#275: Airspeed velocity of an unladen astropy
Watch the live stream:
About the show
Sponsored by Microsoft for Startups Founders Hub.
Special guest: Emily Morehouse-Valcarcel
Michael #1: Async and await with subprocesses
- by Fredrik Averpil
- People know I do all sorts of stuff with async
- Lots of cool async things are not necessarily built into Python, but our instead third-party packages
- E.g. files via aiofiles
- But asyncio has
asyncio.create_subprocess_exec - Fredrik’s article has some nice examples
- I started using this for mp3 uploads and behind the scenes processing for us
Brian #2: Typesplainer
- Arian Mollik Wasi, @wasi_master
- Suggested by Will McGugan
- Now released a vscode extension for that! Available on vscode as typesplainer
Emily #3: Ibis Project
- via Marlene Mhangami
- “Productivity-centric Python data analysis framework for SQL engines and Hadoop” focused on:
- Type safety
- Expressiveness
- Composability
- Familiarity
- Marlene wrote an excellent blog post as an introduction
- Works with tons of different backends, either directly or via compilation
- Depending on the backend, it actually uses SQLAlchemy under the hood
- There’s a ton of options for interacting with a SQL database from Python, but Ibis has some interesting features geared towards performance and analyzing large sets of data. It’s a great tool for simple projects, but an excellent tool for anything data science related since it plays so nicely with things like pandas
Michael #4: ASV
- via Will McGugan
- AirSpeed Velocity (asv) is a tool for benchmarking Python packages over their lifetime.
- Runtime, memory consumption and even custom-computed values may be tracked.
- See quickstart
- Example of astropy here.
- Finding a commit that produces a large regression
Brian #5: perflint
- Anthony Shaw
- pylint extension for performance anti patterns
- curious why a pylint extension and not a flake8 plugin.
- I think the normal advice of “beware premature optimization” is good advice.
- But also, having a linter show you some code habits you may have that just slow things down is a nice learning tool.
- Many of these items are also not going to be the big show stopper performance problems, but they add unnecessary performance hits.
- To use this, you also have to use pylint, and that can be a bit painful to start up with, as it’s pretty picky.
- Tried it on a tutorial project today, and it complained about any variable, or parameter under 3 characters. Seems a bit picky to me for tutorials, but probably good advice for production code.
- These are all configurable though, so you can dial back the strictness if necessary.
- perflint checks:
- W8101 : Unnessecary list() on already iterable type
- W8102: Incorrect iterator method for dictionary
- W8201: Loop invariant statement (loop-invariant-statement) ←- very cool
- W8202: Global name usage in a loop (loop-invariant-global-usage)
- R8203 : Try..except blocks have a significant overhead. Avoid using them inside a loop (loop-try-except-usage).
- W8204 : Looped slicing of bytes objects is inefficient. Use a memoryview() instead (memoryview-over-bytes)
- W8205 : Importing the "%s" name directly is more efficient in this loop. (dotted-import-in-loop)
Emily #6: PEP 594 Acceptance
- “Removing dead batteries from the standard library”
- Written by Christian Heimes and Brett Cannon back in 2019, though the conversation goes back further than that
- It’s a very thin line for modules that might still be useful to someone versus the development effort needed to maintain them.
- Recently accepted, targeting Python 3.11 (final release planned for October 2022, development begins in May 2021. See the full release schedule)
- Deprecations will begin in 3.11 and modules won’t be fully removed until 3.13 (~October 2024)
- See the full list of deprecated modules
- Bonus: new PEP site and theme!
Extras
Brian: Michael:
Emily:
- Riff off of one of Brian’s topics from last week:
- Automate your interactive rebases with fixups and auto-squashing
- Cool award that The PSF just received
- PSF Spring Fundraiser
- Cuttlesoft is hiring!
Jokes:
- *Changing * (via Ruslan)
- Please hire me
Episode Transcript
Collapse transcript
00:00 Hello and welcome to Python Bytes, where we deliver Python news and headlines directly to your earbuds.
00:05 This is episode 275, recorded March 15th, and I am Brian Okken.
00:11 I am Michael Kennedy.
00:13 And I'm Emily Morehouse.
00:14 Yay, thanks for coming.
00:16 I also want to give a shout out to Microsoft for Startup Founders Hub, and we'll learn more about them later in the show.
00:25 So welcome, Emily.
00:27 And if people aren't familiar with who you are, who are you?
00:30 Yeah, of course.
00:31 So I'm Emily.
00:32 I am the Director of Engineering and one of the co-founders of Cuddlesoft.
00:36 So we are a creative product development agency focused on web, mobile, IoT, and the cloud.
00:43 I'm also a Python core developer and the Python conference chair for this year.
00:49 Awesome.
00:50 That is awesome.
00:51 Said another way, you're quite busy.
00:52 Yeah.
00:53 I also have a 10-month-old, so, you know, not a lot going on in my life.
00:57 Yeah, no, a lot of time to binge watch Netflix.
00:59 10 months.
01:01 So are you pretty busy for PyCon already?
01:05 So interestingly enough, this is kind of a time that goes into autopilot in a way.
01:09 You know, like most things are already set in motion that need to be set in motion.
01:13 So it's really, we're working on the fun stuff right now, like, you know, speaker and staff gifts and stuff like that.
01:19 But otherwise, it's pretty smooth sailing and just sitting back and watching COVID numbers and hoping that we don't get another spike before April 9th.
01:28 Yeah.
01:29 Fingers crossed.
01:30 This will be the first PyCon after COVID hit.
01:34 So hopefully everything goes great.
01:35 I know people are excited.
01:36 Yeah.
01:36 Yeah.
01:37 Well, Brian, do I have the first one?
01:38 You do.
01:39 Do we have to wait?
01:39 Do we have to wait for me or can I talk about this?
01:42 Yes.
01:42 I'll wait.
01:43 Well, let's wait.
01:45 I'm very excited to talk about this one, actually.
01:47 This one comes from Frederick Aberpil.
01:50 I believe listens to the show a lot.
01:51 So hello, Frederick.
01:52 Nice work on this.
01:53 I was working on the Python Bytes website of all things, and I wanted to do some stuff with like uploading MP3s and having a bunch of automation happen behind the scenes.
02:04 And one of the things I did not too long ago is switch over to an async database.
02:09 I think we talked about moving to Beanie and some of the cool stuff I'm doing to like halfway move to async, but not all the way yet.
02:15 Not until we're quite ready.
02:17 But as part of that, I'm like, well, all this file stuff, this is kind of slow.
02:21 Like, this is a couple of seconds.
02:22 Is there a way to sort of set the web server free while we're doing this work?
02:27 Right.
02:28 And some of that involved calling subprocesses.
02:31 I thought, well, maybe there's some third-party package like AIO files that I could use that would allow me to asynchronously do subprocesses instead of the subprocess module.
02:43 So I did a quick Google search and I came across Frederick's article here.
02:46 And much to my surprise, I don't know if you all are aware of this, but built-in, asyncio has async subprocess management already.
02:55 That's pretty cool.
02:56 Isn't that cool?
02:56 Yeah.
02:56 Yeah.
02:57 Emily, have you played with this any?
02:59 Yeah.
03:00 You know, I actually think I've used this exact blog post, which is super funny.
03:05 I was actually just recently writing, like, CLI regression test and pytest.
03:11 And you basically, like, test running two different servers.
03:14 And I was, like, fighting with subprocess to get it to work.
03:16 I don't think they were using a new enough version that I could use async await, but I definitely remember referencing this.
03:22 So, yeah.
03:23 Yeah.
03:24 Very cool.
03:24 So, you can just say asyncio, the module, dot create subprocess exec for just running it.
03:31 Or if you need to sort of follow along and see what's going on, you can use even the shell one that requires shell commands like a CD or an LS type of thing.
03:41 And then you can just grab the standard out from set that to be asyncio subprocess dot pipe and so on.
03:49 You can get the results out of it and everything.
03:51 So, you just do things like await creating a subprocess with a shell or execing it and so on.
03:58 And then you can await communicating with it, which I think is pretty cool and so on.
04:03 So, not a whole lot more to say other than if you're doing stuff with subprocess and you're moving already into other areas where async and await are very doable.
04:13 Think FastAPI, SQL model, the SQLAlchemy 1.4 or later, where you're already doing a bunch of other async stuff.
04:22 You know, go ahead and write this in the async way so it just sort of flows into the rest of what you're doing.
04:26 That's pretty cool.
04:27 This is from like 2017.
04:30 It's an older article, isn't it?
04:32 Yeah, it looks like it.
04:33 Yeah, I mean.
04:34 Yeah.
04:34 It's news to me, maybe not news to the world.
04:37 Like Emily said, she was already working with it previously.
04:40 But yeah, I think it's great.
04:42 Right.
04:42 Well, the subprocess communicate is sort of people often shifted over to just run.
04:48 So, I'm hoping there's a run version of that too.
04:50 Yeah, probably is.
04:52 Anyway.
04:54 Cool.
04:54 Indeed.
04:55 All right.
04:55 Well, I'm going to explain some stuff to us, Brian.
04:58 I must.
04:58 I see the author of what you're about to talk about out in the audience as well.
05:03 Yeah, that's also.
05:04 That's very cool.
05:05 Well, this is pretty fun.
05:06 Definitely an exciting one.
05:07 Yeah.
05:07 Yeah.
05:07 So, this comes from.
05:08 This is TypeSplainer.
05:10 And let me explain it to you.
05:11 So, I don't know.
05:14 It's just this cool thing.
05:16 It popped up last week.
05:17 We saw it.
05:18 This is from Arian.
05:20 Sorry.
05:21 Arian Malik Wasi.
05:22 It's a pretty cool name, by the way.
05:26 But so, this is this little neat Heroku app that has you.
05:31 It's pretty simple.
05:33 You.
05:33 Well, I don't know how simple it is behind the scenes.
05:35 But.
05:36 Simple to use.
05:37 To use.
05:37 It's very simple.
05:38 You pop in any sort of Python code that has type hints in it.
05:42 And so, this one has like, for instance, we've got an example up that the default with
05:47 like a callable that takes a stir and an int and a generator.
05:52 And yeah.
05:54 So, there's a bunch of type hints in here.
05:56 This is even like kind of more than most people use all the time.
05:59 But.
06:00 And then you hit TypeSplain.
06:01 And it will show you what the different type hints mean and translate them into English for
06:08 you.
06:08 And it's just pretty, pretty cool.
06:13 I like it.
06:14 One of the things that Wasi said that he was also, when he was developing this, he was
06:20 on his way to developing a Visual Studio code plugin.
06:25 And so, there is a, if you search for TypeSplainer as a VS Code plugin, that functionality is available
06:33 to you right in your editor as well.
06:35 So, this is pretty neat.
06:37 Yeah.
06:37 This is really cool.
06:38 This explanation you have there, like dictionary of list of set of frozen set of, like, oh my
06:43 gosh, the description is something like a dictionary that maps a list of sets of frozen
06:49 sets of integers onto a string.
06:50 Like, that's way more legible and internalizable than.
06:54 Yeah.
06:55 How many brackets deeper we were?
06:57 Four brackets deep in that type information there?
07:00 Yeah.
07:01 It's interesting on Twitter with the announcement of it, or we heard about it through Will McCoogan,
07:08 or at least I did.
07:09 And some of the comments were like, not that this isn't cool.
07:16 It was like, oh yeah, this is cool.
07:18 But maybe Python shouldn't be this complicated if you have to explain it.
07:21 But it's...
07:22 Have these people done C++?
07:24 Let me just ask them.
07:25 I know.
07:26 You don't have to use types if you don't want to, but there's a lot of places where types
07:32 are helping out a lot.
07:33 And if you're running into somebody else's code that has some types on there that you're
07:37 not quite sure what that's going on, throw it in TypeSplainer and you'll be able to figure
07:42 it out.
07:42 Absolutely.
07:44 Yeah.
07:45 And I did actually take a look.
07:46 What do you think about this?
07:47 Oh, I think this is awesome.
07:47 I think I absolutely agree.
07:49 Like, you know, mypy has allowed us to do gradual typing and all that.
07:53 But a lot of times you do jump into somebody else's code base and you're like, whoa, these
07:57 are more types than I've ever seen.
07:58 And so being able to kind of convert it really easily is nice.
08:01 And I did actually take a look at how it works under the hood.
08:04 There's a really big if statement of like serialization.
08:08 But then it also, I'm a nerd for anything AST related.
08:13 And so it uses like the mypyParse under the hood, which is actually relatively complex
08:19 for what it needs to handle based on, you know, different Python versions and whatnot.
08:23 Wow, that's pretty awesome.
08:24 Nice.
08:25 Yeah.
08:25 The very first time you were on TalkByth enemy was to talk about the AST, the abstract syntax
08:30 tree, right?
08:30 Yeah.
08:31 It was right around my first conference talk back in the day.
08:35 Yeah.
08:35 Awesome.
08:36 Yeah.
08:36 Way back in the day.
08:37 I think we met in Vancouver to set that up or something.
08:39 When you were up, you know, we met at PyCascades there.
08:41 I generally think of myself as a smart person, but people that can handle doing AST work in
08:48 Python, I'm like, oh my gosh, you know, it's over my head.
08:53 Yeah, that's pretty awesome.
08:55 One thing really quick before we move on, Brian, if you go to the homepage of the typesplainer,
09:00 which is basically the back one.
09:01 So it's got this fairly pathological insane example to show you, like you can take crazy
09:06 stuff and explain it.
09:08 Yeah.
09:08 Yeah.
09:08 But you can type in there, like you can take that code away and put whatever you want in
09:11 there and then hit typesplain.
09:13 So if you just made like a function that just took, you know, yeah, exactly.
09:18 Give it a name and do a dot, dot, dot.
09:20 Yeah.
09:20 Give the function name.
09:21 You'll be good.
09:22 And then you hit typesplain.
09:23 Oh, it needs a function name.
09:27 Oh, I didn't.
09:28 It's not JavaScript.
09:29 Come on.
09:29 Brian knows.
09:32 Yeah.
09:34 Wasi.
09:34 I mean, it's not a super huge explanation of what an integer is, but like you can take
09:38 some random code and drop it and then go explain it to me.
09:41 Yeah.
09:41 I guess now you can also use the VS Code extension, which I haven't seen with.
09:44 Anyway, I thought, I thought this was cool as well and certainly saw a lot of people talking
09:49 about it on Twitter when it came out.
09:50 So, but final thing, I think this is noteworthy as well.
09:54 And I think it's worth mentioning.
09:55 Wasi is just 14.
09:57 So speaking of people like Emily, who can do like AST stuff like crazy, like also, if you
10:02 write this when you're 14, well done.
10:04 You're on your way.
10:05 Plus it's, it's really good looking for something right out of the gate.
10:10 So it looks nice.
10:11 Yeah.
10:11 Awesome.
10:11 Yeah.
10:12 I also think the like architecture of it's really great too.
10:16 So I really like that he embraced sort of building out the tool itself and then building a CLI
10:22 and a web interface and a VS Code extension.
10:25 So I think that is a really great example of how to structure a project like this too.
10:30 Nice.
10:31 Yeah.
10:31 That's awesome.
10:33 Hey, Emily, we lost your screen.
10:35 If you want to share it back or I can just add in while you're working on that.
10:39 Let me just follow up with Sam real quick who pointed out, be super aware of the limitations
10:44 of your hardware.
10:45 When you try to write files in async environments at this project that ground to a halt because
10:49 too many workers are trying to run at once.
10:51 Yes, absolutely.
10:52 Good point, Sam.
10:53 That is generally true for any limited resource that you point async things at, right?
10:59 If you're going like async against a database and a couple of queries will max it out.
11:04 And if you end up hitting it with a hundred queries at the same time, it's not going to
11:07 go faster.
11:08 It's only going to get worse as it like fights for contention and resources and stuff.
11:12 And then on this one, on the typesplainer, Brian Skin says, agreed.
11:18 Very nice work.
11:19 So awesome.
11:20 All right.
11:21 So this is another...
11:22 Emily, you're up for the first one.
11:23 Yeah.
11:23 So this is another one of those like new to me things.
11:26 But Marlene's article just came out and that's how I actually found out about it.
11:30 So Marlene wrote this really excellent introduction to using IBIS for Python programmers.
11:35 IBIS itself has been around for like seven years or so.
11:38 It's a project I think that was started by Wes McKinney.
11:42 But they are a productivity-centered Python data analysis framework for SQL engines and Hadoop.
11:49 So you get a ton of different backends.
11:52 It's going to compile to, you know, basically any flavor of SQL database and then a bunch
11:58 of like more data science focused backends.
12:00 But this popped up on my Twitter feed from Marlene and it's just a really great introduction.
12:06 Also just a really interesting sort of application.
12:09 So she went through and wanted to pull some like art information about a city that she was
12:16 going to visit because she likes to experience the culture of a new city.
12:19 So it just walks through like how to get data into it and then how to interact with it with IBIS.
12:25 So I'll actually switch over to the IBIS documentation.
12:31 Oh, and this is now just different because it's small.
12:34 But yeah, I think I was really interested in it because we have like a pseudo legacy system
12:42 that we're moving all the migrations out of Django and we're actually managing it with a tool
12:49 called Hesura.
12:50 So we're so used to having, you know, Django that's going to use SQLAlchemy and ORM and
12:56 everything just kind of is magic from there.
12:58 And you give it a YAML file and you get seed data, right?
13:01 Right.
13:03 So we're trying to figure out how to manage seed data in like a wildly different environment
13:07 where you have to load it in via like the Hesura CLI tool.
13:10 And you need SQL.
13:12 And I don't want to write SQL, like anything I can possibly do to avoid that.
13:17 So this was a really neat way for getting around needing that modeling.
13:24 So let's see if I can get to this.
13:26 Super cool.
13:26 Yeah.
13:27 It also looks like it integrates with Hadoop and other things that maybe are not direct
13:31 SQL compatible.
13:33 It might need a slightly different query language anyway, right?
13:35 Yeah.
13:36 And it's super interesting.
13:37 So they have a few different ways that it works.
13:39 So it directly will execute pandas and then it compiled in a few different ways to either,
13:45 you know, those SQL databases, Dask, Hadoop, BigQuery, like a bunch of different stuff.
13:51 But yeah, it's not necessarily just going to be straight SQL, but it's going to
13:54 handle that for you.
13:55 So you're really sort of, you know, future proofing yourself away from that.
14:00 But yeah, they just got a ton of like really intelligent ways to filter data and interact
14:06 with data in a really performant way.
14:08 I'm actually going to go back to Marlene's blog post real quick and do some quick scrolls.
14:13 It's also like one of the most hystonic like tools to integrate with SQL that I've seen.
14:19 So she gets to the point where she has this database table.
14:23 So you just tell it, you know, your table name and you set the variable and then you
14:28 can interact with it as if it's just a dictionary.
14:31 So you've got your art table and you want to just pull these columns and you've got it and
14:37 it's there.
14:38 So you would say something like a db.table of quote art and then you say art, you know,
14:45 art equals the art bracket for artists and display and then boom, you get those back.
14:50 Right.
14:51 Yeah.
14:51 That's awesome.
14:51 As a dictionary, I guess or something like that.
14:54 Yeah.
14:54 That's cool.
14:55 So there's a ton of different things that you can do with it.
14:58 I highly recommend checking out their tutorials.
15:01 They've got a ton of different options.
15:02 My favorite one is the geospatial analysis.
15:06 So if you check out their example, they're going to show you how to pull information out
15:11 of a geospatial database and then a really quick way of actually like mapping out the data.
15:19 So if you check out these examples, I know it's not going to come through necessarily on audio,
15:23 but you can, you know, pull information out of these like land plots and then tell it to graph it.
15:30 And it gives you, you know, a really nice looking graph with all the data there in like a whopping
15:35 10 lines of code.
15:37 Wow.
15:38 Yeah.
15:38 Generating that picture in 10 lines of code.
15:40 That's, that's awesome.
15:42 Yeah.
15:43 It's pretty neat.
15:44 It makes me think I should be doing more with geospatial stuff.
15:46 Like I don't do very much because I'm always afraid like, ah, how am I going to graph it?
15:49 What am I going to do?
15:50 Like, but there's a lot of cool layers in that graph and everything.
15:53 That's neat.
15:54 Yep.
15:54 Yeah.
15:55 The API reminds me a little bit of PyMongo actually, where you kind of just say, you know,
16:00 dot and give it the name of things.
16:02 And it's really kind of dynamic in that sense.
16:05 And you get dictionaries back and stuff.
16:06 So yeah.
16:08 But it's different databases, right?
16:10 Right.
16:11 Yeah.
16:11 But I do like that perspective.
16:12 Like it really is kind of taking any database, but especially taking a relational database
16:19 and giving it more of a document oriented interface to it, which is pretty cool.
16:24 Yeah.
16:24 This is cool.
16:25 I definitely want to check this out for, especially for exploration.
16:28 It feels like it's really got a lot of advantages for data scientists.
16:32 Like they're going to fire up a notebook and they're like, I just need to start looking at
16:35 this and playing with it.
16:36 And they don't really want to write queries and then convert that.
16:38 Right.
16:39 Well, it also looks like, as far as I can tell, it looks like both in this article and
16:44 in one of the tutorials on the main webpage is that there's a good relation, almost a one
16:53 to one relationship between SQL, things you can do in SQL and things you can do here.
16:56 So that people already familiar with SQL can transfer over pretty easily.
17:03 So that's pretty neat.
17:05 Absolutely.
17:05 Yeah.
17:06 This is a nice find.
17:07 All right, Brian, before we move on, can I take a second and tell you about our sponsor?
17:10 Yes.
17:11 Very excited about this.
17:11 I think it's a big opportunity for people.
17:14 So let me tell you about Microsoft for Startups Founders Hub.
17:17 This episode of Python Bytes is brought to you by Microsoft for Startups Founders Hub.
17:22 Starting a business is hard.
17:24 By some estimates, over 90% of startups will go out of business in just their first year.
17:29 With that in mind, Microsoft for Startups set out to understand what startups need to be successful
17:34 and to create a digital platform to help them overcome those challenges.
17:38 Microsoft for Startups Founders Hub was born.
17:41 Founders Hub provides all founders at any stage with free resources to solve their startup challenges.
17:47 The platform provides technology benefits, access to expert guidance and skilled resources, mentorship and networking connections, and much more.
17:56 Unlike others in the industry, Microsoft for Startups Founders Hub doesn't require startups to be investor-backed or third-party validated to participate.
18:05 Founders Hub is truly open to all.
18:08 So what do you get if you join them?
18:10 You speed up your development with free access to GitHub and Microsoft Cloud computing resources and the ability to unlock more credits over time.
18:18 To help your startup innovate, Founders Hub is partnering with innovative companies like OpenAI, a global leader in AI research and development, to provide exclusive benefits and discounts.
18:28 Through Microsoft for Startups Founders Hub, becoming a founder is no longer about who you know.
18:33 You'll have access to their mentorship network, giving you a pool of hundreds of mentors across a range of disciplines and areas like idea validation, fundraising, management and coaching, sales and marketing, as well as specific technical stress points.
18:46 You'll be able to book a one-on-one meeting with the mentors, many of whom are former founders themselves.
18:51 Make your idea a reality today with the critical support you'll get from Founders Hub.
18:57 To join the program, just visit pythonbytes.fm/foundershub, all one word, no links in your show notes.
19:03 Thank you to Microsoft for supporting the show.
19:05 Yeah, so $150,000 credit people get.
19:08 So if you're doing a startup, you know, that would have been awesome when I was trying to do a startup.
19:12 Now, this next thing I want to tell you about, I think, I think this kind of lives in your wheelhouse as well.
19:18 And keeping with the theme of the show, this one is recommended by Will McGugan.
19:22 So thank you, Will, for all the good ideas.
19:25 I know you're out there scouring the internet for all sorts of cool things to use on textual and rich and whatnot.
19:31 And this is one of the ones they said they are going to start testing on.
19:35 And that has to do with performance.
19:37 So the topic or the library is airspeed, velocity or ASV and the pip nomenclature.
19:44 And the idea is basically setting up profiling and performance as a thing that you can measure over the lifetime of your project rather than a thing that you measure when you feel like,
19:54 oh, it's slow.
19:55 I need to go figure out why it's slow for now.
19:57 So as you automatically do, as you do check-ins, as you know, like CI runs and stuff like that.
20:02 So probably the best way to see this is to just like pick on an example.
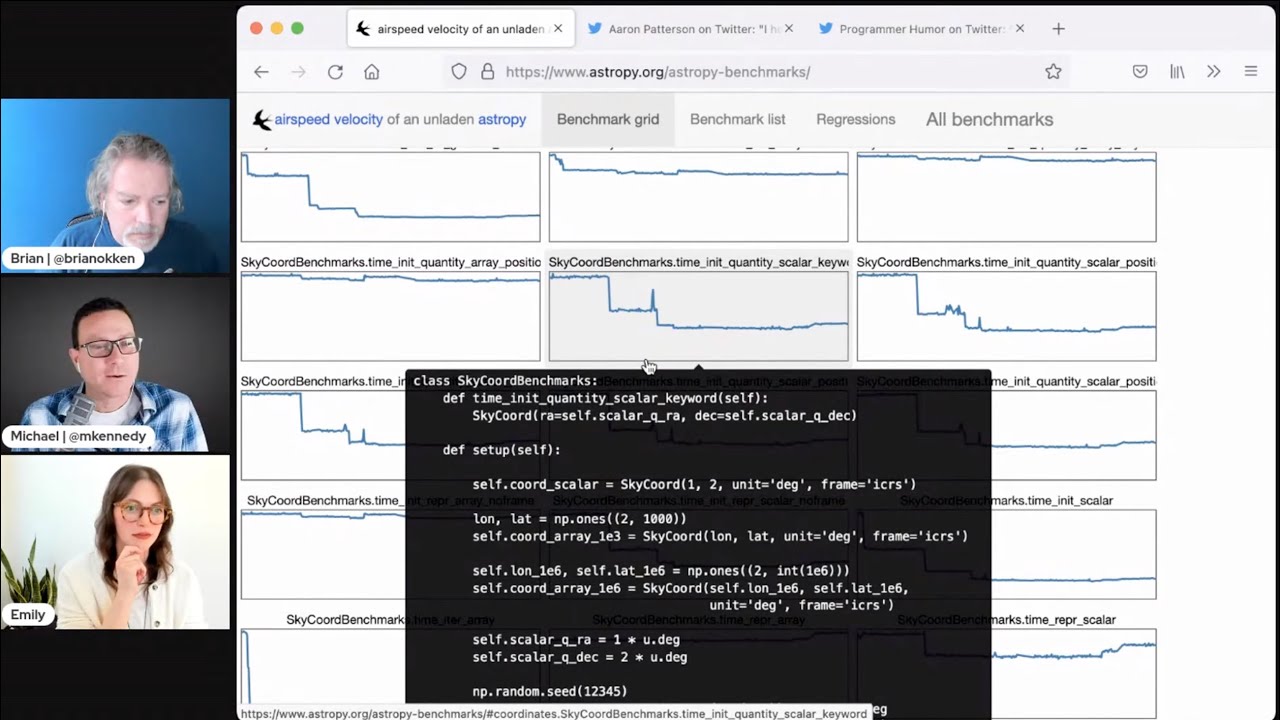
20:06 So if you go to the link in the show notes, airspeed, velocity, there's a thing that says, see examples for AstroPy, NumPy, SciPy.
20:14 I'll pick up AstroPy.
20:16 And you get all these graphs.
20:17 So each one of these graphs here is the performance of some aspect of AstroPy over time.
20:24 How cool is this?
20:25 Look at that.
20:26 That's pretty cool.
20:27 And if you hover over it, it shows you the code that runs that scenario.
20:31 Wow.
20:31 Yeah.
20:32 And, you know, this is a sample, this is a sample.
20:36 And then they did a huge improvement.
20:37 You can see there are like two massive refactorings on the sky coordinate benchmarks, you know, scalar, whatever this is.
20:44 Right.
20:44 This particular test they did there, it goes along pretty steady state.
20:47 And then there's a big drop and a little spike up and then another big drop and then steady state for a long time.
20:52 So wouldn't it be cool to have these different views into your system about like how it's performing over time?
20:58 Yeah.
20:59 So lower is better, right?
21:00 I believe lower is better.
21:02 Yeah.
21:02 I think lower is better.
21:03 You can pull up regressions.
21:05 You can say, okay, well, what got worse?
21:07 Like, for example, timetable outputter got 35 times slower.
21:13 So that might want some attention.
21:14 And it lists the GitHub commit or really technically, I suppose it just lists the git commit, which is probably on GitHub, which is on GitHub.
21:23 So that you can actually say, this is the code that changed that made it go 35 times slower.
21:28 Wow.
21:29 That's neat, I think.
21:31 I think one of the other challenges here is what about, what if you wanted this information, but you're only now learning about this project, right?
21:41 You're only like now realizing, wouldn't it be great to have these graphs?
21:46 How do you get those graphs back in history?
21:49 So Will pointed out that you can actually connect it with your git repository and it will check out older versions and run it.
21:57 It'll like roll back in time and go across different versions and different versions of Python and generate those graphs for you, even if you just pick it up now.
22:06 That's awesome.
22:07 Any idea of if it's like restricted to packages or if you can also apply this to general projects?
22:11 I think you can apply it to general projects.
22:13 I don't remember where I saw it.
22:15 I got to pull it back up here.
22:17 Somehow I've escaped the main part.
22:19 But yeah, I think if you look at the using airspeed, you basically come up with a configuration file that says, you know, this particular project with these settings.
22:32 And then here's like the run command.
22:34 You come up with one of these test suites.
22:35 I don't think it has any tie into packages per se because I think it goes against git, not against PyPI.
22:41 Yeah.
22:42 Yeah.
22:43 So pretty neat.
22:44 People can check that out.
22:45 But like here you can specify like which versions of Python or is this 2.7 stuff?
22:49 I don't know.
22:50 But yeah, so you can run it against all those old versions.
22:54 You can configure how it runs and so on.
22:55 Okay.
22:56 So you can even you can set up like since you're defining what's being timed, you can you can time large things like a particular workflow through lots of bits of code first.
23:09 Things like that.
23:10 Yeah, exactly.
23:10 So you basically come up with a couple of scenarios of what you would want to do that you're going to run against.
23:15 Here you can see like you can benchmark against like tags and things like that and git or branches.
23:21 Yeah.
23:22 Yeah.
23:22 So Will says he ran it.
23:24 Let's pop his up.
23:27 Ran it against two years worth of rich releases.
23:30 That's cool.
23:31 And found a performance regression.
23:33 Nice work.
23:34 I love it.
23:36 Optimizations that made rich slower.
23:38 Isn't that true?
23:39 Like this is going to make it better.
23:40 No.
23:40 Yeah.
23:42 So pretty cool.
23:44 And have to give a nice shout out to the full embracing of the my Python reference.
23:50 If you go back to the AstroPy version in the top left corner, it says airspeed velocity even unladen.
23:57 Oh, yeah.
23:58 I did notice that.
23:59 That's awesome.
23:59 It's nice.
24:00 Yeah.
24:02 Very cool.
24:02 Well, yeah.
24:04 Thanks for sending that over.
24:05 Well, yeah, I got some projects.
24:07 I'd like to do that on.
24:08 But speaking of testing things, this one comes from Anthony Shaw.
24:13 This is Perflint.
24:14 So this is a this is a pilot extension to check for performance anti patterns.
24:22 And it's Tony somewhere.
24:25 Anthony.
24:26 Some guy named Anthony Shaw.
24:29 Anthony Shaw.
24:29 I thought we mentioned him.
24:30 Tony Baloney.
24:31 Says.
24:32 Oh, here it is.
24:33 Project is an early beta.
24:35 It will likely raise many false positives.
24:38 So I'm thinking that might be why he went went with an extension to pilot instead of like an extension to PyFlix because or flicate because pilot gives lots of false positives.
24:50 No, at least in my experience with pilot.
24:55 It is takes some configuration to get happy with it because it will show you things that maybe you're OK with.
25:02 Like I threw pilot against some demo code that I have for like teaching people stuff.
25:08 And I'm using short variable names like, you know, X and Y and things like that.
25:13 And one of the one of the restrictions for pilot is you have to have almost most everything has to be three characters or longer.
25:20 And, you know, for production code, that's probably fine.
25:23 But if you have different rules, you can change that.
25:26 But back to this.
25:27 I really like I like the idea of having something look over my shoulder and look at performance problems because I I'm an advocate for don't solve performance problems unless you find that there's a performance problem.
25:39 So don't do premature optimization.
25:42 However, having some things are just kind of slow that you should get out of the habit of doing like when using list in a for loop, if the thing that you're using a list of already is an iterable.
25:56 That's that's a big performance hit if it's a huge thing, if it's because that turns an iterate iterable or a generator into an entire list.
26:07 It creates the list.
26:08 You don't need to do that.
26:09 So that's a that's a big one.
26:10 Anyway, there's a whole bunch of different things that checks for.
26:13 And I like the idea of just as you're writing code and as you're test, you know, running this and and trying to figure out if, you know, there's problems with it.
26:24 You can kind of get out of the habit of doing some of these things.
26:27 So, yeah, these are nice.
26:28 It'll catch just some of the things you might think you need to do.
26:32 You're not super experienced with or whatever.
26:35 Right.
26:35 Yeah.
26:36 Like one of the things here is a error W201 8201, which is loop invariant statement.
26:43 And this is one of that's kind of interesting is like there is an example of taking the length of something within a loop.
26:50 And if that never changes within the loop, don't do the length in the loop.
26:55 Take it out of the loop.
26:56 Those are.
26:57 Yeah, there are.
26:58 Exactly.
26:58 There's a few examples that you like you might not notice right away, especially if you've taken something that was a linear some linear code that you kind of added it inside of a loop and indented it over.
27:12 And now it's in a loop.
27:13 You might forget that some of the stuff inside might not might maybe shouldn't be in the loop.
27:18 So, yeah, this example here, you're doing it 10,000.
27:21 You're doing a loop 10,000 times.
27:22 And every time you're asking the length of this thing that is defined outside the loop and is unchanging.
27:27 So you're basically doing it 10,000, 9,999 times more than necessary.
27:32 Yeah.
27:33 Yeah.
27:33 So kind of fun.
27:35 I'm going to give it a shot.
27:36 See what I think in as using it.
27:39 So, yeah, definitely.
27:40 Emily, do you use some of these linters or anything like this that give you warnings?
27:46 Yeah.
27:47 Yeah.
27:48 I mean, I think we mostly use Playgate, but I'm definitely curious to try this out, too.
27:51 I can see how this would be tricky to get really consistent errors for these things.
27:58 So props to Tony Bologna for taking it out.
28:01 Well done.
28:02 Yeah, this is exciting.
28:03 I'm glad to see this coming out.
28:04 I know he was talking about it, but I didn't see actually anything on GitHub yet or anything.
28:09 So, yeah, very well done.
28:11 Yeah, this is cool.
28:12 I like stuff like this that really takes you to that next level of like, this is something that somebody would hopefully notice in a code review.
28:19 But if you can automate it.
28:20 Yeah, I think that's a great point.
28:21 I think a lot of these things that would have to be a discussion during a code review, if they could be automated and you could save the code review for meaningful stuff like security or, you know, like, how are we going to version this over time?
28:35 And it's going to be tricky.
28:36 Like, are you really storing pickles in the database?
28:39 Let's not, you know, stuff like that.
28:40 Yeah.
28:41 All right.
28:42 Pep 594 has been accepted, which is super exciting.
28:47 So, Pep 594.
28:48 If you don't know what that is, it's a Python enhancement proposal.
28:53 So, a proposed change to the Python language itself.
28:57 And so, this one is removing dead batteries from the standard library.
29:01 It was written by Christian Himes and Brett Cannon.
29:04 I think I saw a tweet from Brett saying that it had been accepted.
29:09 So, this is just really exciting for anyone who's followed along with any of this discussion.
29:15 It's been a long time coming.
29:17 I think there was a major discussion about it at PyCon US 2019.
29:23 It must have been.
29:25 And shortly after that, there was a pep.
29:27 But it's been since then that it's kind of been off and on in discussion and finally figuring out what is going to be the thing that really works for everyone and for the future of the language.
29:40 So, this is going to be targeting version 3.11.
29:44 So, just a quick recap of the release plan for that.
29:48 Development on 3.11 will start this May.
29:52 So, May 2021.
29:53 The final release, even for 3.11, is not until October 2022.
29:59 And even then, this is just going to be deprecating modules.
30:02 So, it'll be deprecations in 3.11 and 3.12.
30:05 And it's not until 3.13 that it will actually be fully removed from the language itself.
30:12 So, you can kind of get a glimpse into how long of a process this is and how big of a decision it was to get everyone on board.
30:21 Yeah, it didn't look at all like anything rushed.
30:23 When I went through and read this, it was like, here's the things that we think we can take out.
30:29 Here's why.
30:30 There's a table in there that shows third-party alternatives to certain things.
30:36 Mostly, yeah, that's the one.
30:38 So, there's certain things in here.
30:40 You're just like, you know, that probably isn't needed or it's really superseded.
30:45 So, there's pipes.
30:46 But then we also have subprocess, which will take care of that.
30:50 And that's a built-in one.
30:51 And then async core.
30:54 Just use async.io.
30:55 But then there's other ones.
30:57 There's a bunch in here I've never even heard of.
31:00 Yeah, that's the thing, right?
31:01 There's one called Crypt.
31:03 And it's like, look, just use Passlib or Argon or Hashlib or anything that is better and modern.
31:08 You know, this was from 1994.
31:10 Cryptography is not exactly the same as it was then.
31:14 So, you know, maybe it makes sense to take it out, right?
31:17 Yeah.
31:18 I guess.
31:19 Yeah.
31:20 Yeah, I think it's a really like, it's a thin line to walk, right?
31:24 Like, some people are using these and some of these modules maybe didn't have a lot of like maintenance over time.
31:31 But that also meant that there wasn't somebody watching it for bugs or security vulnerabilities or anything like that.
31:37 So, the balance of is it worth pulling it out if somebody was relying on it versus the maintenance cost or the lack of maintenance that could really.
31:47 Yeah, it's a liability, right?
31:48 There's a CGI library.
31:50 That's something else.
31:52 That takes you back from 95.
31:54 Yeah, that's how I started.
31:55 But not with Python.
31:57 I was doing CGI with Perl way back in 95.
32:00 Yeah, that does go back.
32:01 It also talks about whether that bit of code has a maintainer and whether that maintainer is active.
32:07 For example, CGI has no maintainer.
32:09 Like, no one wants that.
32:11 One of the things that's interesting here is you could take this code and you could still use it.
32:15 You could vendor it into your code, right?
32:18 Yeah, now you're the maintainer.
32:19 Yeah.
32:20 Yeah, exactly.
32:21 It's all yours.
32:22 You can have that.
32:22 But you could just go to CPython on GitHub, get that module, copy it over, and now you kind of still have that functionality.
32:30 Just, you're taking it on.
32:32 I expect maybe one or two of these might end up in their own GitHub repository as a package that is maintained.
32:38 They did talk about that, right, Emily?
32:40 About that being one of the possible paths they decided against.
32:43 Yeah, that was like the big conversation back at the Language Summit in 2019 was, you know, could we get libraries on a, you know, more independent release schedule and pull them out of the standard library entirely and just have them be sort of their own standalone thing?
33:02 Which, as I have briefly outlined since the release schedule for 3.11, you can see that it is on like a very long scale timeframe.
33:12 So, I definitely agree.
33:14 I think that some of these that people are still using, people are either going to go in there and grab the code and hopefully grab the license with it as well.
33:21 Or they're just going to become, you know, modules that enough people care about that live on their own in PyPI.
33:28 I don't see anything here that I would miss, but that doesn't mean that there's not people using them, you know.
33:32 So, on the good side, I mean, it totally makes sense to like remove things, especially stuff that's not getting maintained and there's no maintainer and that possibly has bugs in it now.
33:43 Nobody knows.
33:44 But, like, what are some of the good aspects, other good aspects?
33:50 Is it going to make the library or the Python standard or the install smaller?
33:56 Or, I mean, you'd think, anybody know the numbers on that?
34:00 Okay.
34:01 I don't know the numbers on that.
34:03 But that is something interesting to look at.
34:04 I would say the biggest change is, like, maintenance.
34:06 Just no one has to worry about whether there's a bug in CGI that someone discovers because it's just not there.
34:12 Yeah.
34:13 Yeah.
34:14 Yeah.
34:14 And especially with CPython, there's often a very big, like, barrier to entry.
34:20 So, like, if a CGI bug was even filed by somebody, where would you start to debug it and reproduce it sort of thing?
34:27 Right.
34:29 And then the other thing, too, is maybe somebody else goes through the effort to fix it.
34:33 But it always takes a core dev to review that PR and get it merged in.
34:38 And so a lot of times, if you don't have an owner of a module, it's just not going to get a lot of attention.
34:43 So as a whole, it should be hopefully an impact on how we interpret core developer time.
34:51 Because right now, I think we're at, like, over 1,000 PRs open on GitHub.
34:56 So a lot of times, you know, it's not just core developers writing code.
35:00 And a lot of times, you can have even more of an impact being that person that, you know, tries to review PRs and keep that number down.
35:07 Brian, out in the audience, points out that the comment threads on discuss.python and elsewhere are really interesting.
35:13 If you want to see examples of these old modules still in use.
35:16 Yeah.
35:17 Yeah.
35:17 I've got a couple of them here.
35:18 I think I linked them in the show notes.
35:21 But if they're not there, I'll make sure it's in there.
35:22 Nice.
35:22 Yeah.
35:23 You got a link to Brett's discussion there.
35:25 That's cool.
35:26 No, I think this is good.
35:27 I think this is good.
35:27 And quick shout out to a new theme, right?
35:29 Yeah.
35:31 So it's a brand new PEP site.
35:33 So it's pep.python.org.
35:34 And there's this really lovely theme on it.
35:37 It's really clean and modern.
35:38 You've got a nice dark theme here as well.
35:40 Cool.
35:41 Yeah, I noticed the dark theme.
35:42 That was cool.
35:42 And I think it even auto adapts to the time of day, which is great.
35:45 Brian, is that it for all of our main items?
35:47 I think it is.
35:48 It is.
35:49 Do you have anything extra for us?
35:51 Would it surprise you if I said no?
35:53 Yeah, it would.
35:54 Nothing extra.
35:54 I know.
35:55 I always have like 10 extra things.
35:56 No, I don't have anything extra this week.
35:58 Oh, really?
35:58 Yeah.
35:59 Nice.
36:00 Nice.
36:01 Okay.
36:01 How about you, Emily?
36:02 Cool.
36:02 Yeah, I've got a couple of extra things.
36:05 So as I was prepping for this, I looked at, I think it was just the most recent episode
36:10 before this one.
36:10 There was a blog post that I think Brian shared on like a better get flow that basically was
36:19 saying like, commit all your stuff, reset everything, and then recommit everything once
36:25 you're like ready to make a clean PR.
36:27 And so I wanted to share this as well.
36:29 This is one of my favorite tools that I learned about probably a few months ago.
36:33 Again, it's 2015.
36:35 Not a new thing, but new to me.
36:38 So you can do auto squashing of get commits when you're interactive rebasing.
36:44 So essentially, if you've got a ton of different commits, and you realize, oh, like, I had
36:50 a style commit, commit for styling all my new stuff, a few commits back, but like, I want
36:55 to make this one more change.
36:56 Instead of needing to, you know, rebase immediately or remember to, you know, stage it in a certain
37:02 way in the future, you can actually go ahead and just commit one more time.
37:06 And then you flag that commit that you're making with the fix up flag.
37:10 So it's just dash, dash, fix up, and then you tell it the commit that you're wanting
37:16 to sort of amend.
37:17 So you can just keep working like that, make it fix up commits.
37:20 And then the only thing that you do right before you PR is you tell it to rebase with auto
37:26 squashing.
37:27 So once you do that interactive rebase with auto squash, it's going to find all those fix
37:32 up commits.
37:32 And, you know, when you interact with rebase, you often have to like, move commits around and
37:38 tell it to squash into the previous commit.
37:39 You've got to get it in the right order.
37:41 This handles all of it for you.
37:43 And anything that's flag with a fix up, it finds that commit ID and auto squashes it back
37:48 in.
37:48 So you get a really, really clean history without having to like, redo all of your like, commit
37:56 work that you had done a lot of the way.
37:57 Yeah, that's really nice.
37:57 And this looks built into Git.
37:59 Yeah.
38:00 I've never heard of auto squashing.
38:02 I've definitely never used it, but it looks really useful.
38:04 Yeah.
38:05 Thank you.
38:05 Yeah.
38:06 All right.
38:06 What's your next one?
38:07 Yeah.
38:08 Yeah.
38:08 And then a couple, couple other cool ones.
38:10 There was a tweet from Dustin Ingram about an award that the Python Software Foundation
38:16 actually received.
38:17 It's from the Annie Awards, which is, you know, animation version of the Academy Awards sort
38:26 of thing.
38:27 And it was for Python's use in animation.
38:31 And so I think this is just super cool.
38:33 It's one of those like applications that you don't necessarily think about for Python all
38:38 the time.
38:39 I don't think it gets talked about enough.
38:41 I actually tried to find Paul Hildebrandt had a talk at PyCon Montreal, but I think it was
38:48 back before we were recording these.
38:50 So if you ever see Paul at a conference, you've got to ask him about, you know, how Python is
38:57 used in animation and at studios like Disney.
38:58 Oh yeah, that's really neat.
38:59 So exciting.
39:01 I would have never expected that, but that's great.
39:03 And congrats, Guido, for getting the award.
39:05 And two more quick ones.
39:07 The PSF Spring fundraiser launched yesterday and they're having a ton of fun with it launched
39:13 on at least Pi Day in the United States.
39:16 So if you donate with some sort of contribution that is related to the number Pi, you get like
39:23 a free swag band.
39:25 So just a fun twist on this.
39:28 You can donate $3.14 or $31.41 or $314.116.
39:35 It goes pretty far out.
39:39 If I remember Pi, there's a lot of numbers in there.
39:41 So yeah, just keep going.
39:43 Yeah.
39:43 Because whatever your bank account will allow.
39:46 Exactly.
39:48 All right.
39:49 Anything else you want to throw out?
39:51 Yeah.
39:53 Just one last quick one.
39:54 Just a small plug for us.
39:56 Cuddlesoft is hiring.
39:58 We have a bunch of different positions open, but we're especially always looking for Python
40:03 engineers.
40:04 We're a small team.
40:05 We're a team of about eight people right now.
40:07 Predominantly female engineering team.
40:11 And just like the pride of what I have done in the last few years of like building this
40:16 team.
40:17 So if you're looking for someplace that is always innovating, always focused on like really
40:22 high quality tested code.
40:24 But you want to work in a small team environment, get hands on with clients, get hands on with
40:29 product.
40:29 Come check that.
40:30 Cuddlesoft looks really cool.
40:32 You'd seem to be doing a lot of bunch of different small fun projects instead of just getting stuck
40:36 in like one huge legacy code.
40:38 So if you're looking to kind of bounce around from project to project and learn a lot, I think
40:42 that'd be a good place, right?
40:43 Yeah.
40:44 Yeah.
40:44 Absolutely.
40:45 All right.
40:45 Well, I have two jokes for us, even though I have no extras.
40:49 So I'm making up for it there, I guess.
40:50 Nice.
40:52 So Aaron Patterson said, I heard Microsoft is trying to change the file separator in
40:57 Windows, but it received tons of backslash from the community.
40:59 That's pretty funny, right?
41:04 But the forward slash works fine in Windows.
41:06 People just forget to use it.
41:07 It actually does.
41:09 It totally does.
41:10 And following along there.
41:12 Oh, Emily, I think this is the perfect follow on for you as well.
41:15 Do you ever look at people's GitHub profiles if they apply?
41:21 Like they say, yeah, right.
41:22 Of course.
41:22 I mean, it'd be crazy not to, right?
41:24 So this person here, you know, if you go to your GitHub profile, it will show you your
41:30 public activity over time.
41:32 And it'll say like on this day, you know, in September or on Monday, you had this much
41:36 work and then on Tuesday that much.
41:37 And it'll color like different colors of green.
41:39 Yeah.
41:40 So if you all check out the link here, we have a GitHub activity for a year that spells
41:46 out, please hire me in like the exact amount of commits on just the right day.
41:50 And I think that's...
41:52 I think there's some history manipulation going on here, but...
41:55 Probably some auto squashing.
41:57 I don't know.
41:57 I mean, hey, I would look at that and think that they had some decent enough Git skills
42:07 to manage that.
42:08 It does mean that you're probably not doing like normal Git work on one hand, but on the
42:12 other, like I'd have to think for a while to figure out how to get it to draw that out.
42:16 So that's pretty cool too.
42:17 It's one of the main reasons why I switched my blog to Hugo so that blog posts count as
42:24 Git commits.
42:25 Exactly.
42:26 Double dip.
42:26 Yeah.
42:28 Nice.
42:30 Well, that's what I brought for the jokes.
42:31 Nice.
42:32 Well, thanks everybody for showing up.
42:35 Thanks, Emily, for showing up here and also for the Walrus operator.
42:38 Love it.
42:39 Yeah.
42:40 And we'll see everybody next week.





