Just know how to work with NumPy like X-Array stuff in your notebook and that's all
15:10 you got to know.
15:11 Yeah.
15:11 It's all built around pandas and NumPy and like if you want to like let me find
15:19 a really easy example like what if I want to plot the data set.
15:24 You know I just type dot plot right?
15:26 Oh wow.
15:27 And then it like labels everything and you understand what you're looking at
15:31 and what day it is and you can use cell and ice cell and just sort of like pandas.
15:36 It almost looks like an ocean just right there.
15:38 It's yeah.
15:39 Longitude and then I guess temperature right?
15:42 Yeah.
15:42 And so this is like you just typed plot and it actually tells you exactly
15:47 what you're doing and what it's plotting and what the color bar so what do these
15:51 different colors mean?
15:52 And you know you could do a spatial plot like this where you do it in time
15:58 or let's just pick a particular latitude and longitude and the nice thing
16:04 is that you can actually just tell it your latitude and longitude and you can use
16:08 Google Map to look up your latitude and longitude and then plot it and it says
16:12 oh I'll make a time series.
16:13 That's pretty cool.
16:14 Wow.
16:15 Yeah I remember just struggling so much getting into programming and having to work
16:19 with custom file formats out of like research projects you're like what do you mean
16:23 I have to read this binary file?
16:25 This is going to be so hard.
16:26 Okay here we go.
16:27 Yeah and then like you wanted to read a different binary file like start from scratch
16:33 write all that code again and like X-ray sort of took all of the back end work
16:38 that all the people at the data archives did with like getting everything
16:41 in the same format and labeling all the data nicely it sort of took all that work
16:46 and just said well we'll write one library that builds on all of that and can read anything.
16:49 Yeah awesome great recommendation.
16:51 A couple of pieces of real-time follow-up Sam Morley out in the live stream
16:56 says X-ray is great I did an example of using it to open a net CDF file in my book
17:02 and I'm learning about his book Applying Math with Python Practical Recipes
17:06 for Solving Computational Math Problems Using Python Programming and its Libraries
17:10 that's awesome.
17:11 That looks like fun actually.
17:12 Yeah it does.
17:13 Yeah and X-ray linked to like SciPy and it has all a lot of statistics and math built into it
17:20 so you can actually compute trends in one line and all of that.
17:23 Yeah nice.
17:24 Cool.
17:24 I also have one other piece of follow-up here Brian I don't want to panic you all
17:29 but right here in Portland we have Panic the software company and I just want
17:34 to give a quick shout out to this thing called Transmit here.
17:36 This is what I actually use to get stuff up into and out of S3 and it also
17:42 will let you talk to Backblaze, Box, Dropbox, Azure, Google Drive all these places
17:47 as well and it's basically like an old school FTP program where like on one half
17:52 it has your computer and the other half it has whatever cloud storage is that you're
17:58 working with there and maybe you could even put the other half not just your computer
18:00 but somewhere else as well.
18:01 So if you want just like a UI not something like R clone but just a UI I'd strongly recommend
18:07 this thing.
18:07 They don't sponsor the show or anything but I definitely love it.
18:10 I use it all the time.
18:11 Neat.
18:11 Neat.
18:12 All right.
18:12 Am I up next actually?
18:14 I guess I am.
18:15 Yeah.
18:16 I think so.
18:16 I am.
18:17 I am.
18:17 Number four would be I want to talk about this announcement from JetBrains
18:23 being one of the bigger tool companies tool builders for the Python world.
18:28 They came up with this thing called JetBrains remote development and buried at the end of this
18:32 is actually what I think is the lead got quite buried here but we'll see.
18:36 So they introduced something that I was not aware of called remote development.
18:42 So the whole idea of this is basically what if instead of running like PyCharm
18:48 this works for any of the IntelliJ stuff but let's say PyCharm instead of running PyCharm
18:52 locally on your machine you could just give it an SSH destination let's say
18:57 and it will go over there and run PyCharm the server or the sort of logic bits over there
19:04 but just have a light front end to your computer here.
19:08 so like a lightweight if you're on some really wimpy laptop and you wanted to
19:13 access like a better server at work or in the cloud or in like Shell's example
19:19 near some massive data set instead of far away from some massive data set
19:23 so you could just directly talk to it and so on.
19:25 So yeah it's super cool you just basically give it some SSH thing.
19:30 They also say it's good for things like if your laptop gets stolen what data goes with it
19:36 you know if you just keep the data somewhere else right then like just revoke
19:41 the SSH key and nothing's nothing's bad.
19:43 You can also set it up so that it'll create pre-configured environments like
19:47 when you connect to it it'll automatically give you something with like let's say
19:52 Conda setup and all the right libraries pre-installed and that one weird
19:56 C thing you gotta you know apt install to make sure it works like it starts with that
20:00 just all configured from different things.
20:02 So anyway that seems all pretty cool to me.
20:03 I thought it was pretty neat.
20:05 That does look neat.
20:06 I think it's free if you set up your own server but then I think it costs money
20:10 if they provide you the server right so kind of just like firing up a VM
20:14 for you on your behalf.
20:15 All right you ready for the buried lead?
20:17 Scroll, scroll so here you can see this is an example of just like connect over SSH
20:21 or you can go to JetBrains space and they'll create one for you right but here's the buried lead
20:26 they announced this thing called JetBrains fleet which is as far as I can tell
20:30 unrelated I think it'll connect one of these things but is another thing
20:35 so if you click down at the bottom or is there something about learn more
20:38 and if you go to this it is a complete rewrite of the whole IDE story over at JetBrains
20:45 and basically think VS Code but from JetBrains.
20:48 Yeah I'm interested in watching this and I just heard about this last week
20:52 and they're doing it an invite only sort of not invite only but you have to like
20:58 early access get approved sort of thing yeah get approved sort of thing they're trying to limit
21:02 basically limit the feedback so that they can deal with the feedback so yeah
21:07 so it's like super fast to open it doesn't have a project structure in the same sense
21:12 that like PyCharm or IntelliJ would it just opens files and it doesn't even have
21:17 the IDE features unless you click this little like make it smarter button
21:21 and then it'll like fire up all the high-end stuff that takes you know five seconds to start
21:25 the other thing that's cool as you can see on the screen right here is there's like
21:28 three people typing all at the same time actually no there's five people typing
21:32 so it's like Google Docs where you can all like collaborate on it in parallel
21:36 like right within it so I think those are all super neat developments in the whole editor space
21:42 which you know we all write a lot of code and kind of deal with these tools
21:45 editor as a service is something that is happening and I'm it it is a hard thing
21:51 for me to wrap my head around because my brain thinks I want all my editor stuff
21:55 locally but there's a lot of times where you don't so yeah I just like the group
21:59 Cody yeah I know I think that's really neat as well I think that would be
22:02 really valuable to some people on teams instead of you know we've all been
22:06 in those screen share meetings like no could you go over there could you type this
22:09 no no no no not after that but inside the parenthesis it's like please no
22:13 that's exactly what's going to do it to the left no a little bit more to the left
22:19 exactly and so wait not a friend yeah yeah let's see a bunch of people out there
22:27 really like this RJL and Sam and so on but Kim has an interesting comment
22:34 we've come full circle ish back to talking to the one mighty mainframe over a lightweight
22:39 terminal circa 1985 or you know for me 90 like 95 and like X11 Xwindows like
22:47 is your Xwindows set up so you can talk to the server yeah yep I'm just thinking the same thing
22:51 yeah definitely but these are interesting ideas you know for me personally
22:56 I love to use PyCharm for working on projects but if I've got just a JSON file
23:01 or even a Python file and I just want to look at the file I probably won't open it in PyCharm
23:05 because it's going to create all this project goo that's going to be stuck in that folder
23:09 and it's going to expect it's going to complain there's no interpreter I just want to look at it
23:12 you know and so tools like this I think are going to be really neat yeah
23:15 yeah and Brandon's support suggesting something crazy out there like mobs
23:20 might run in and no mob programming where you like working as a group I think it's fun
23:24 yeah and I'll be we should play with this though yeah I think it'd be fun to see
23:31 what all the interactions feel like and stuff I totally agree yep alright
23:36 over to you you know I'm trying to remember how I came across the XY problem
23:41 and and I was doing some research last week and and I think I was down some rabbit hole
23:48 of link follow link follow link sort of thing and I ran across this problem
23:52 and the XY problem and probably everybody else knows about this already but I
23:57 it was the concept was new to me and I yeah I don't know the XY problem okay
24:02 and I studied math come on well so it isn't really that mathy but so the XY problem
24:11 is essentially you is you're trying to solve problem X and you think of a solution Y
24:20 that would help work to solve that and you you get down to trying to solve
24:25 all the details of Y and you get stuck so you ask about Y but what you're really
24:30 trying to do is X and it's that's sort of nebulous an example kind of highlights it
24:35 so and we've got this example in the show notes that I pulled out of one of the links
24:40 is how do I if somebody asks how do I get the last three characters of a file name
24:46 and somebody says oh you just like do and this is a shell command you just
24:50 do like if it's in the variable foo you just do dollar curly bracket foo
24:56 and then do a colon and then negative three just grabs the last three characters
24:59 but also why do you want the last three characters is it because you are trying to do
25:06 trying to pull off the extension somebody goes yeah that's what I'm trying to do
25:10 and they're like oh well then you don't want the last three characters because it might be a two character
25:14 or a four character extension so teach them how to do the real problem and
25:19 in one of the I'm going to link to a couple a couple like forum answers and stuff
25:25 in there because I think it's interesting there's a lot of verbiage around
25:30 the XY problem that sort of blames the asker for asking a stupid question
25:35 and I think it's important to not do that because we do this all the time
25:40 we break problems in software we break problems down if I want to do A then I need to do B and C
25:45 but to do B I got to do D and E and then and then also F and G and then way down
25:52 into the rabbit hole I get to get into the X and Y problem but how far back
25:57 do you back up to give enough context to somebody else so it's hard to avoid
26:03 you'll run into it and then I I really like there was one forum that had
26:07 some great advice both on asking questions and on answering questions so when asking questions
26:14 state the problem that you're trying to solve but also state the higher level thing
26:19 that you're trying to achieve if appropriate and then also how that fits
26:24 into the wider design and then it also brought up if you've thought of other solutions
26:30 that you've eliminated for some reason or another go ahead and list those
26:36 because somebody might give you one of those as an answer and you've already
26:40 eliminated that so give the reason why and then I think what's most important
26:44 is giving answers to what XY problems or giving answers to problems because
26:49 although I think everyone that's on this podcast and also listening
26:54 is probably an expert in some fields and a novice in other fields so we're going to be
26:59 on both sides of the fence so when answering questions and you think oh somebody's just
27:04 trying to get the extension I'll just tell them how to do that that's not
27:09 necessarily helpful so a great there's a great three-part thing to do and our example
27:14 follows those is go ahead and answer the question directly but also ask some questions
27:21 about the problem say just curious why are you trying to do this is it because
27:26 you're trying to do this other thing if so you're the thing I just told you
27:30 might not be appropriate and then once you figure out really what the real
27:34 problem is then you can help and give the final answer so it isn't helpful
27:41 to just say oh you're probably getting the extension go ahead and just do that
27:44 anyway I thought this was an interesting thought process around answering
27:49 and asking questions yeah absolutely it seems to be very relevant to stack overflow
27:54 type places because you're going to pose you're looking for help you say
27:57 I'm trying to do this but a lot of times people will and it'll give you very specific
28:01 answers and the answer could be well why don't you do this library that already understands
28:06 that format like Shell mentioned earlier like why don't you use x-ray instead of
28:10 trying to understand how to parse this thing just use that oh well that's
28:15 way better thank you I see that a lot on stack overflow that exact it reminds me
28:21 also of my like when I went to school and you're trying to ask a question
28:25 to your professor or to get help on anything right you're like this is my
28:28 problem what really is your problem please tell me about it and like that's
28:33 that's what you're asking right like tell me what the actual problem is and if you
28:37 can do that clearly you're going to get a much better answer yeah absolutely
28:42 and a lot of people just don't I mean it's also just a different perspective
28:46 thing they know that they know they have the toolbox of things they know
28:49 how to solve and ways they've solved them and if a new problem and this is a
28:54 related thing is people don't sometimes don't even think that there's a really
28:58 simple solution out there like oh that tool you're using it already has a
29:02 flag that does exactly what you want but you didn't know the flag was there
29:06 so it took me when I started learning Python and I was so used to Fortran
29:12 77 where there was never any help they just don't even try that when I started
29:17 learning Python it took three or four months before I finally just said anything
29:21 I want to do someone has done better and they are out there I just have to
29:26 find out how to ask the question correctly to find them because it's true
29:31 like everyone is most people have tried to solve the same problem there's
29:35 someone out there who's worked on the same problem in all likelihood yeah
29:39 there's so many libraries with pip or Conda that you can if you knew it existed
29:45 exactly yeah exactly all right okay so I guess I'm am I next you are next
29:52 okay so what I wanted to show this library that is called Kerchunk it's a great
30:01 name yeah brand new so can you see my snail screen yeah yeah so we had this
30:07 problem where like as Noah and NASA everyone starting to throw all these
30:12 net CDF files or all these different files onto the cloud and then it turned
30:17 out that access in S3 was really really slow and so people got really frustrated
30:23 because like the cloud is supposed to be fast right this is going to transform
30:27 science we're going to do it better now that's the promise yeah that's the
30:31 promise but the grass isn't always greener so this is this library that I
30:37 think has really maybe some broad applications it's being developed right
30:41 now and the idea behind it is like we have all these data formats that we're
30:47 sort of stuck with lots of data but sometimes it's slow on S3 so is there
30:51 a way that we can fix this and the idea is that you create a reference file
30:57 system and so you do this by going to each of your files and just taking
31:02 the data that you need for that file like just the metadata so like what
31:06 size is it what its dimensions and coordinates are what variables does it
31:10 contain so you just take those little bits and pull them out into a JSON
31:14 file and so then you have this reference file that just contains the important
31:19 information but it's really small and so that makes it faster to access and
31:24 then you construct this JSON file and I have some benchmark tests in here
31:29 but then you construct a mega JSON file and you basically virtually aggregate
31:35 all of your data so that in one call again you can just get access to everything
31:41 and nice because you might not need actually the data you might need to know
31:46 what time frame is this so do I need to read in that file or not right yeah
31:51 and in some ways because you're doing a lot of what one of the things with
31:56 x-ray back to that other library is that does the lazy loading so like this
32:00 is a 16 terabyte data set that I'm loading here but I'm just loading the
32:05 data about the file I'm not actually loading any data until I need to touch
32:09 it and so I can load this giant data set in a little bit over less than two
32:15 minutes by doing this virtual aggregation with KrippChunk and so all it's
32:19 doing is it's reading these aggregated JSON files and right now it works
32:25 for three or four different types of data sets so if you have big collections
32:29 of data that are going on to S3 they have lots of different little files
32:35 this is a way to sort of virtually aggregate them into one big data set that
32:40 you can then subset oh that's really cool it seems like this is one of those
32:45 that comes as part of the FS spec project which we talked about pretty recently
32:49 as well yeah and so this is part of FS spec and it's kerchunk it was just
32:55 released and it's a unified way to represent compressed data formats and
33:00 it creates this virtual data set so that's where it's located yeah super
33:05 cool see Kim has a question do you keep the individual JSON files with the
33:09 data you can so the nice thing about this the data can be anywhere and again
33:15 this is idea to make data invisible and easy you can either create them yourself
33:25 and just keep the little JSON files public and then you just make the one
33:30 aggregated JSON file public and anybody could use that JSON file to access
33:36 the data this way fantastic that looks really helpful for working with large
33:40 data yeah I think it's cool it looks awesome all right Brian does that bring us
33:44 to the extras yeah I guess it does how many extras you got today I just have one
33:51 entertaining extra I thought as some people have amusingly noticed I am attempting
33:57 to grow my hair out and I went to Florida last week and it's very humid in
34:03 Florida and I looked like a cotton swab it just like poofed anyway that's
34:10 it was amusing to me but you should have sent us some pictures or something
34:13 yeah maybe those are the pictures you don't really went out there but yeah
34:17 yeah so I wish I could have seen like yeah because I was at Disney World
34:21 and we were doing like rides and stuff and I really wish I could have seen
34:23 like the flowing hair on the roller coaster or something like that perfect
34:30 I I nice let's see what shells got first okay so what are extras just something
34:38 that we did last week well just whatever you want to also just give a shout
34:41 out to while we're here before we call it I think I'm pretty good I'm really
34:46 excited like NASA starting a big transformation to open science which is
34:50 exciting they started a new they announced just last month a new 40 million
34:55 initiative to try and help scientists move to open practices and Python is
34:59 a big part of that because a lot of this was the open community that Python
35:04 helped develop over the last decade and all of the tools that now is making
35:09 it's not just science easier it's making it easier for more people to participate
35:13 in science I think there's a lot of synergies and similarities between the
35:18 scientific goal and open source yeah because it used to be like scientists
35:26 like you would share your knowledge right you'd publish paper yeah and that
35:30 was it and if you like that's what graduate like I remember in graduate school
35:33 you would go through and they'd be like okay derive the equations in this
35:36 paper because they wouldn't show you all the steps and you would do that
35:40 and if you wanted to code it up you would just open up a new window and start
35:44 coding and now you know people are starting to publish their code so that
35:48 you can actually reproduce their results and then build on them and move
35:52 faster and the whole reproducible science thing as well fantastic yeah awesome
35:58 Sam in the audience says yes more open reproducible science is great for
36:03 everyone yeah all right I got some extras as well as you can imagine surprise
36:08 I don't remember when I was going on maybe this was actually in talk python
36:13 but I was going on and on that visual basics six just the I want to drag
36:17 a few things on the screen and write a little bit of code made it so easier
36:19 for people to build apps you know what Kojo is this replacement thing so
36:30 if you're trying to build some desktop apps and you want to try to work on
36:42 some integration between those things but there's a little demo where in
36:46 six minutes they build a web browser which is kind of neat so very visual
36:51 basic feeling so is it Python it's not Python no it's not Python it's more
36:56 VB6 feeling I don't know if it's actually VB6 which is even worse it's sort
37:01 of kind of but not exactly I just did a webcast 10 reasons you love high
37:05 charm even more in 2021 with jet brains and Paul ever we did five reasons
37:11 so I'll link to that people care about that and then who doesn't love a little
37:15 good tech shock and awe and being I don't know outrage I guess is the word
37:22 I'm looking for so Microsoft edge is this browser that's sort of Chrome based
37:27 and they just announced like a Linux version and it runs on macOS which all
37:31 these things surprised me and there was getting a lot of traction and there's
37:35 this whole thing where Microsoft the team at edge just added a buy buy buy
37:42 now pay later thing built into the browser from some third party company
37:47 not as an extension but integrated into the browser that you can't not get
37:52 when you go shopping it says would you like to use this for payment program
37:57 it's almost like adding payday loans baked into the browser it's insane I know
38:04 it's such a bad idea so there's an article it says users revolt this all
38:16 feels extremely unnecessary for a browsing experience and the comments are
38:21 you go to the comments they are really there's 256 comments which is an awesome
38:27 number of comments for the moment but there's just almost nothing but why
38:32 why is it this is unbelievable to me I can't believe this is so it makes
38:38 it feel so shady and trashy right like the next thing you're going to do
38:41 is get like bail bonds offerings inside your browser if you get your browser
38:46 just weird stuff so anyway I thought people might enjoy just reading through
38:50 this and taking a little bit of that in it it must work right because we all
38:56 have this experience where you I mean there's been this has been going on
38:59 for 20 years like with their browser remember it used to install all this
39:03 stuff on your machine and have to delete it all and then that was really
39:07 illegal so they had to take it they had to separate them out and they just
39:11 keep finding ways to get back in yeah there's some really interesting stuff
39:16 you know they're now sort of putting ads in the start menu and stuff and
39:21 then the ads are forced to open in edge not your default browser it's just
39:24 like there's layers of like why are you doing it it makes me happy that I'm
39:28 not using Windows 11 at the moment whereas I've been looking forward to using
39:32 the new terminal and oh my posh shell on Windows which looks amazing so I think
39:37 there's a different groups this is definitely a different group than the
39:41 VS Code group of people this is going to take us back to 1995 and we're just
39:46 going to be using a terminal window to access anything so we don't get annoyed
39:50 by all this there's no ads in the Linux browser now if they could just get
39:57 the ad companies to be able to just collect your credit card information
40:02 and then instead of showing you the ad just buy it for you and set you up
40:06 on a payment plan we already know who you are just click here if you want
40:11 it or just send it to you anyway and just charge you later exactly so I feel
40:19 like this almost could be the joke but I've got a different joke for you
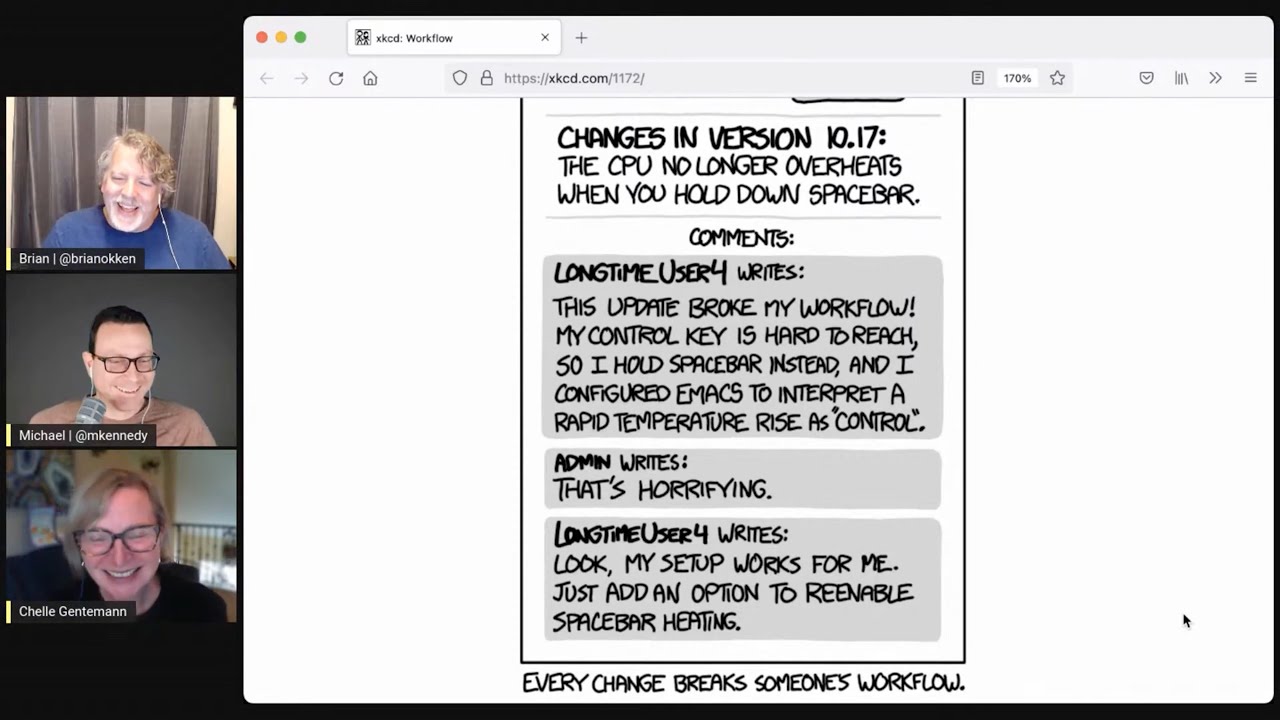
40:22 all right so the joke for this week comes from a solid source xkcd as you
40:27 may know this is about workflows and changing software so here's the one
40:32 that says workflow and it's just in the change log or some sort of conversation
40:36 flow maybe a github release or something it says changes in version 10.17
40:41 the CPU no longer overheats when you hold down the spacebar and then there's
40:46 a frustrated user comment it says long time user four writes this update
40:50 broke my workflow my control key is hard to reach so I hold the spacebar
40:54 instead and I've configured emacs to interpret a rapid temperature rise as
40:58 pressing control the admin writes that's horrifying the user writes look
41:04 my setup works for me just add an option to reenable spacebar heating oh I
41:10 remember like enabling all the weird emacs things that only you would know
41:14 about exactly and the subtitle is every change breaks someone's workflow
41:22 I love it yeah actually it's interesting because python's even like more so
41:28 like that because of the introspection and everything's really open unless you
41:33 really work hard to make it I mean you can't really hide too much stuff with
41:37 python so even if you have a comment around a function or an access point
41:44 to say this is not part of the API this is subject to change you can change
41:49 it and it will break somebody because somebody has reached inside and used
41:52 the thing you told them not to use yep yeah those double underscores and single
41:57 underscores they're just there to slow you down but they don't that's so you
42:00 notice what you're not supposed to do those are where the interesting parts
42:04 are exactly they wouldn't give me the feature but I can just do it right
42:07 here all right well I think that's it Brian yeah it was a good episode so thanks
42:12 everybody for showing up yeah thanks everyone yeah thanks y'all for being
42:16 here great to have you on the show thanks Michael thanks Brian take care
42:20 Bye, everyone.





