#270: Can errors really be beautiful?
Watch the live stream:
About the show
Sponsored by Datadog: pythonbytes.fm/datadog
Special guest: Dean Langsam
Brian #1: A Better Pygame Mainloop
- Glyph
- Doing some game programming is a great way to work on coding for early devs (and experienced devs).
- pygame is a popular package for writing games in Python
- But… the normal example of a main loop, which listens for events and dispatches actions based on events, has some problems:
- it’s got a
while 1:- that wastes power, too much busy waiting
- looks bad, due to “screen tearing” which is writing to a screen while your in the middle of drawing it
- it’s got a
- This post discusses the problems, and walks through to an async main loop that creates a better gaming experience.
Michael #2: awesome sqlalchemy
- A few notable ones
- SQLAlchemy-Continuum: Versioning and auditing extension for SQLAlchemy.
- SQLAlchemy-Utc: SQLAlchemy type to store aware
datetime.datetimevalues. - SQLAlchemy-Utils: Various utility functions, new data types and helpers for SQLAlchemy
- filedepot: DEPOT is a framework for easily storing and serving files in web applications.
- SQLAlchemy-ImageAttach: SQLAlchemy-ImageAttach is a SQLAlchemy extension for attaching images to entity objects.
- SQLAlchemy-Searchable: Full-text searchable models for SQLAlchemy.
- sqlalchemy_schemadisplay: This module generates images from SQLAlchemy models.
- Can we also get a shoutout to SQLModel?
Dean #3: ThreadPoolExecutor in Python: The Complete Guide
- Long, but worth it (80-120 minutes). Could be consumed in parts. It’s mostly a collection of other blogposts on superfastpython
- Many examples
- LifeCycle
- Usage patterns
- Map and was
- as_completed vs sequentially
- callbacks
- IO-Bound vs CPU-bound
- Common Questions
- Comparison
- vs. ProcessPoolExecutor
- vs. threading.Thread
- vs. AsyncIO
Brian #4: Chaining comparison operators
- Rodrigo Girão Serrão
- I use chained expressions all the time, mostly with ranges:
min <= x <= max, which is like(min <=x) and (x <= max)
- There are lots of chained expressions available, and some not so obvious.
a == b == c- all are equal, no prob
- what abut
a != b != c?- This actually can return
Trueifa == c
- This actually can return
- Lots of other issues with chaining discussed in the article, like non-constant expressions and side effects
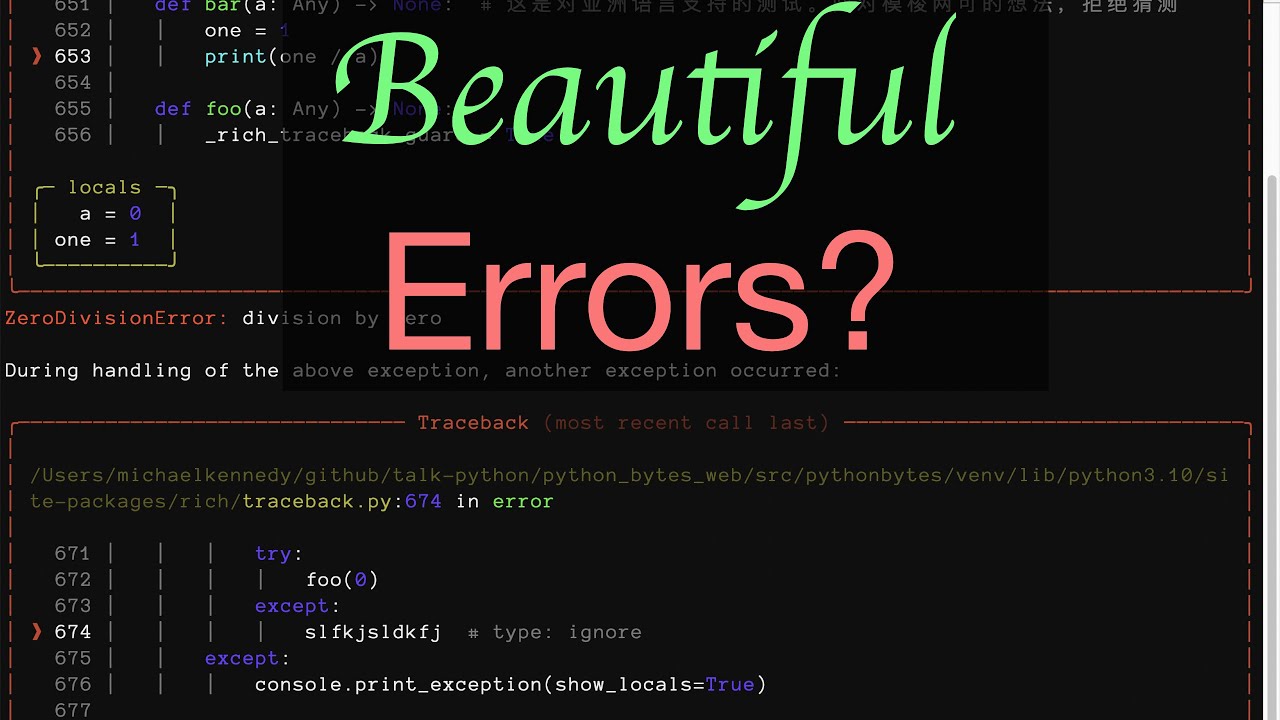
Michael #5: Create Beautiful Tracebacks with Python’s Exception Hooks
def exception_hook(exc_type, exc_value, tb):
...
sys.excepthook = exception_hook
Dean#6: Ways I Use Testing as a Data Scientist
- The importance of knowing what to test for
- using
assertin code on ad-hoc things. Do it while coding. - Us numpy
np.iscloseto test “almost equal” on entire arrays. also[assert_frame_equal](https://pandas.pydata.org/docs/reference/api/pandas.testing.assert_frame_equal.html) - Use hypothesis for bombarding the function with smart tests.
- Pandera and Great Expectations
- tests are documentation!
- Work with Arrange-Act-Assert
- Even if we’re not sure what to assert, writing a test that executes the code is still valuable.
Extras
Dean:
- Deprecate urllib out of stdlib?
- IPython 8 is out
- It’s less code!
- 37,500 LOC across 348 files → 36,100 across 294 files “I’m sorry I wrote you such a long letter. I didn’t have time to write you a short one.” – Blaise Pascal
- This was all done thanks to a developer hired through Small Development Grants
- coloring exceptions
- It’s less code!
Michael:
- Python Shorts New videos
/on pypi.org
Joke: Spelling
Episode Transcript
Collapse transcript
00:00 Hello and welcome to Python Bytes, where we deliver Python news and headlines directly to your earbuds.
00:04 This is episode 270, recorded February 9th, 2022.
00:09 I'm Michael Kennedy.
00:10 And I'm Brian Okken.
00:11 And I'm Dean Langsam.
00:13 Dean, so great to have you on the show.
00:15 Thank you.
00:16 So often you help me with that start in the live chat.
00:19 I know you're a big participant in the show, so we pulled you in and now here you are.
00:25 Welcome.
00:25 Thank you.
00:26 Thank you.
00:27 I've been a fan actually since episode one.
00:30 I've been hearing this weekly.
00:31 That goes back years, like five years or something.
00:34 Yeah, it's about five years.
00:35 I remember I moved apartments back then and I listened to Python.
00:39 I didn't know Python as well back then.
00:41 And I actually grow with the show.
00:43 So that's very nice.
00:44 That's fantastic.
00:45 That's incredible.
00:46 We've heard that from other people and that's just like mind-blowing to me.
00:50 But yeah, it's cool.
00:52 Yeah, I was taking like intro to data science classes in Coursera while listening to the show.
00:57 And now other people call me a senior Python.
01:00 So that was very nice.
01:02 That's fantastic.
01:04 And it does go fast.
01:05 Yeah.
01:06 So awesome.
01:07 Thank you so much for joining us on the show.
01:10 It's awesome.
01:10 Before we get into it, I also want to say this episode is brought to you by Datadog.
01:14 Check out their awesome stuff at pythonbytes.fm/datadog.
01:18 I'll tell you more about that later.
01:20 Right now, Python, I want to hear about a better Pygame loop.
01:25 Brian, tell us about it.
01:26 Yeah.
01:27 So this is an article from Glyph.
01:29 And Pygame is a package that's used for game programming a lot.
01:37 And it's, I mean, a lot.
01:39 And programming games is definitely, I think, it's one of the things I tried to do early on when I was a developer.
01:45 And I think it's something that I think I encourage a lot of new developers to try out things like simple games because it's fun to learn coding that way.
01:56 And it's, anyway, it's a big part of learning programming and the programming space.
02:01 And with Python, it's pretty easy with Pygame.
02:04 And there's a lot of tutorials out there.
02:07 But one of the things that Glyph points out is a lot of the tutorials have this sort of simple while one loop where you, the main loop of a game where you just spin and wait for events and then handle the event or draw things or whatever.
02:22 And then go back this and draw, you know, keep going.
02:26 And this just happens forever.
02:27 While one loop in programming is a busy loop and it's generally something that kind of has some issues.
02:34 So Glyph is pointing out that some of the issues with this are that they, that it's, it's waste power for one.
02:42 Your CPU is just spinning all the time when you're really not going to get events that fast.
02:46 And then also there's a, there's a thing that I didn't know about called screen tearing, which is when you're drawing the screen at the same time you're trying.
02:56 Writing to the screen buffer.
02:57 Right.
02:58 You're not waiting for the V sync 60, a hundred frames a second, whatever it is.
03:03 Right.
03:03 Yeah.
03:03 So, and that can cause glitches in the game and it doesn't, it doesn't look as good.
03:09 Py game does allow a V sync option, but apparently there's like some problem with that.
03:15 So what really there's a, the article walks through both of these, both of these problems and the V sync fix, but, and the problems with that.
03:25 But the end result really is he's got, it's actually interesting, interesting discussion about like really what's going on in py game.
03:34 And he talks about like that, that there's really three jobs going on in the drawing and a game logic and the input handling all at once.
03:42 And so this is a three thing.
03:44 It's probably a good idea to do maybe async stuff.
03:47 So things can work together.
03:49 And, and the solution he came up with is still, I mean, it's definitely a larger loop, but it's not that big of a loop more complicated.
04:01 And it's an async version to have some sleeps in there with some delays possibly, but a better loop for gaming.
04:10 And it's, it's not that complicated.
04:12 And actually if you're learning gaming while programming, hearing about this, these sorts of issues and, and trying to end learning how to solve it, it's probably just going to make you a better developer faster.
04:22 So I think it's a good thing to, to look at this.
04:25 Yeah.
04:26 This looks really interesting.
04:27 This game loop stuff, you know, it's, it's so often very much the same.
04:32 And there's like these core elements like process input, you know, if the key's down or if there's a joystick attached, draw the scene, do the hit detection.
04:41 And AI and game logic.
04:43 And it's, it's almost always the same.
04:45 Like this looks great as a way to tell me what I should be doing.
04:49 And maybe the next step would be create a class that I just override, do the AI logic, draw the screen and just let that like not even be something I ever see.
04:58 So this is ripe for a little bit of hiding away even this cool stuff.
05:03 That's true.
05:03 Maybe, maybe Pygame could extend a better built-in loop to hook into or something.
05:09 Yeah.
05:11 Yeah.
05:11 I always think about, I always, I'm not actually used, do a lot of gaming on Python, but I always think about browsers, which are also kind of a loop that runs forever and renders stuff on your screen.
05:23 And I think, well, the front end guys got it so easy, right?
05:26 They don't, they just write the code and the browser does it for them.
05:30 And I'm not sure if it works exactly the same.
05:34 But maybe if someone manages to implement something that's like, just write your game and put it in this thing.
05:41 Maybe this could attract more people into writing small games in Python.
05:48 Yeah, absolutely.
05:48 My thought is if you just sort of abstract that away, it's just 2D stuff, right?
05:55 Which it's pretty easy to get into.
05:56 I just listened to or watched a Netflix series called High Score, which is the history of video games going like way back to the Atari 2600 and Asteroid and whatnot.
06:08 And there's this woman in here talks about how she got so inspired about just text-based games.
06:12 So if you're learning to program, I definitely think games are a fun way.
06:16 And often I think people might perceive that as like, well, I've got to write, you know, Angry Birds or something, which is fine.
06:23 You can write that and that's super fun.
06:24 But you can do a lot of stuff with just sort of text-based little fun story adventure type stuff as well.
06:32 I got to check out that Netflix series.
06:34 That sounds great.
06:35 Yeah, yeah.
06:36 I was just helping a friend writing like this small game and he's written this like with one thread and everything for this school project.
06:44 And then he told me, well, but how do I show a score that like updates with the game?
06:50 And then I thought like, no, for that you'll need multiple threads, a Pygame loop maybe and stuff like that.
06:55 So if that could have been easier on him while learning Python, this could have been awesome.
07:01 Yeah, absolutely.
07:03 There's a lot of nice comments out in the live stream.
07:06 Anthony says, I teach Pygame in my code club after school class.
07:11 Smart kids, Pygame is great.
07:12 So is Arcade, which is an alternative, an OpenGL-based alternative to Pygame.
07:17 That's very cool.
07:18 I do think having something visual for people when they're learning, it just, it reinforces things so much, right?
07:25 Like writing that API back in that talks to database is great when you see the next three steps down the line, how it's going to enable something.
07:32 But when you're getting started, you need quick feedback.
07:35 Absolutely.
07:36 All right.
07:37 Well, let's talk about something else that's awesome here.
07:40 I want to talk about SQLAlchemy.
07:42 SQLAlchemy has been getting a lot of attention lately, and that's super cool.
07:46 Mike Bayer released SQLAlchemy 2, which was the first async API version.
07:53 So now you can use async and await with SQLAlchemy, which opens up lots of possibilities.
07:57 Sebastian Ramirez released SQL Model, which is like a marriage of Pydantic and SQLAlchemy, which is also super neat.
08:05 But there are many other things that you can do with SQLAlchemy that are really handy.
08:09 So as all the awesome lists go, here's one for a curated list of SQLAlchemy.
08:16 Now, first, just a word of warning from what I can tell, including the PR that I added yesterday, all the way back to the one in June 2020.
08:26 It doesn't seem to be getting a whole lot of love, which is unfortunate.
08:30 So it seems like it might be sort of stalled out.
08:33 But that said, it's still a really good list of things.
08:36 So I'll pull out a couple that I think are nice here.
08:39 Which ones did I want to highlight?
08:40 The first one is called Continuum.
08:42 SQLAlchemy Continuum.
08:44 And this is versioning.
08:46 So imagine you would like to have a history or a record of changes to your database.
08:52 Like maybe this is some sort of financial thing.
08:54 And if you see changes, you want to be able to say, this person made this change on this date when they said, you know, update.
09:02 Get the record.
09:04 Make a change.
09:04 And, you know, call commit on the SQLAlchemy session.
09:07 So what this does is it will create versions of inserts, updates, and deletes.
09:12 It won't store those.
09:14 If there's not actually a change, it supports Olympic migrations.
09:18 You can revert data objects and so on.
09:21 So if you want that, SQLAlchemy Continuum.
09:23 It's just like one of the many, many, many things in here, which is pretty awesome.
09:28 Another one I wanted to highlight is UTC.
09:31 So one of the challenges that people often run into is when you're storing stuff in the database, dates in particular, what time is that?
09:38 Is that the time of the user who might be in a different time zone than the API endpoint that it was running at?
09:45 Right.
09:45 So it might be nice to be able to store time zone aware things and store them as UTC values so they're always the same.
09:55 And then you can convert them back to the time zone, which is pretty cool.
09:58 Another one is the SQLAlchemy Utils is pretty cool.
10:01 So it's got things like choice type, which I'm guessing is basically enum.
10:06 But country, JSON, URL, UUID, all of these different data types, data ranges, all kinds of stuff.
10:15 ARM helpers, utility classes, and different things like that.
10:18 So that's kind of a grab bag of them.
10:21 Let's see.
10:22 One also is called File Depot.
10:24 There's cool stuff for processing images.
10:27 You've got File Depot, which is a framework for easily storing and serving files out of your database on the web,
10:33 as well as SQLAlchemy Image Attach, which is specifically about storing images in your database,
10:38 which, by the way, we do, Brian, on Python Bytes.
10:41 Cool.
10:42 If you go to any page, any episode page, and you see that watch it on YouTube, that little thumbnail,
10:48 we go get that dynamically from YouTube and then serve it up so we don't have to depend on YouTube.
10:52 Anyway, that's pretty cool.
10:55 Let's see.
10:56 Maybe two more.
10:58 There's Searchable.
11:01 So if you want to add full-text search to your model, you can add, use this.
11:06 And then it only supports Postgres because I'm sure it depends upon some core element there.
11:11 But you can also do another one from MySQL as well, which is pretty cool.
11:15 And then the last one is Schema Display, which generates basically graphs of your models and how they relate to each other, stuff like that, which is kind of neat.
11:25 Nice.
11:26 What do you all think?
11:27 Cool stuff, right?
11:28 Yeah.
11:28 Very cool.
11:29 Yeah.
11:30 So if you're really bought into SQLAlchemy, you owe it to yourself to just flip through this list to just go like, wait, it can do that?
11:39 I had no idea that it could do that, right?
11:41 And just sort of see what are the other things that people built on top of here that I think would be super, super helpful.
11:47 And by the way, my PR was really to say there's a layer called thin abstractions.
11:55 And it says, you know, under the thin abstractions, we really should have us some SQL model because that thing is super popular straight out of the gate, right?
12:04 So people should check this out.
12:05 It's already got almost 7,000 stars and it's, what, a month old or something?
12:10 That's crazy.
12:10 Yeah.
12:11 Maybe six weeks, but really, really new.
12:14 Yeah.
12:15 And.
12:16 But the author, I mean.
12:18 Yeah, exactly.
12:20 I know.
12:21 Brandon on the audience says, there should be a meta awesome list, like an awesome list of awesome lists.
12:27 I'm sure there is.
12:28 There is.
12:32 I'm sure.
12:32 And yeah, quite fun.
12:35 I definitely recommend people check that out.
12:37 All right.
12:38 Dean, that brings us to your first item.
12:40 Tell us about it.
12:40 Yeah.
12:41 So at work, I needed to write something that required threading.
12:45 And I was very afraid of threading at the beginning.
12:48 Basically, what we needed to do, we have some mechanism.
12:51 I'm a data scientist and we need to take many queries at once and get them as Pandas data frames and save them to disk and later take all of them and work with them.
13:02 And instead of writing, like sending them sequentially, I wanted to send a bunch of them together.
13:08 And the bonus thing I found that is that when you release them to a threading, if you don't lock the threads or you don't wait for the threads, you can actually still work with the Jupyter notebook while waiting for the queries.
13:20 So that was my main reasoning.
13:21 And eventually, after I've written most of the code, I got this blog post called The Threadpool Executor in Python, The Complete Guide.
13:30 So this is basically Jason Brownlee.
13:32 He's a guy who's also the guy from Machine Learning Mastery, so I'm very familiar with him.
13:39 It's a very long blog post, so you could kind of read it as an e-book or just access the stuff you need because it's like, I don't know, a two-hour read maybe.
13:49 And he explains everything from the beginning.
13:53 He explains what are Python threads, how to work with them.
13:57 Then he introduces the Threadpool Executor, which is a more convenient way to use threads.
14:02 He explains about the lifecycle of what does he do, how to do it then with a context manager and stuff like that.
14:10 And eventually, what he talks about that other people do not when you search for a threading tutorial is actually about the complete lifecycle and then the usage patterns.
14:22 And then he explains about IO bound versus CPU bound and everything.
14:26 And he finishes off with the common questions.
14:29 So this is like the link I've saved because I will forget it in a week.
14:33 But the next time I need to, I just know I can come back to this and like read the common questions part.
14:39 And yes, there are questions.
14:41 The questions like, how do you stop running?
14:44 There's a lot there, yeah.
14:44 There is a lot there in this article, isn't there?
14:47 Yeah, it's a lot.
14:48 It's a lot.
14:49 But the thing is, you can come back later and just take the stuff you need.
14:52 Like I remember, I know I'm working, then I can ask myself, how do you set a chunk size in map?
14:57 Well, it says there that you don't because that's for the process pool.
15:00 But then I have another question.
15:02 Maybe how do you cancel a running test?
15:03 And the answer is that.
15:04 So I think that's a good thing to have like to quickly access when you need to.
15:11 And it finishes off with like, what's the difference from asyncIO, from threading.thread, from process pool executor.
15:19 So that is a very helpful guide, very complete.
15:23 And the entire blog actually explains, like it's an entire blog dedicated to the threading pool executor and the process pool executor.
15:33 I love that it's covering the thread pool and process pools because it's easy for things to just completely get out of control.
15:43 You know, as you throw more work at it, stuff can completely back up.
15:47 So if you just say, create me a new thread and run that.
15:49 And then another place, create me more threads.
15:51 And I got a bunch more.
15:52 Oh, look, now I have a thousand items to process.
15:54 Create a thousand threads.
15:55 Yeah.
15:55 Each thread takes a lot of context switching to switch between.
15:59 And they take a decent amount of memory and all sorts of stuff, right?
16:02 Through the thread pool, you can say, queue up the work and run 10 at a time.
16:05 Same for processes, which sort of sets an upper bound on how much concurrency you can deal with, right?
16:12 Yeah.
16:12 Yeah.
16:14 This is cool.
16:15 So you talked about solving some problems in Jupyter Notebook using this.
16:19 What in particular were you trying to do?
16:20 So basically, I can send, I know, a thousand queries.
16:25 And once they get, like, we have big data and then they have a query that takes a part of it.
16:31 Like, after maybe some group buys and limitations and stuff like that.
16:35 And I want to take the data frame and save it.
16:38 Right.
16:39 And then once I have the entire data from all the queries, I want to join them or maybe do some, I don't know, some processing and then join everything.
16:48 The thing is, after, like, 10 of those came back, I have a sample of my data that I can work with and try to manage and then have a code written.
16:59 And while the other stuff is still written, I want to have that, like, I can play with it.
17:04 So if I release the other things to the threads and they work in the background, the main thread of the Jupyter Notebook is open.
17:13 And you can start working on the same notebook.
17:16 Before then, I used to, like, open a notebook that's querying stuff, open a notebook that I'm playing with and, like, see that the file paths are the same.
17:27 So I'm not confused with, like, some other directory of the other versioning of this data.
17:32 And now it just works.
17:34 Oh, that's really cool.
17:35 And you can also, like, add a thread for, I know, with some visualizations of what's finished, what's eroded, what's, like, everything.
17:43 Fantastic.
17:44 Yeah, that sounds really good.
17:45 I'm sure there's a lot of concurrency and parallelism in the data backend.
17:49 It's just how do you sort of access that from Python, right?
17:52 So how do you issue all those commands?
17:53 Excellent.
17:54 All right.
17:55 Let's see.
17:56 Brian, anything you want to add before I talk about Datadog?
17:59 No.
18:01 Some comments, like, Sam, Morley, concurrent futures is a much less painful way to work with them at a higher level.
18:09 So maybe we could get an article on concurrent futures on the upside sometimes.
18:14 Yeah, for sure.
18:15 So the thread pool executor gets you back futures.
18:20 And then part of what's explained in the blog post is how to work with futures, like, as completed or sequentially or, like, you decide your strategy,
18:30 but you work with the futures.
18:32 Nice.
18:33 Okay.
18:33 Cool.
18:34 Yeah.
18:35 Nice.
18:35 And, of course, requisite shout out to Unsync, which is all sorts of awesome for this stuff.
18:41 Unifies the API for direct threads for processes and AsyncIO.
18:49 But what I want to tell you all about now is Datadog.
18:52 Datadog is really awesome.
18:54 You should really have insight into your applications.
18:56 And that's what Datadog brings you.
18:58 So Datadog is a real-time monitoring that unifies metrics, traces, logs into one tightly integrated platform.
19:06 Their APM empowers developers to identify anomalies and resolve issues, especially around performance.
19:13 You can begin collecting stack traces, visualize them as flame graphs, and organizing them into profile types, such as CPU bound, IO bound, and so on.
19:22 And teams can even search specific profiles and correlate them to distributed traces to, you know, find things across different parts of your infrastructure and microservices and identify slow or underperforming code and then make it faster.
19:35 Plus, you can use their APM live search.
19:37 You can search across the full stream of all the traces over the last 15 minutes.
19:42 So try Datadog APM for free with a 14-day trial.
19:46 And then Datadog will send you one of these very cute doggy t-shirts, which who wouldn't want one of those, right?
19:52 So visit high-dom-by-stud.fm slash Datadog or just click the link in your podcast player show notes to get started.
19:58 Thanks, Datadog.
19:59 And, Brian, back to you.
20:01 Back to me.
20:02 I was, I'm going to apologize whoever tweeted this, but somebody tweeted this out, a link to this article, and talking about chaining operators.
20:15 So this is an article by Rodrigo Serrao.
20:19 Py don'ts?
20:21 Yeah.
20:23 So I don't know what the py don'ts are about.
20:28 Just, I don't know.
20:29 Maybe he started blogging about things you shouldn't do in Python.
20:32 Anyway, this article is called Chaining Comparison Operators, and I use chaining all the time.
20:38 Mostly, I use it for simple things like, oh, let me find one.
20:43 A is less than B, less than C.
20:45 So ranges, like min, you know, my X value is between min and max.
20:50 Yeah, that's really nice.
20:51 Yeah.
20:51 My hint on that, like, just tip for anybody doing that, always do them less than.
20:58 Don't do greater than, because it's hard to do that.
21:01 Anyway, so keep them like that.
21:04 But this article is talking about other stuff.
21:06 So this is pretty easy to think about, like the less than operators.
21:10 So A is less than B, less than C.
21:12 Is that really the same as A is less than B and B is less than C.
21:18 It is that combination.
21:19 That's what chained operators are.
21:21 And the importance there is it doesn't really work for some operations.
21:28 And it gets into, like, the equal operator.
21:31 So you can do A equals B or equals C, which means they're all equal.
21:36 Great.
21:36 What about not equal?
21:38 Does that work the same way?
21:40 And it doesn't, because if you've got, like, A is not equal to B is not equal to C, it doesn't mean they're all different, because A and C still could be the same and have that pass.
21:53 So this article, if you're working with chained expressions, which I think you should, if you're doing complicated things, it's way, I like it better than doing, having a bunch of ands in there, as long as that you can keep it readable.
22:07 But this article talks through some of the, some of the gotchas inside of, and things to watch out for, like side effects and non-constants and things like that.
22:17 So great discussion of chained operators.
22:21 I hadn't even thought of doing this not equal to.
22:23 This seems wrong.
22:23 It just looks wrong.
22:25 Yeah.
22:27 But, yeah, don't do chained not equal.
22:31 That's just, unless, and even if that's what you meant, that, like, A is not equal to B and B is not equal to C, but it's okay for A and C to be equal.
22:39 That would be a terrible expression, because it's confusing.
22:41 So don't do that.
22:42 It is.
22:43 Yeah.
22:43 My favorite one of these chainings, like, X, you know, 7 less than X less than 10.
22:50 Yeah.
22:51 Something like that.
22:51 That's nice.
22:51 My favorite is converting X, if X is not none, else Y to just X or Y.
22:58 Boom.
22:59 That's so clean and so nice.
23:01 And I never, coming from a C++ background and C#, I never thought that was possible.
23:07 That's great.
23:07 Yeah.
23:09 Dean, what do you think about this?
23:10 I love it.
23:11 I use it a lot.
23:13 It didn't always work.
23:15 I think it's still not working with Pandas data frames or Pandas series and arrays.
23:20 And I do wait for this to finally work.
23:24 Arrays, when you do an array, like in NumPy or Pandas, when you do an array, it's less than some number.
23:31 It returns a new array with true, like a Boolean array with true and false.
23:35 And last time I checked was a few months ago, but the last time I checked, it didn't work.
23:40 I couldn't do one is less than the series is less than two and get the Boolean array.
23:46 So I'm waiting for this, but I love the concept a lot.
23:50 Okay.
23:51 That's good.
23:52 Yeah.
23:52 I had to consider the integration into Pandas.
23:55 Yeah.
23:55 But of course.
23:56 I'm not sure how would you implement that with the regular data model of like Dunder, Dunder EQ or is this something else?
24:03 I'm not sure.
24:04 LTE.
24:04 LTE.
24:05 Yeah.
24:05 Possibly.
24:06 I'm not sure either.
24:06 Yeah.
24:08 There's probably some magic method and it might just expand out to less than and then and, you know, like the two tests basically.
24:15 Probably does.
24:15 Oh, cool.
24:16 We should ask Brett Cannon to do a deep dive into what he changed off.
24:23 He's pulling apart all the different parts of Python syntax, right?
24:26 Yeah.
24:26 All right.
24:27 I want to give a quick shout out to Rich because it's one of our episodes.
24:32 So we talk about Rich.
24:34 I was going to talk about Anthony Shaw, but I didn't have enough information.
24:37 So, I mean, he's the other person who needs a shout out in every show.
24:41 So I want to talk about this article highlighting some tools by Martin Hines.
24:48 Yeah.
24:48 Martin Hines.
24:49 Yeah.
24:49 Well, creating beautiful tracebacks with Python, done exception hooks.
24:53 So two things that I want to point out here.
24:55 One, Python has an exception hook mechanism, which is pretty cool.
24:59 So what you can do is you can create a function that has this signature of exception type, the actual exception and the traceback.
25:08 So three arguments.
25:09 And if you have a function like that, you can just go to the sys and say sys.accept hook equals that function, not calling it, of course, just passing the function as the value.
25:19 And then whenever there's an exception, this will be called by Python.
25:22 That's pretty cool, right?
25:23 Yeah.
25:24 So depending on what you want to do, like you could say, well, we're going to store all the errors.
25:28 Like, let's imagine here's a scenario where you might make use of this.
25:33 I'm going to create an app and I'm going to send it out.
25:35 I'm going to use Py2App or Py2XE or just, you know, let people install it somehow.
25:40 And then when it runs, I want to, it's going to run on their computers, but I want to gather up all the exceptions of all the users across the company or the research team or whatever.
25:49 You could have this, submit this error along with other details right back to a database over an API, right?
25:55 And then you could do like analytics, like, well, here's the most common error and so on.
25:59 Of course, you could use Sentry or something like that, but maybe you're trying to gather some specific information that's different, right?
26:05 So that's one of the types of things you could do with this.
26:07 So I got a question before I go on.
26:09 Yeah.
26:10 So this doesn't catch the exception.
26:13 It just, it doesn't interrupt the flow.
26:16 It just, it just gets called when it happens.
26:18 It doesn't, it doesn't catch the exception.
26:22 It lets you basically change what kind of output comes from Python.
26:27 So if you just wanted to print out like, here's a file where there was an error and here's the error message.
26:32 Okay.
26:33 Like you could do that, right?
26:34 Or the type and then the message.
26:36 I'm just noting the, noticing the example doesn't re-throw it.
26:39 So you don't have to do that then.
26:41 No, I don't believe so.
26:42 And I'm not a hundred percent sure.
26:44 I think the app, I think the process still ends.
26:47 If it's just a regular running script rather than a web app.
26:51 I think it still ends.
26:53 But anyway, sorry.
26:54 You get a different kind of output.
26:55 Yeah, yeah.
26:56 No, you just don't get the standard print output that Python gives you, right?
26:59 So you could say, avoid printing the trace back if you wanted.
27:02 You could just say this file on this line had this error.
27:04 Oh, yeah.
27:05 Okay.
27:05 Nice.
27:06 Okay.
27:06 So it's easy enough to do.
27:09 Like, for example, they have this function that they call that caused an error.
27:13 And all you see when this crashes is there's a trace back.
27:17 This file, this line in this module, here's the error message, right?
27:22 Instead of the huge stack trace that might scare people.
27:25 Okay.
27:25 So, I mean, obviously you can use try and accept, but this is global, right?
27:29 So even if some library is calling something and you're not catching it and like, right,
27:33 it's catching everywhere.
27:35 Okay.
27:35 So then you could do more work about breaking that apart.
27:38 And they talk about doing that.
27:39 But the real interesting part is if you go and look at some options.
27:44 So there are five, I believe there are five libraries mentioned in here that do really cool
27:48 stuff for solving this.
27:49 The first one is by Will McGugan's rich library.
27:53 So you can just go from rich.traceback, import install, and then say install.
27:58 Show locals is true.
28:00 And then this also basically installs one of those global exception hooks.
28:05 With the benefit being when you get the errors, what you get is a nice rich output.
28:11 It's super pretty.
28:12 It's pretty and it's useful.
28:14 I mean, it's color highlighted so you can see where the error happened, but it also will
28:18 print out in a really nice way with formatting and highlighting the locals, right?
28:23 So what values were passed to that function when it's crashed?
28:26 Well, here's a little table of those and so on.
28:29 So this is really easy to identify.
28:32 And at the very bottom, like a nice clear way to like, okay, what happened?
28:35 So you can do this super simple version here.
28:38 And there's also some manual ways to make rich print this type of stuff.
28:42 Number two is better exceptions, which does similar stuff.
28:46 You can see that it doesn't quite take over how the look and feel is so much, but it basically
28:51 colorizes the standard look and feel of errors.
28:55 So you can see, you know, which function, which error and so on.
28:59 So that's pretty good.
28:59 And there's pretty errors.
29:01 Check out pretty errors.
29:02 This looks pretty good, right?
29:05 It's got a lot of like bold and highlights.
29:07 You can really call out the error messages and the functions involved in the modules involved.
29:11 Here's one for you, Dean.
29:13 The built-in one to IPython.
29:14 It has ultra TV for ultra traceback.
29:19 And this is pretty nice, right?
29:21 Actually, the IPython one's pretty good.
29:23 Yeah, the Python one is really nice.
29:26 And also I was planning to talk about it in the extras, but on IPython 8, which is pretty
29:31 new, they even have this improved with some color coloring of exactly where the error happened.
29:38 I think this uses the 310 part or something like that.
29:42 Oh, awesome.
29:42 Yeah, that's cool.
29:43 We'll hear more about it when we talk about IPython 8 as well.
29:47 Cool.
29:47 Yeah, so that's built in, kind of if you're already on the data science stack.
29:51 And then finally, stack printer, which you can give it a traceback and it will print that
29:57 out.
29:57 So you can sort of do like rich, you can say set exception hook and give it a theme
30:01 like dark or whatever.
30:02 And then it does this pretty nice printout as well.
30:05 So these are all great.
30:06 I'm personally liking the rich tracebacks version best, but this is really nice.
30:13 Yeah.
30:13 Connor out there in the audience says, wow, using show local SQL tree would have saved me hours
30:18 and hours of time.
30:19 And you and me both.
30:20 Yeah.
30:20 I feel the pain.
30:21 I do too.
30:23 So because a lot of times you're like, I know it crashed and it says none type does
30:27 not have attribute, whatever.
30:29 But like, why is it none?
30:30 I need to go back three levels, right?
30:32 Like, yes, it's so good.
30:34 And then you find out you just forgot to return from the function.
30:38 Yes, exactly.
30:41 I was just debugging a test failure the other day and pytest has the option to throw a local.
30:48 You can show locals with a crash or with every failure.
30:54 And I forgot that the particular thing I was testing had like variables that were storing
31:03 thousand element arrays.
31:06 It just like went on for me.
31:08 I believe the, I believe Rich's has a truncate variables where it'll do an ellipsis or something
31:16 like that.
31:17 I think.
31:18 I mean, yeah, I'm not a hundred percent sure because I've been looking at all five of these
31:21 Will's in the chat.
31:22 We'll have to ask him.
31:22 Will's in the chat.
31:23 You'll have to give us a shout out.
31:24 Will, I think, I think truncate is out there, right?
31:27 I'm not a hundred percent sure.
31:28 I think of how can I actually, so I talk with databases and sometimes the errors from the
31:34 databases are like this big Java stack, Java trace.
31:38 And then you need to like a lot of go a lot of apps.
31:43 Sorry, something, some noise here.
31:45 Sorry.
31:46 You need to go a lot, a lot up in the browser to actually see the error.
31:51 And if I could just shut it down and just give me the Python stuff.
31:55 Cool.
31:57 Yeah.
31:57 I don't know what setting you set for that, but certainly with this mechanism, you could
32:02 set it up so that like if the word Java appears, you just stop.
32:06 Yeah.
32:06 You just stop going back.
32:08 Yeah.
32:08 And Will says, yes, that's right.
32:10 Thank you, Brian, for pulling that up.
32:12 Yeah.
32:12 Yeah.
32:12 You can truncate it so that printing won't go completely insane because it could be gigabytes.
32:17 I mean, it could be out of control, right?
32:18 Yeah.
32:19 Yeah.
32:19 But I mean, even if they have a like reasonably large limit, sometimes it's just like, oh,
32:24 I forgot that huge array was there and it's hard to see stuff.
32:28 So.
32:28 Yeah, absolutely.
32:29 Yeah.
32:30 All right.
32:31 Over to you, Dean.
32:32 Speaking of testing, Brian was talking about testing stuff and looking at the color and so
32:37 on.
32:37 Yeah.
32:37 So I thought, Brian, this would be up your alley.
32:39 So it's called Ways I Use Testing as a Data Scientist.
32:44 It's by Peter Baumgartner.
32:46 And I'm a data scientist, but I also love testing.
32:50 The thing about testing with data science is sometimes it's not that clear what you should
32:56 test for.
32:57 Right.
32:58 because sometimes some things we do are stochastic and then you could not actually test for stuff or stuff like that.
33:06 So this blog talks about like the art of testing because sometimes like the it's not clear what you should test.
33:14 And the more experience you get, you can actually see what's coming your way.
33:18 And he talks about like data validation and he is throwing many packages that could help you.
33:27 Packages like Pandera and Great Expectations that I think we've talked about before in the podcast.
33:34 And also like the NumPy has some stuff like is closed.
33:40 Checks for two numbers close to each other or array equal assert data frame equals in Pandas data frame.
33:47 So he talks a lot about that.
33:48 He also talks about using assert in your code.
33:52 Like even if you had some ad hoc stuff of analysis, use assert within the code.
33:58 Don't think about the tests later.
33:59 Just think like where does this thing could hurt me?
34:03 He gives an example.
34:05 Maybe if I'm trying to join two data frames and I think they have the same shape, I want to check if they have the same IDs.
34:12 So that way I know that the join works correctly.
34:16 So he asserts that the length of the IDs is the same within the two data frames.
34:21 And this is not even like real testing, we would say.
34:25 It doesn't use some testing framework.
34:27 It just says like write it within your code.
34:30 It then continues to like hypothesis, which basically bombards the functions with a lot of ways to actually try to fail it.
34:40 It continues with some other packages and eventually goes into a pytest and shows like how it would work with pytest and with like an approach that I haven't heard of.
34:52 But it sounds good.
34:54 Arrange, act, assert.
34:58 Like arrange the data, then act on those things you want to check and then just assert if they are equal or almost equal and the thing you wanted to check for.
35:08 Yeah, it's such a such a easy mistake to make.
35:13 Like this number equal equal that number.
35:15 Yep.
35:15 And it's what when you do in science or data science.
35:19 I'm glad he talks about structure because a lot of people that get into testing get get these giant tests that do do a little work, test something, do a little more work, test something.
35:29 And then if it breaks, you're not sure what where the failure is.
35:33 So this looks sounds fascinating.
35:36 And actually, I'm not sure how I missed it, but I really want a way to compare an array for almost equal.
35:42 So I'm going to have to go read that.
35:45 Yeah, so NumPy and Pandas both have mechanisms for that.
35:49 It's pretty great.
35:50 Nice.
35:50 Cool.
35:51 Yeah.
35:52 Very nice.
35:53 I know this will be helpful to people.
35:55 It's really I always wonder about testing data science stuff and machine learning things and so on where you get small perturbations, but they're fine.
36:04 It's off by one millionth of some unit, but that's totally good.
36:10 Those are equal.
36:10 But it takes, I think, an extra level of thinking about it.
36:14 So much people focus on, well, how do you get rid of your dependencies and how do you make sure that you don't talk to the real database when you do this?
36:20 And that's one aspect that people focus on.
36:23 But this working with science-y type stuff is its own specialty.
36:27 Yeah, I think the entire community is a fairly new community, although it's not as new as it was.
36:34 And I'm not sure we're on top of how to do tests in machine learning.
36:40 We have many packages for that.
36:43 We have many theories for that.
36:45 But I'm not sure we have actually one solid good way.
36:51 And maybe we shouldn't have.
36:52 But it's a debate.
36:54 Yeah, for sure.
36:56 Same with the rest of the software world.
36:58 So welcome.
36:59 Thanks.
37:02 Yeah.
37:02 And Sam out in the live stream says, NumPy has an assert array almost equal in NumPy.testing.
37:07 Nice.
37:08 I just learned there's a NumPy.testing.
37:10 That's cool.
37:11 Yeah.
37:11 Awesome.
37:13 All right.
37:14 Dean, while you have your screen up, do you have any extras you want to talk about?
37:17 I know IPython 8 was a thing.
37:19 Yeah.
37:20 So IPython 8 was released last month after three years of waiting for a major version.
37:28 It has a lot of new features, but this is the extra part.
37:31 So I won't go over them.
37:32 Just two and a half things I wanted to mention.
37:35 It says that it's less code.
37:37 And I love that.
37:38 Like once you get better in a programming language, you understand it.
37:42 You shouldn't write more code.
37:43 You should delete code.
37:45 And that's what those guys do.
37:47 And the way they could have done that is by hiring a person through the NumFocus small development grants.
37:56 And I think this is important.
37:57 It's actually been talked a lot about after the Log4j stuff.
38:02 It's been talked about like, well, those are three guys who worked tirelessly.
38:06 They have their full-time jobs and they couldn't fix the Log4j stuff maybe as quickly as some other people wanted.
38:13 But then you realize that they got donations of like a few hundred dollars within 10 years.
38:18 And then after the Log4j, suddenly they got a thousand.
38:22 So this, I think it shows you how the money could help open source stuff.
38:28 And maybe if you use some package in a company, in some corporate, maybe try and think how you can give back money.
38:36 Or even if you give back code, if you free up your developers to actually contribute, this is awesome.
38:43 And the half thing just mentioned because it talks about the traceback.
38:49 It shows that you can now see it's like colored.
38:53 You can see on the screen, it's called the part where actually the arrow was, it's colored now.
39:00 So it's very nice to see.
39:02 Like the example shows you, you add the function three times, but only it fails on just one input of them.
39:10 So it shows you which of the three times the function failed.
39:13 Right.
39:14 You call it the same thing like foo of zero plus foo of one plus foo of two.
39:19 And it's the middle one that failed, not just line seven, but the second invocation with the value one where it failed, which that's awesome.
39:26 Yeah, exactly.
39:27 And the same.
39:28 Well, that's right.
39:29 I was going to say the same thing for indexing into, what is that, a data frame or something like that.
39:34 Like it's, you're chaining together like bracket zero, bracket one, bracket zero.
39:38 It's the second one trying to get to the one of zero.
39:42 That was the one that failed there.
39:43 That's really, those are hard to come back and find if you're not in a debugger.
39:48 Like, well, which one of these failed?
39:49 Like, great.
39:50 Array index out of bounds on line three.
39:53 Well, there's three of those happening.
39:54 Which one?
39:55 Yeah.
39:56 Yeah, that's cool.
39:57 And another thing is a tweet by Victor Steiner is a core dev.
40:02 And he says, I mean, it's now time to deprecate the standard lib, URL lib module.
40:08 And this is brought a lot of haters and fans.
40:13 And I'm not sure what's my opinion yet.
40:15 I'm not a heavy user of URL lib.
40:19 But it opened up a debate.
40:20 Like, we know how to do.
40:23 Yeah.
40:24 Yeah.
40:24 That's really interesting.
40:25 There are certain things in the standard library.
40:28 You're like, yeah, yeah.
40:29 I know that's there and you could use it, but you probably shouldn't use it.
40:31 There's like so many better external choices that are so good that it would be kind of silly
40:36 to bite them.
40:37 Right.
40:37 That's sort of the recommendation here.
40:39 Yeah, but also some people don't like it.
40:41 They have people there that say they hate dependencies.
40:45 And sometimes you can do most of the work with the standard lib.
40:50 And some of the tweets said, like, maybe deprecate the major parts that requests can do.
40:57 But there are some other parts that are actually really needed.
41:01 So maybe deprecate half of it.
41:03 Yeah.
41:04 I'm not sure if I'm about deprecating it.
41:08 But, you know, it's one thing to say there are better choices.
41:11 And we as a community recommend you probably just don't use this.
41:14 But to deprecate it means to people who would rather go with a dependence, a lower level of
41:20 dependencies, you're giving them warnings that they shouldn't be doing this when maybe, you
41:24 know, it's unlikely it's going to actually vanish.
41:26 Right.
41:26 There's like a fallacy, though, that I think some people have that if it's in this, if they
41:32 don't have dependency and it's in the standard, they're using something in the standard library,
41:36 it's more solid.
41:38 But I don't know if there's that many people working on URL lib right now.
41:43 And some of the other parts that maybe people want to stop supporting.
41:49 That's something very valid.
41:51 Python still is an open source project.
41:53 And we can make those decisions.
41:55 Yeah.
41:56 Victor actually says there are 40-year-old security issues in URL lib.
42:01 So maybe it's better to use something outside of it.
42:04 Yeah.
42:05 Yeah.
42:06 People want it to stay.
42:07 But there's these issues.
42:09 Yeah.
42:10 I wonder if there's a way to go.
42:11 Well, let's look at some of the libraries that are out there.
42:13 Try to bring them in and just use their core to replicate that functionality.
42:19 Not to say, let's just pick on requests.
42:21 Bring requests in.
42:23 Vendor a little bit of it in so it does what URL lib does.
42:26 And just go look.
42:28 Okay, this is the latest, greatest that we got.
42:30 And everyone's been looking at requests already.
42:32 I don't know.
42:32 It could be interesting.
42:33 Yeah.
42:35 And then Brandon out in the audience points out there are also maybe environments where
42:39 you can't install dependencies for security reasons.
42:41 And so having things like URL lib allows you to do more with Python in those situations.
42:46 But if there's security problems with URL lib, yeah, anyway.
42:50 Yeah, just in some of the functions, you don't call those.
42:53 No, I'm just kidding.
42:53 All right, Brian, how about you?
42:55 Extras?
42:56 Just one extra.
42:57 I brought this up last week.
43:00 I'm currently not writing a book.
43:01 Yay!
43:03 So I want to write more blog posts.
43:06 So one of the things I wanted to make sure that my blog migrated to pythontest.com.
43:12 And now it has a blog setting.
43:16 And I like it.
43:18 It looks pretty, too.
43:19 Instead of just pulling everything over from my old WordPress blog, I'm trying to edit it.
43:25 So I'm up through 2012.
43:29 I'm going to go oldest to newest and gradually do things, bring things in.
43:34 So that's one of my side projects I'm working on.
43:38 Yeah, that's a great side project.
43:39 Nice.
43:40 What's that running on?
43:41 Is that like some static site generator or other hosted thing?
43:45 It's Hugo hosted by a free Netlify account.
43:48 Yeah.
43:49 Netlify is pretty awesome.
43:50 All right.
43:51 I got a couple of things I want to give a quick shout out to.
43:54 Yeah, Brandon.
43:55 Brandon had the same question, but we got it.
43:58 All right.
43:58 First of all, I have two new my Python shorts, two new versions, two videos from there.
44:03 I got beyond the list comprehension.
44:04 So basically set and dictionary comprehensions.
44:06 Fun stuff.
44:07 Nice picture.
44:08 Thank you.
44:09 It's a little and it's like just a screenshot out of an animation.
44:13 And then combining dictionaries.
44:15 Python 310 way is the title of the article.
44:17 It really should be 3.9, but I kind of want to communicate like if you're on the latest Python,
44:21 how should you be doing it?
44:22 It came out in 3.9, the features that are actually in there.
44:25 Anyway, the pipe stuff.
44:27 Dictionary 1, pipe, dictionary 2, pipe, dictionary 3, which is all fun.
44:32 And then I wanted to talk about a feature over on pypi.org.
44:35 I don't even know how I found this.
44:37 Probably just like an accident, like bump the keyboard or something.
44:39 But if I'm over here and you just want to search for something, forward slash.
44:43 Now you can search.
44:44 What?
44:45 So they now have a beam in the browser.
44:47 Exactly.
44:49 So if you're on pypi.org and you want to search, forward slash.
44:53 Yes.
44:53 So that's pretty cool.
44:55 Yep.
44:56 All right.
44:56 That's it for the extras.
44:57 Nice.
44:59 I don't even remember what my joke is.
45:00 So that's good.
45:01 That'd be fine.
45:02 I mean, you're new to us all.
45:03 You ready?
45:05 Yeah.
45:06 All right.
45:07 Yeah.
45:08 Here we go.
45:08 Oh, yeah.
45:09 This is another one of these sort of like frustration type of things.
45:13 That's great.
45:13 This comes from the Programming Humor Twitter account.
45:17 You know, twitter.com slash Programming Humor, which is there's a lot of good stuff in there.
45:21 Some that I really liked.
45:22 I didn't want to necessarily put on the show.
45:24 But this one is developers really frustrated.
45:28 Like they're sucking in on their lips.
45:30 They're pulling on their cheeks.
45:31 They're going, oh, I hate this job.
45:32 I hate my life.
45:33 Why is this happening to me?
45:36 Never mind.
45:36 I misspelled a variable.
45:37 Good to go.
45:40 Yeah.
45:41 Linting.
45:42 Yeah.
45:42 Linting is good.
45:43 Linting.
45:44 Indeed.
45:44 Indeed.
45:45 If you just flip through the Programming Humor one, it's pretty good.
45:50 You know, this eight-year-old is learning Python after dealing with the syntax bug.
45:54 She asked, if the computer knows it's missing a semicolon here, why won't it add it itself?
46:00 I don't know.
46:01 I really don't know.
46:02 Yeah.
46:02 Yeah.
46:04 And like, so he follows up and says what he meant.
46:07 He meant colon, not semicolon.
46:10 But so many people are like, semicolon?
46:12 We need to use a semicolon for Python.
46:13 Exactly.
46:16 There are uses.
46:17 They're rare though.
46:18 All right.
46:19 Well, fantastic.
46:23 That last one.
46:24 See?
46:26 Yeah.
46:27 It shall not be spoken, but it's good, right?
46:29 Okay.
46:30 There's a lot of good stuff.
46:31 I recommend people go flip through that Twitter account.
46:33 Nice.
46:34 Brian, thank you.
46:36 As always, it's good to be back with you.
46:37 It's good to be back.
46:39 And Dean, thanks for coming on this side of the presentation and joining us for the show.
46:44 Thanks for having me.
46:45 Thanks for listening to Python Bytes.
46:47 Follow the show on Twitter via at Python Bytes.
46:50 That's Python Bytes as in B-Y-T-E-S.
46:53 Get the full show notes over at pythonbytes.fm.
46:57 If you have a news item we should cover, just visit Python Bytes.fm and click submit in the
47:02 nav bar.
47:02 We're always on the lookout for sharing something cool.
47:04 If you want to join us for the live recording, just visit the website and click live stream
47:09 to get notified of when our next episode goes live.
47:12 That's usually happening at noon Pacific on Wednesdays over at YouTube.
47:17 On behalf of myself and Brian Okken, this is Michael Kennedy.
47:21 Thank you for listening and sharing this podcast with your friends and colleagues.





