#284: Spicy git for Engineers
About the show
Sponsored by us! Support our work through:
Brian #1:distinctipy
- “distinctipy is a lightweight python package providing functions to generate colours that are visually distinct from one another.”
- Small, focused tool, but really cool.
- Say you need to plot a dynamic number of lines.
- Why not let distinctipy pick colors for you that will be distinct?
- Also can display the color swatches.
- Some example palettes here: https://github.com/alan-turing-institute/distinctipy/tree/main/examples
from distinctipy import distinctipy # number of colours to generate N = 36 # generate N visually distinct colours colors = distinctipy.get_colors(N) # display the colours distinctipy.color_swatch(colors)
Michael #2: Soda SQL
- Soda SQL is a free, open-source command-line tool.
- It utilizes user-defined input to prepare SQL queries that run tests on dataset in a data source to find invalid, missing, or unexpected data.
- Looks good for data pipelines and other CI/CD work!
Daniel #3: Python in Nature
- There’s a review article from Sept 2020 on array programming with NumPy in the research journal Nature.
- For reference, in grad school we had a fancy paper on quantum entanglement that got rejected from Nature Communications, a sub-journal to Nature. Nature is hard to get into.
- List of authors includes Travis Oliphant who started NumPy. Covers NumPy as the foundation, building up to specialized libraries like QuTiP for quantum computing.
- If you search “Python” on their site, many papers come up. Interesting to see their take on publishing software work.
Brian #4: Supercharging GitHub Actions with Job Summaries
From a tweet by Simon Willison
- and an article: GH Actions job summaries
Also, Ned Batchelder is using it for Coverage reports
“You can now output and group custom Markdown content on the Actions run summary page.”
“Custom Markdown content can be used for a variety of creative purposes, such as:
- Aggregating and displaying test results
- Generating reports
- Custom output independent of logs”
-
- name: "Create summary" run: | echo '### Total coverage: ${{ env.total }}%' >> $GITHUB_STEP_SUMMARY echo '[${{ env.url }}](${{ env.url }})' >> $GITHUB_STEP_SUMMARY
Michael #5:Language Summit is write up out
- via Itamar, by Alex Waygood
- Python without the GIL: A talk by Sam Gross
- Reaching a per-interpreter GIL: A talk by Eric Snow
- The "Faster CPython" project: 3.12 and beyond: A talk by Mark Shannon
- WebAssembly: Python in the browser and beyond: A talk by Christian Heimes
- F-strings in the grammar: A talk by Pablo Galindo Salgado
- Cinder Async Optimisations: A talk by Itamar Ostricher
- The issue and PR backlog: A talk by Irit Katriel
- The path forward for immortal objects: A talk by Eddie Elizondo and Eric Snow
- Lightning talks, featuring short presentations by Carl Meyer, Thomas Wouters, Kevin Modzelewski, Samuel Colvin and Larry Hastings
Daniel #6:AllSpice is Git for EEs
- Software engineers have Git/SVN/Mercurial/etc
- None of the other engineering disciplines (mechanical, electrical, optical, etc), have it nearly as good. Altium has their Vault and “365,” but there’s nothing with a Git-like UX.
- Supports version history, diffs, all the things you expect. Even self-hosting and a Gov Cloud version.
- “Bring your workflow to the 21st century, finally.”
Extras
Brian:
- Will McGugan talks about Rich, Textual, and Textualize on Test & Code 188
- Also 3 other episodes since last week. (I have a backlog I’m working through.)
Michael:
- Power On-Xbox Documentary | Full Movie
- The 4 Reasons To Branch with Git - Illustrated Examples with Python
- A Python spotting - via Jason Pecor
- 2022 StackOverflow Developer Survey is live, via Brian
- TextSniper macOS App
- PandasTutor on webassembly
Daniel:
- I know Adafruit’s a household name, shout-out to Sparkfun, Seeed Studio, OpenMV, and other companies in the field.
Joke:
Episode Transcript
Collapse transcript
00:00 Hello and welcome to Python Bytes, where we deliver Python news and headlines directly to
00:04 your earbuds. This is episode 284, recorded May 17th, 2022. I'm Michael Kennedy.
00:10 And I am Brian Okken.
00:11 And I'm Daniel Mulkey.
00:12 Daniel, great to have you here.
00:14 Thank you. It's an honor.
00:15 Yeah, it's an honor to have you. Now, before we get into our first topic that Brian's going to
00:20 tell us about, just give us a bit of your background.
00:22 Sure. I am an optical engineer in Southern California, but I have a significant amount of my time spent using Python for data analysis,
00:32 instrument control, and other things. So I've been doing it for a better part of the last five
00:37 years. And I've had a back and forth relationship with MATLAB and have finally married to Python,
00:42 so to speak.
00:43 Fantastic. You've finally been able to get out of your dysfunctional relationship with MATLAB.
00:48 Yes, exactly.
00:49 It sounds a little bit like you might live in a parallel universe to Brian.
00:53 Yeah, it sounds like it. We should definitely get you on testing code.
00:56 We can BS about that.
00:58 Sure. Yeah, I'd love to.
01:00 Brian, I would love to hear about our first topic. You want to talk about it?
01:05 It sounds very distinct, you know?
01:06 Distinctify. Yes, very distinct. So I ran across this. I can't remember how I ran across it. I guess
01:12 it doesn't matter. But one of the things I like, it's a Python package called Distinctify.
01:18 And it's very simple. It's a lightweight Python package to provide functions to generate colors
01:26 that are visually distinct from one another. So I was thinking like, you know, you got a chart,
01:33 like maybe you're taking user data or something, and you don't know how many lines you're going to plot,
01:37 but you're going to plot a whole bunch of lines. How do you pick the colors for what the lines are?
01:42 So this is a kind of a neat thing to just pick visually distinct colors. Pretty focused,
01:51 but it's pretty cool. And all you do is you kind of just give it, you give it like the number of
01:57 colors you want, and it gives you back the colors. And you can, it has display capabilities. So
02:02 you have to install extra stuff to make that happen. But you can display color swatches too
02:08 with it. And I was looking at some of the different colors that are available. Like one of the ones was
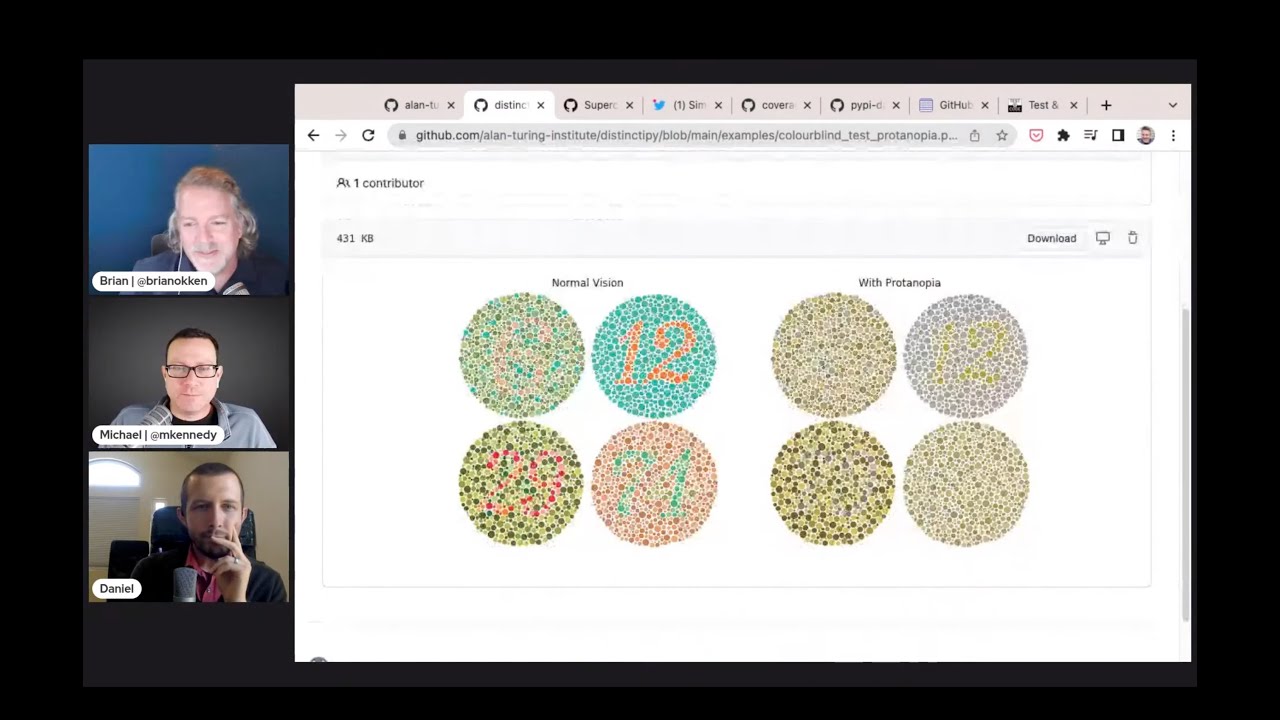
02:13 15 different colors. I think it's 15 colors for normal vision versus some color blindness. So if you
02:21 have colorblind people, you can pick based on some of that stuff. There's a whole bunch of examples in
02:27 the repo too, that it's kind of fun to look at. One of them was the like the normal colorblind one.
02:34 So was that it? No, that wasn't it. But there's some really cool examples of different colors. So if you just
02:42 give it a few, it just grabs a few, of course, but there's a whole bunch of neat ones, clusters and things.
02:49 So anyway, yeah, cool little library. It's great. Yeah, I like that they have, I noticed when I was looking
02:55 through it, they have a function for generating a color palette. And so you can generate a colorblind
02:58 friendly palette. So hypothetically, that works well for visual colorblind. And if it's in print and you're doing
03:04 black and white, so that was the most interesting thing to me. Oh, do you mean it has black and white?
03:07 That's interesting. Well, at least I think if you take a colorblind palette and you make it black and white, typically it's still a decent contrast. Oh, yeah. So you have to like worry about
03:15 printing things out. Oh, that's cool. Yeah, that's great. And one of its functions
03:20 is to take the color map that it generates and turn that into a matplotlib. Oh, yeah, yeah, yeah. It's cool.
03:26 Oh, that's what I was looking for.
03:28 Yeah.
03:29 Oh, wow.
03:31 And there's somebody in the audience who just found out they're colorblind.
03:34 Yeah, go ahead, Daniel.
03:35 And there's somebody in the audience who just found out they're colorblind.
03:38 They're like, is there a difference? What is this?
03:41 So my, I, yeah, one of my kids found out like in high school that they were colorblind.
03:48 So interesting.
03:50 Yeah. How would you know?
03:51 Yeah.
03:52 For a long time, you're just like, people tell me that's a color. I guess I'm not great at picking
03:55 out that color or something.
03:56 She had an art teacher said, I really love how you use both blues and greens in the sky.
04:01 And she was like, I intended to just use blue, but thanks.
04:05 I have a friend who went to art school and that was essentially his story that he always had really
04:11 vivid color choices because he didn't see the same as everybody else.
04:15 It was great. It was awesome.
04:17 That's pretty cool.
04:18 Yeah.
04:19 Cool. All right.
04:21 Ron, we ready for the next one?
04:22 Definitely.
04:24 Okay. So let's talk about SQL Soda or Soda SQL. So this is a open source CLI tool that if you're
04:33 doing like ETL, like ingest, transform loads type of stuff, doing other sort of analysis or
04:40 exploration of SQL data, it allows you to connect to your data source, like your database, and then
04:48 define tests for what invalid data looks like, right? Does this have to be a number? Can it,
04:53 does it just have to be not null? You know, what is it? So for an example, here, they're talking about,
05:00 here's the YAML file for a, like a warehouse, a data warehouse reporting type thing for Postgres.
05:07 So you just set up like your connection and your host and, and all that kind of stuff. And then
05:12 off it goes. So pretty neat. And then you can scan your data set to run tests against your data.
05:19 Isn't that cool?
05:19 That's right. It's Soda cool.
05:22 It's Soda cool. It is Soda cool.
05:26 Yeah. So you just say Soda scan and you give it the YAML file for the connection information and then a YAML
05:34 file for the types of things you want to test. So they've got this example of how you're talking to
05:39 one of the data warehouses and it's going and pulling in these config files. And it basically,
05:44 this example, it's testing 54 different conditions. Three tests were executed. Everything's good to go.
05:51 So, you know, if you're getting kind of data dropped on you or you're scanning, you know,
05:56 scraping data from other places on some kind of background job and you want to bring it in,
06:01 you know, if it's all automated, how do you know when it goes wrong? Right. So here's a nice,
06:04 simple way to express that.
06:05 Yeah. That's neat.
06:06 Yeah. And Brandon out in the audience says, I think we're looking at great expectations for this same
06:12 thing. And yeah, this is kind of a, I guess my, my first impression is this is a less code
06:18 way of doing what great expectations does. Right. So like you can just put together some YAML files
06:23 that define, you know, what you want to test for. Right. So for example, in this YAML file,
06:28 I can say the metrics are row count, missing count and missing percentage. And then I can test that the
06:33 row count is greater than zero. Right. And then the, another one is for the column, for the ID,
06:39 it's a UUID that it's, I'm allowing 0% of the UUID format to be invalid. Right. You know,
06:46 that's got like a certain structure to it. Right. It's like a, either a straight UUID or a string
06:50 that looks, that can be parsable over to one, I'm guessing something like that. So pretty cool. I
06:55 think that's probably the biggest difference. So if you just want to define kind of like declaratively,
06:59 like here are the conditions of which I want it to test. And then you want to just set it up to
07:04 continuously scan it. Looks good. The invalid percentage looks interesting because,
07:09 it's, it's an interesting addition of like, you know, there can be some bad rows, but we don't
07:16 want more than like 20% bad rows or something like that. Right. Right. Maybe you can't have zero
07:21 errors, right? Like you just, sometimes the data is just not there, but if it's a hundred percent not
07:27 there, then something's gotten terribly wrong or the data formats change and it's not called that
07:31 anymore or whatever in JSON, who knows? Daniel, what do you think? My, my data is always in CSV
07:36 files. So I have, I guess there are pros and cons to never having touch SQL, as I've heard
07:41 much, much easier to version control. Just put the CSV. Yeah. Anyway, I think, this one's pretty
07:51 neat. People can check it out if they're doing relational data stuff and they, especially if you're
07:56 doing a lot of like on demand, you know, not like you ask for it, but it's just on demand
08:01 processing or you're given a database and you want to check it out to see how it's, how it's doing.
08:05 So I won't go on anymore on that because I've got a ton of other extras. So kick it over to you,
08:10 Daniel. Cool. So let's see. There was a review article back in 2020 published in the research
08:18 journal nature, for anyone not in the research articles world, nature is one of the top level ones
08:27 for referencing grad school. We had some fancy work we did with quantum entanglement and we got rejected
08:32 by a sub journal of nature. So to get anything into nature is highly non-trivial. I will add the,
08:39 it's like the JAMA, the journal of American medical association of science. Basically it's absolutely one of
08:46 the top ones. I will say it's a review article. so it's easier typically to get a review article
08:51 than to say, Hey, this is bleeding edge research. It's going to change the world, but still the big
08:55 news is two things. One that there's a article by Travis elephant and others on array programming with
09:02 NumPy in nature. it's a big enough deal that they chose to publish this and it got through.
09:07 And it's, I think very significant that that software was something that was good enough to
09:12 publish. the other, and you know, they go through and they talk about kind of the fundamentals
09:17 of it all. There's one diagram I really like that sort of shows how the whole ecosystem stacks up.
09:22 You've got numbers. Oh yeah. That's a cool visualization. Yeah. And then you got scipy and
09:27 matplotlib and you know, the other plotting libraries. So there's the foundation. Yeah.
09:31 I was just going to say for people who are listening, it's like the tree of life for scientific libraries.
09:36 Sorry. Go on, Daniel. Yeah, that's absolutely right. So from that foundation, as far as algorithms
09:42 and plots, you go up to like specific method you're using, are you doing image processing?
09:47 Are you doing machine learning or something else? And off to domain specifics like AstroPy. And I think
09:52 you've had those guys on Python. So you've gotten to talk to them and then down to very
09:55 application specific. So it, you know, NumPy serving almost everybody who does anything numerical down
10:00 to like Q-tip, which is used for people working on quantum computers. So very large breadth being
10:07 discussed here. Q-tip. That's so cute. I like it. and yeah, so it's notable that Python got into
10:17 nature. And if you go search for Python, there are a lot of other articles, but it's also interesting
10:21 to see that they're willing to publish software. You guys have talked in the past about how you can't
10:26 always publish the software package and any research journal. So how do you get credit for that if you're
10:31 in academia? but this is an interesting take to see that nature goes to publish it.
10:35 Yeah, this is super interesting. And I think it's, it's very valuable to just raise awareness,
10:40 right? It's, you know, this is the water that we swim in, but not everyone. Everyone is immersed in
10:45 the Python data science tooling, right? Yeah. There's a lot of authors on here.
10:49 Yeah. I was trying to understand. I'm guessing those are the maintainers of the packages that
10:54 were included, but I mean, you, you don't have 20 people write one paper, so I don't know how,
10:59 I think it's, it's kind of like the LIGO papers or like the gravitational wave interferometer ones
11:03 where like this crazy list. It's like the first page of the article is almost all authors just
11:08 because there's so many people that worked on this for so long. So I'm guessing that's
11:12 yeah. And you can access it. Some, some, articles, some journals, you can't actually read
11:19 it unless you have a subscription, but this one's available. So.
11:22 Indeed. Yeah. A very cool pick before we move on. Maybe, you know, Daniel Alvaro and audience
11:30 has have any of you come across a way to validate pandas data frames against a schema, much like SQL,
11:36 soda, soda, soda, my scope. I feel like we have, but I don't remember, but yeah, I don't
11:44 remember either. Sorry. Maybe something we should seek out for the next one. And I think we might
11:51 get some answers in the audience. So we'll, we'll let them, inform us as we move on. So Brian,
11:56 what's next? well, this isn't Python specific, but I think a lot of Python people are using
12:03 GitHub actions. so, GitHub announced, I guess recently, supercharging GitHub
12:10 actions with job summaries. That's an article that we'll link to. And, basically the, it's pretty,
12:17 it's pretty cool. I can't wait to try this. I'm using GitHub actions. And, the gist is you can
12:23 now have Markdown go directly into your GitHub job summary sort of thing with like this,
12:30 this crazy, global variable called GitHub step summary. but it, it's got marked out to it.
12:39 And I'm like, well, what can you do with this though? But, Simon Willison, released,
12:44 was, was tweeting about it. And, and then said, and then Ned Batchelder said, Hey, I'm using it too.
12:51 So Ned, has a little example on his, on coverage.py that shows, what does it show?
12:58 It shows, you, you get this nice total coverage percentage. If you want to put that
13:03 in your, in the coverage for your, your, your repo, you can do that. Interesting that
13:10 coverage.py is not a hundred percent covered. I don't know why I find that funny.
13:16 The irony. I love it. but, and then, so Simon also listed, data set is, has an example on data set, you doing, adding some extra stuff, to, to,
13:30 what is he adding changed files? Oh, he's got a, a tool that does, looks for,
13:36 how many files have changed and, and recently. And he actually just wrote, he just wrote a
13:42 write write up for that. So we're linked to that as well. So GitHub action job summaries,
13:47 and he shows how it, how it works. You can pop, pop out stuff. And I love Markdown.
13:52 So even little code fences and all sorts of stuff. That's very cool. If you want to structure something
13:56 real nice like that. Yeah. It even has, so, so supposedly it's got a whole bunch of stuff.
14:02 It's got like, you can do tables even. So that's neat. And emojis. Why not? So,
14:08 Oh yeah. Pretty cool. Put a little fire emoji in there. Yes. Do it. Does anybody get images?
14:13 Like if you create an image during the action, can you reference it? I do. I don't know.
14:18 Didn't doesn't mention images, but maybe you could base 64 and code it and embed it as a data.
14:23 Oh, wow. It even does a mermaid, which is a way to do diagrams, within it. That's pretty neat.
14:31 Very nice. Like flow charts. Yeah. Fantastic. This is a good one. I need to learn to do more
14:36 with GitHub actions. I don't do very much with them. I love them. They're like, it was, I used to use
14:41 Travis back in the day, but, and, I think these are way easier. So, you know, do you do any of
14:48 those sorts of things? Any, CI automation type stuff? at a previous company, we used Azure DevOps
14:54 and set up some stuff to build packages and build applications, but, not at the moment. It's just,
15:00 it doesn't, it doesn't happen to be any code bases I have, but I need that.
15:04 Yeah. Very cool. All right. Well, I've got an interesting one here. I want to dive into it,
15:09 you guys. So this one, let me give some attribution here. This one was sent over by
15:15 Antomar, from meta. And then this is a writeup by Alex way good. And what it is, is it's the,
15:24 basically the notes for all of us who are not there for the 2022 Python language summit.
15:30 So that's pretty cool. There were around 30 core developers, triagers, and special guests gathered
15:36 the day before PyCon. And so they, they had a bunch of different talks and ideas they discussed
15:43 quick summary. Really it's about so much of this is about performance and parallelism right now.
15:50 And then there's a lot of maintainability back channels, back flows here. All right. So
15:58 coming to these first, Sam Gill made a huge splash last year when he talked and he introduced the no
16:04 GIL work that they had done for, I thought I'm three, eight, I believe. I can't remember three,
16:09 three, nine. No, it was three, nine for them. Cinder was three. So for three, nine, and there's a lot of
16:17 interesting optimizations and whatnot in that talk. So the idea is, could we live without a
16:23 global interpreter lock? Larry Hastings tried the galectomy, sort of said, you know, it's too much
16:30 of a penalty to try to live without it. But this no GIL work that Sam Gross did actually had very small
16:37 overhead in terms of what it added, but potentially removed some of the GIL things. So there's a lot of
16:43 analysis of that. People were excited, but they, how is it written? It says robust, there was robust
16:51 questioning. One, I guess one of the biggest parts that they discussed was maybe this should be a fork
16:59 of CPython. There should be a no GIL version of Python. And, but Sam is like, I really don't want to
17:07 have just another separate version of Python. I really want this to just help everyone. So pretty
17:13 interesting. I think originally it was maybe going to be a runtime flag you could pass to Python,
17:18 but it's looking like it more likely is going to turn out to be a compiler flag. So you'd have to have
17:23 a no GIL build, even though it's from the same source code. So yeah, a bunch of interesting things,
17:29 concerns about how it's going to work with like C libraries and so on. But that's, there's,
17:35 all these are pretty interesting read-ups, reads, write-ups. So Eric Snow did a presentation on his
17:43 per interpreter Gill, which is interesting in how it approaches a slightly different problem
17:49 than say Sam Gross. So Sam is trying to get it out of Python. Eric is saying, well, if we could just
17:55 have a sub interpreter, like a little mini in-process interpreter that runs per thread, then they can all
18:00 GIL to their heart's content. It doesn't matter because it's all single threaded, right?
18:04 But what's interesting is if you go look at this one in here, we've got this one. It says something
18:12 like way back in 1997, this idea of multiple sub interpreters was added by Guido, but it really
18:21 hasn't, nothing has been done with it. And when somebody tries to do stuff with it, there were
18:27 thousands of global variables. And if you're going to have per interpreters, you have to somehow have
18:32 those not shared because then you're going to have the GIL back on them, right? You have that locking.
18:36 So due partly to the deprecation of some of the old libraries and stuff, it's gotten a little simpler, but
18:44 no, that was it for the next write-up. But anyway, they reduced this to almost
18:49 1,000, to 1,200 remaining globals.
18:52 So needless to say, it is not totally solved here, right?
18:58 So again, one of the possible worries of all this stuff is, well, how are the C extensions going to deal with this?
19:03 Like they don't know about multiple sub interpreters.
19:06 Yeah. So anyway, that's another one of the main threads going on there.
19:10 Let's see.
19:11 Then this is probably the biggest deal.
19:14 This is Faster CPython 3.12 and Beyond by Mark Shannon and Guido Van Rossum.
19:20 So stepping back, a release.
19:22 Python 3.11, if you haven't heard, is fast. It's supposed to be 1.25 times faster than 3.10.
19:29 How about that?
19:30 Yikes.
19:31 This blows me away. In one year, they were able to make Python 1.25x faster, and it's been out for
19:38 30 years. It's not like, oh, well, we released it last year, and now we've learned some things.
19:42 It's really, really, really solidified in the way that it is, and then still, there's a lot of work.
19:48 And this apparently is just the beginning.
19:50 This is like a five-year plan to add all sorts of optimizing JIT compilers and all
19:56 sorts of things.
19:57 How did they quantify that, or what subset of the language was I tested on?
20:02 That's the tricky thing to say.
20:04 Python is 25% faster.
20:06 Doesn't matter what you do. Even if you're just waiting on a database, it's still 25% faster.
20:10 Does it just overclock your computer in the background?
20:12 It liquid cools it.
20:14 I believe that number comes from the unit tests, like all the tests for CPython.
20:22 I'm not 100% sure, but I believe that was the conversation.
20:26 And so one of the big things coming is possibly a JIT, an optimizing JIT compiler. So right now, they've
20:32 found a way to optimize individual bytecode instructions to make the runtime
20:38 smarter and go, oh, I see what you're trying to do.
20:40 We could have a specialized version of that. But that's on a per line basis. Like, how about
20:46 inlining this method? Because I only see it called in two places or something like that, right? So you need something that
20:52 can look more broadly at the code. So that's this idea of the JIT compiler and
20:56 so on. So yeah, this is really good. But all three of these things I've talked about
21:00 are like, both, they might help each other, but they also might inhibit each other, right? So like the
21:06 no-gil work might interfere with some of the optimizations that they're doing
21:09 over here and the multiple sub-
21:11 interpreters also might be some interplay that they've got to be got to be worked out. So I'll just summarize the rest.
21:18 WebAssembly. And so we've talked about PyScript last time and Pyodide.
21:24 Pyodide. This is the official CPython build target for just CPython. So this is really
21:34 interesting. That is sort of a more from the core devs rather than somebody coercing
21:38 CPython into a different build on their own. So that's pretty neat.
21:41 f-strings. Apparently the F-string parser is kind of this weird side parser thing that's not actually
21:48 part of the Python code parser. But now we have peg, the peg parser. It can support more of this.
21:53 and sort of unify that.
21:55 So yeah, there's something like 1,400 lines of customized C code for parsing F-string.
22:02 Well, the people who wrote it knew. They did a lot of work.
22:06 There's like 600 of the global variables right there.
22:10 Exactly.
22:11 The most important 1,400 lines in all of Python right now. They have string functionality.
22:19 Then two of the big optimizations from sender.
22:24 That's the Python 3.8 specialization from meta.
22:28 One is, this is a presentation by Itmar Osterreicher.
22:32 So this is the person who sent this in actually.
22:36 This is looking at async methods.
22:40 And if you can be sure it's not actually going to await, treat it like a regular method.
22:45 So, you know, if you have an async method, you might say, do this, do this,
22:49 do this.
22:49 If I already have the value in the cache, return, else await database call,
22:54 right?
22:55 If you already have it in the cache, why do you need to create a co-routine,
22:59 schedule it on the back, on the loop, wait for the loop to get to it, and then return?
23:04 Just boot.
23:04 Just call it.
23:05 Like a regular method, just give us the answer.
23:07 That's the idea.
23:09 There's some interesting ideas that it might change runtime ordering, although I don't know
23:14 there was any promises of runtime ordering, but yeah.
23:17 So that one's interesting.
23:18 Also, the issue and PR backlog, now that we've moved to GitHub, apparently,
23:24 there are issues that are still 20 years old that are still open.
23:29 And traditionally, the core devs and the triagers and so on have approached
23:36 these things like, well, should we close this or probably we need to keep it open
23:40 because it's important for historical reasons.
23:42 And they're starting to talk about like, this is not helpful for anyone.
23:45 Maybe our first question is like, why should we keep this open?
23:49 And if the answer is not clear, just close it.
23:51 There's a lot of talk about, well, this historical stuff and maybe someone
23:55 wants to pick it up.
23:55 If it were me, if I got to pick and obviously I don't, so it doesn't really matter,
23:59 I would just go, if it's older than two years, just close it.
24:02 Like there's a script that just says, over in two years, select all, close.
24:05 Now let's go through and figure it out because at some point, you know, if you've got 20 years
24:10 of you should make this change, maybe even, maybe these, these things aren't even
24:14 relevant anymore, you know, or things have moved beyond it or it doesn't make sense
24:17 in 2022.
24:19 I don't know.
24:19 But I'm just, mostly what I got out of the articles, I'm thankful that I don't
24:23 have to deal with 20 years of issues and PRs.
24:25 But also, they don't go away if you close them.
24:30 They're still there if people really want to see them.
24:32 You can, so I think they should be, maybe two years might be a little extreme,
24:37 but at the very least five or three or something like that.
24:40 There should be a number where that's true and that number should be less than 30.
24:43 And it's, and it's a smaller number than 20, right?
24:47 So, yeah.
24:48 All right.
24:49 This is a long section.
24:50 Last thing, I'll close it out with this.
24:52 Immortal objects, the path forward for immortal objects.
24:56 So let me ask you guys this.
24:58 Can you change none or true or false?
25:00 No, right?
25:01 Does, do you think it's ever going to go away?
25:04 Like, are we done using true and then it's just going to get garbage collected
25:08 or reference counted out of memory?
25:09 Nope.
25:10 But you know what?
25:11 Every time you interact with true and false, it's still incrementing its ref count.
25:15 Interesting.
25:17 And none and stuff because it's an object, right?
25:20 Oh, yeah.
25:21 And so, this discussion is like, isn't there some that just shouldn't be participating
25:26 in reference counting because they're, they're just fundamental to, you know,
25:32 like the idea of a class, like the structure of a thing that defines
25:36 what a class is, true, false, the numbers, like the low numbers, like there should be
25:40 some that are not consuming that memory because they don't need to keep track
25:45 of that section and so on.
25:47 Right.
25:48 So anyway, this was the proposal.
25:49 Again, it's complicated is the story, but yeah, I do something a little bit like this
25:57 on Talk Python, the training site.
25:59 So I've done a lot to tweak the garbage collection around there and really change
26:04 the defaults of like, what are the triggers for garbage collection?
26:09 So if I've got this many allocations and so on, and one of the things you can do
26:13 is you can tell it from here on, like what has existed up until now, freeze that
26:19 and don't, don't look at it when you have to look for cycles.
26:22 Right.
26:22 So I just, in my app startup when it's a, it's kind of imported the things
26:27 and it's about to start, it just says, okay, everything that you've done
26:30 to come to life, just don't, don't trick that anymore.
26:33 Anything else I make from here on out, please clean that up.
26:35 And it, it seems to, it's kind of a super cheap, cheap overs, version, but you still get
26:39 reference counting, right?
26:40 Yeah, that's definitely an optimization that I think is worth it for some of these
26:45 immortal objects.
26:46 Why not?
26:47 Yeah.
26:47 I mean, we shouldn't be reference counting on none.
26:49 That's kind of weird.
26:49 Unless, unless it slows things down by having like some.
26:53 It does.
26:54 That's the thing that's crazy.
26:55 So over here, they're like, all right, here's the deal.
26:57 we, we shouldn't, we shouldn't have to worry about this.
27:01 And so, where was it?
27:03 Except it adds an if statement to everything, right?
27:06 Yeah.
27:07 It says the naive implementation of this makes it 6% slower, not faster.
27:13 Like, oh no.
27:14 It makes sense.
27:16 Yeah.
27:17 And we think we can make it only 2% slower.
27:19 It's going to be slower though.
27:22 Yeah.
27:22 Well, the thing is, normally you would just reference count it.
27:26 You just go none plus equals one, right?
27:29 Or plus plus, minus minus.
27:31 But here you're like, you have to have a test.
27:33 Like, if it's an immortal object, do this, else do that.
27:36 And it's just like that bit in the hot loop of the runtime is just apparently overhead,
27:41 you know?
27:41 Yeah, for everything.
27:42 So everything you reference has to check to see whether or not it's an immortal object.
27:46 before it does the reference counting.
27:48 So.
27:49 Yeah.
27:49 Maybe it has a NOAA method on it.
27:52 I don't know.
27:53 I think it probably works straight on the field though.
27:55 All right.
27:56 Much like Highlander, Alvaro says, there can only be one none.
28:01 All right.
28:04 Well.
28:04 Straight off.
28:05 Yeah.
28:06 Yeah.
28:06 This is definitely an interesting trade off.
28:07 All right.
28:08 Well, I think that's more than enough for the language writer.
28:11 But it was really cool that Alex wrote that up and NMR sent it in because that's a good insight
28:16 to what's next.
28:17 Cool.
28:19 So, it's my turn, right?
28:22 Given that.
28:22 Sorry.
28:23 So, yes, you're good.
28:24 Go, Daniel.
28:24 Cool.
28:25 So, people in the software community are blessed with many options for doing source control.
28:31 You know, you've got get SVN, Mercurial, other historical ones that maybe aren't as well used,
28:36 but optical engineers, mechanical engineers, electrical engineers, everybody else doesn't have it
28:41 nearly as good as the software community.
28:43 So, anytime I see an option for that, it definitely sticks out in my mind.
28:47 So, I don't remember how I found this, but came upon Allspice fairly recently,
28:52 which is Git for people who are doing circuits.
28:55 This is cool.
28:56 And so, it has, it looks exactly like Git.
28:59 You've got version control, you've got all the things you expect to have.
29:02 It's compatible with some of the common electrical design programs, but it really just
29:08 gives you the ability to do all these sorts of things that you take for granted
29:12 if you're in a sophisticated workflow like software, but that you wish dearly
29:16 you had for any other discipline.
29:18 So, when you put something in a source control and you diff it, what do you get?
29:22 They have...
29:24 Are you diffing graphics?
29:26 Are you diffing some sort of definition file that defines the circuit?
29:30 So, they have, you know, one of the first things they have is a diff tool
29:34 because they know that that's kind of one of the big questions, right?
29:36 Is how do you compare the schematics?
29:37 So, they have a way to do it visually and you can look at all the changes
29:42 and it looks like, you know, they're highlighting each commit to whatever change
29:45 was made on the schematic.
29:46 Oh, that's cool.
29:47 Yeah.
29:48 Oh, that is very cool.
29:50 Yeah.
29:50 Yeah.
29:51 So, one potential question would be, well, great.
29:54 You know, it's nice that you can do that on the internet, but I work at a commercial
29:57 company that doesn't want to do that.
29:58 But they do have both, what they have a, they have self-hosting and they have a
30:05 government cloud version if you're subject to things like ITAR, EAR.
30:09 So, you can, in the same sense, the Git has an enterprise option, Allspice also has an enterprise
30:14 option.
30:15 like an on-prem, self-hosted version.
30:17 Yeah.
30:17 So, you don't have to give away your secrets.
30:19 Yes.
30:20 But I have no personal experience with it, but it's very promising and exciting to see
30:26 somebody trying to come up with better ways to do engineering work besides just software.
30:31 You can even configure it to integrate with Tortoise Git, like the Windows Explorer
30:36 right-click type of Git.
30:37 Yeah.
30:38 So, exciting stuff.
30:40 hopefully somebody helps out the Mechies and the optical engineers as well one day.
30:44 Yeah, I mean, there's always large file support, but the diff is terrible,
30:49 right?
30:51 So, usually.
30:52 Yeah, you're looking at binary files or stuff that's, yeah, humans are so good
30:58 at processing images that if you have a visual comparison that that's orders of magnitude
31:01 better than trying to look at lines of your, even if it is a plain text file that you can read
31:07 through.
31:07 Yeah, definitely.
31:09 Yeah.
31:11 Here's your XML with its namespaces.
31:15 Good luck.
31:17 What?
31:18 What does this mean?
31:19 Yeah.
31:19 Well, cool.
31:20 I like it.
31:21 All right.
31:22 I do too.
31:22 Brian, you got any extras for us?
31:24 I, yeah, actually.
31:26 So, I've been busy.
31:27 I've been, kind of like this back stream of test and code episodes.
31:30 So, the most recent one is that I, put out was with Will McCoogan.
31:35 We're talking about rich and textual and textualized.
31:38 It's really fun, really fun one.
31:41 But, actually, so, since we talked last Tuesday, I've got four extra episodes that have
31:45 come out.
31:45 So, we've got teaching, including testing with web front-end stuff, which was,
31:53 it was kind of an interesting story about, like, basically, if you're college-level
31:56 students, but they're new to coding, when do you include testing?
32:01 And, and, the Carl says, right away, why not?
32:05 So, also, developer and productivity episode, I think that's, oh, yeah, and a Python,
32:12 Django, rich and testing article, so, or episode, so, lots of goodness over on testing
32:18 code.
32:19 they have a Django rich package, apparently.
32:22 Yeah, that, that, that was just for other, like, the CLI, the Django, CLI stuff,
32:29 including rich with that, which was great, but they've incorporated, incorporated the,
32:35 that into the test runner, so the Django test runner can do rich tracebacks,
32:40 which is pretty cool.
32:42 Perfect.
32:42 So, how do you know you got anything else you want to give a quick shout?
32:46 Sorry.
32:47 Sure.
32:47 So, you know, Adafruit's a well-known company for doing maker electronics
32:53 and, oh yeah, I don't have the links up, sorry.
32:55 But, you know, Adafruit's well-known and they do a good job of focusing at
33:00 the first five-minute experience of getting you up to speed with something on electronics.
33:03 But there are other companies that do the same thing as well, so I was going to
33:06 shout out SparkFun, Seed Studio, and then other companies like OpenMV, who has a focus on
33:12 machine vision.
33:13 And they're less geared more for the people at the entry level, so maybe if you're a
33:17 little more comfortable with certain things or a little more comfortable,
33:20 you know, exploring those based on your own, they could be good options.
33:23 Right.
33:23 More specialized, maybe, for people who are trying to actually build.
33:26 Or if you go to, yeah, if you go to Adafruit and what you want is out of stock,
33:29 you can check some other places too.
33:31 Which, unfortunately, happens a lot these days.
33:33 It's, yeah, those things come and go.
33:35 A lot of demand.
33:36 Awesome.
33:37 All right, I do have some.
33:39 Cool.
33:39 Yeah, that's right.
33:40 I do have some extra ones, but I kind of got a lot, so.
33:43 All right, let's see.
33:44 I'll go last.
33:46 All right, the first one is, I always love a good documentary on tech stuff,
33:49 and sometimes these are super cheesy, but there's a documentary called Power On,
33:53 The Story of Xbox, which is a four-hour video, which you can watch on YouTube,
33:58 which I'll link directly to the YouTube video.
34:00 And it's really good.
34:01 It's really interesting.
34:02 Whether you love or hate the Xbox, I honestly don't care that much one way or the other,
34:07 but it's just an interesting sort of view of like the last 20 years of technology
34:11 from the sort of the gaming side.
34:13 So if people are looking for something to watch and they want to spend four
34:16 hours doing it or spread it out, you know, they can check this out.
34:19 All right, speaking of videos, not that one.
34:23 This one, I took, so recently I released my Git course on sort of a pragmatic
34:29 introduction to Git and I decided I wanted to share one part of it with a broader
34:34 world.
34:34 So I released a video called The Four Reasons to Branch with Git and I put that on
34:38 YouTube and people can check that out.
34:39 So it's like an hour long video I posted this week.
34:42 And then this one comes to us from Jason Perkore saying, how cool is it to
34:48 see Python showing up like right on the front page of various places?
34:51 So there's this place called EasyPost, easypost.com, which allows you to like do labels
34:57 and track your labels and stuff.
34:58 But if you just scroll down just a little bit, it says, you know what, why don't you
35:01 just either buy labels or you can just use this Python API right here.
35:07 And it doesn't even sort of, if your developers click to reveal the secret,
35:11 you know, it's just like, no, here's your Python code for our company.
35:16 So just kind of a cool little thing for that.
35:20 Let's see.
35:21 Brian Skin pointed out that the Stack Overflow 2022 developer survey is open for accepting
35:30 comments.
35:31 comments, which is cool.
35:32 And I'm going to put this up here on the screen first.
35:35 So Brian, do you see this?
35:36 It has all of this stuff.
35:37 I can't, if I click it, it'll just go away and like, this is an image, right?
35:40 Right here.
35:40 Yeah.
35:40 Yeah.
35:41 What if I wanted that as text?
35:43 What if I wanted to somehow grab that?
35:46 So I've got this app, which I'm going to tell you all about next, called Text
35:52 Sniper.
35:52 Watch this.
35:53 So you can't quite see if I just drag over that, just like you would a screenshot.
35:57 And then let's see, I need somewhere I can paste this anywhere there.
36:03 So what I got out of that is check this out.
36:05 Oh, wow.
36:06 Isn't that cool?
36:07 Yeah.
36:07 I just control seed from like the picture on my, on my screen.
36:14 and it can do PDFs.
36:15 It can do screenshots.
36:17 Like, so for example, if you're watching a video presentation and you see a
36:21 slide, you're like, oh, I want to capture those bullet points or that grab it.
36:24 You got it.
36:25 So that is called Text Sniper, which is super neat.
36:29 All it does, it's just like the select region for screenshot.
36:34 That's great.
36:34 And then boom, what it doesn't matter what's under it.
36:37 It's just, if it's texted, OCR is it, and then you got it.
36:39 Yeah.
36:40 So often like a small restaurant will put their address or their phone number
36:44 like in an image.
36:48 Like, come on, I gotta click on that sucker.
36:50 I want to put, just drop this, paste it into maps or something.
36:54 That's right.
36:54 So I don't know.
36:56 I think for doing research, if you're like watching videos, you want to get
36:58 something out of something that's on the screen, like a slide or whatever.
37:01 This is, this is pretty awesome.
37:02 And it, it costs something like $11 once.
37:05 So it's, you know, if it's useful to you, it'll be worth it.
37:08 If not, then, you know, it's not, it's gotta be worth $11 or zero to you.
37:12 That was like a good OCR app.
37:15 Yeah.
37:16 Yeah.
37:16 And it's just the ease of use, right?
37:18 Not take a screenshot and go find your app.
37:20 It's just like slap, slap drop.
37:22 Okay.
37:24 so last one of my extras, Sam Lowe and Philip Guo sent over, allow Sam Lowe,
37:31 sorry.
37:31 And then sent over that.
37:33 I had them on to talk about pandas tutor and they were talking about the
37:37 challenges of running pandas tutor on the server side and letting people run
37:42 code, but it's pretty limited because you don't want them to hack the various
37:46 things.
37:46 You don't want to keep it pretty limited.
37:47 So they don't take advantage of like your compute resources.
37:50 So now they just posted a message saying pandas tutor.
37:54 If you go over here and say, visualize your code, it'll go and do all these cool
37:59 visualizations.
37:59 I know we've spoken about this before, but notice what it says here.
38:03 I can scroll a little.
38:04 It says initializing high iodide on WASM download pandas running boom.
38:11 And so all of this is running in client side Python, which is just, yeah.
38:17 So we talked about that being one of the topics of the language summit, the WASM
38:21 support.
38:22 And here you have it in action.
38:23 So I said on the show, like, hey, if you guys consider this, like, yeah,
38:26 maybe we should.
38:27 And then like, this turns out to be a great idea.
38:29 That's pretty cool.
38:32 Like the messages run code on the server.
38:34 That's slower.
38:34 We just recommend you run it here.
38:36 Nice.
38:38 All right.
38:39 That's pretty neat.
38:39 Well done, you guys.
38:41 And that's it for my extras as well.
38:43 That's a lot more real than I thought.
38:45 I guess I thought pyro died and Web assembly were a little bit further off,
38:47 but that's like, hey, there's an application right now doing that today.
38:50 Yeah.
38:51 Yeah.
38:52 The Brian, the anti-gravity high script thing you showed last week was so cool.
38:57 Yeah.
38:58 I didn't even know it was doing that before we showed it, but it's pretty neat.
39:02 Yeah.
39:02 Yeah.
39:02 Yeah.
39:02 a lot of the interactions are super.
39:05 They're getting starting to be real hour.
39:07 We're getting there, Daniel.
39:07 We're getting there.
39:08 All right.
39:10 How about a joke to wrap it up?
39:12 Definitely.
39:13 So we've all been in, well, maybe we haven't all been, we can all imagine being
39:19 in awkward situations, maybe on a weird date.
39:22 So I don't go on dates really being married for a long time, but imagine,
39:26 imagine that you had, here's a graphic of a woman who's on a date, like maybe
39:33 just woke up in the morning after the first day, first time together sort
39:38 of thing.
39:38 And the guy who's like sculpted, right?
39:41 He's like clearly like a super fake, probably good looking guy, whatever.
39:45 But he's in the shower and she's like flipping through his phone and says,
39:49 when she looks through your phone, but all she can find is fork a child and kill it.
39:54 Google search for a kill child and fork parent, kill parent with fork, kill parent
39:59 without killing child.
40:00 kill child without killing grandchild.
40:04 And she's got this face of like, oh, what's that?
40:07 Sorry.
40:07 Those are great.
40:09 Yeah, she's got this look like I thought it was going so well and he's a murderer.
40:13 I can't believe it.
40:14 No, he's just trying to figure out Linux.
40:17 Don't, don't hold it again.
40:18 Kill child without killing grandchild.
40:24 It's so bad.
40:24 Can you do that?
40:27 Well, I don't know.
40:30 I haven't searched it, but I don't want to have to explain that search if I
40:33 did.
40:33 Search it in stealth.
40:35 That's what incognito most.
40:37 This is totally benign, but if somebody sees it out of context, maybe they
40:43 won't feel that way about it.
40:44 There's what will get you on the FBI list and then software engineers.
40:50 There's like Vendrygram of that.
40:53 there's probably a small intersection there.
40:54 It's probably pretty big actually.
40:57 Yeah, it's probably pretty big.
40:59 Anyway, well, thanks everybody for a fun show again.
41:03 Yeah, you bet.
41:05 Thanks, Brian and Daniel.
41:06 It's good to have you here.
41:07 Thanks.
41:08 Thanks for coming.
41:09 Bye.





