#277: It's a Python package showdown!
Watch the live stream:
About the show
Sponsored by: Microsoft for Startups Founders Hub.
Special guest: Thomas Gaigher, creator/maintainer pypyr taskrunner
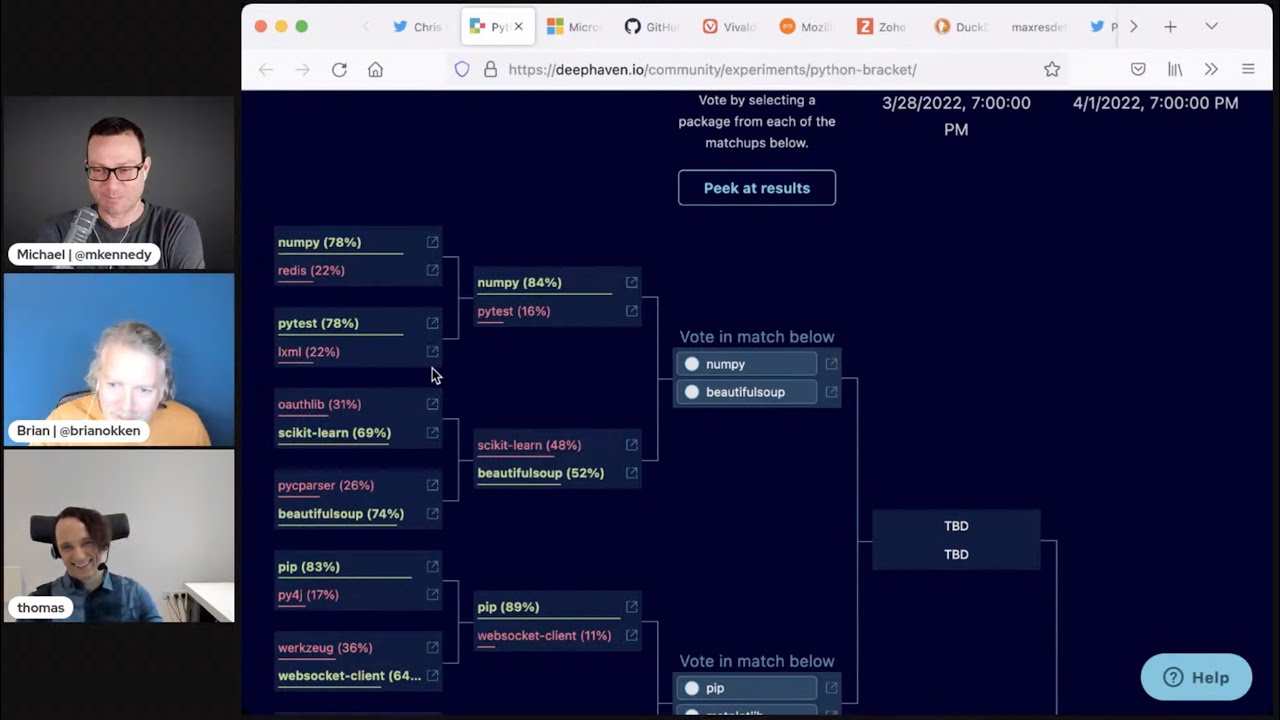
Michael #1: March Package Madness
- via Chris May
- Start with 16 packages
- They battle it out 2-on-2 in elimination rounds
- Voting is once a week
- So go vote!
Brian #2: nbpreview
- “A terminal viewer for Jupyter notebooks. It’s like cat for ipynb files.”
- Some cool features
- pretty colors by default
- piping strips formatting, so you can pass it to grep or other post processing
- automatic paging
- syntax highlighting
- line numbers and wrapping work nicely
- markdown rendering
- images converted to block, character, or dots (braille)
- dataframe rendering
- clickable links
- pretty colors by default
Thomas #3: pyfakefs
- A fake file system!
- It intercepts all calls that involve the filesystem in Python - e.g
open(),shutil, orpathlib.Path. - This is completely transparent - your functional code does not know or need to know that under the hood it's been disconnected from the actual filesystem.
- The nice thing about this is that you don't have to go patching
openusingmock_open- which works fine, but gets annoying quickly for more complex test scenarios.- E.g Doing a mkdir -p before a file write to ensure parent dirs exist.
- What it looks like without a fake filesystem:
in_bytes = b"""[table]
foo = "bar" # String
"""
# read
with patch('pypyr.toml.open',
mock_open(read_data=in_bytes)) as mocked_open:
payload = toml.read_file('arb/path.in')
# write
with io.BytesIO() as out_bytes:
with patch('pypyr.toml.open', mock_open()) as mock_output:
mock_output.return_value.write.side_effect = out_bytes.write
toml.write_file('arb/out.toml', payload)
out_str = out_bytes.getvalue().decode()
mock_output.assert_called_once_with('arb/out.toml', 'wb')
assert out_str == """[table]
foo = "bar"
"""
- If you've ever tried to patch/mock out
pathlib, you'll know the pain! - Also, no more annoying test clean-up routines or
tempfile- as soon as the fake filesystem goes out of scope, it's gone, no clean-up required. - Not a flash in the pan - long history: originally developed by Mike Bland at Google back in 2006. Open sourced in 2011 on Google Code. Moved to Github and nowadays maintained by John McGehee.
- This has been especially useful for pypyr, because as a task-runner or automation tool pypyr deals with wrangling config files on disk a LOT (reading, generating, editing, token replacing, globs, different encodings), so this makes testing so much easier.
- Especially to keep on hitting the 100% test coverage bar!
- Works great with pytest with the provided
fsfixture.- Just add the
fsfixture to a test, and all code under test will use the fake filesystem.
- Just add the
- Dynamically switch between Linux, MacOs & Windows filesystems.
- Set up paths/files in your fake filesystem as part of test setup with some neat helper functions.
- Very responsive maintainers - I had a PR merged in less than half a day. Shoutout to mrbean-bremen.
- Docs here: http://jmcgeheeiv.github.io/pyfakefs/release/
- Github here: https://github.com/jmcgeheeiv/pyfakefs
- Real world example:
@patch('pypyr.config.config.default_encoding', new='utf-16')
def test_json_pass_with_encoding(fs):
"""Relative path to json should succeed with encoding."""
# arrange
in_path = './tests/testfiles/test.json'
fs.create_file(in_path, contents="""{
"key1": "value1",
"key2": "value2",
"key3": "value3"
}
""", encoding='utf-16')
# act
context = pypyr.parser.jsonfile.get_parsed_context([in_path])
# assert
assert context == {
"key1": "value1",
"key2": "value2",
"key3": "value3"
}
def test_json_parse_not_mapping_at_root(fs):
"""Not mapping at root level raises."""
# arrange
in_path = './tests/testfiles/singleliteral.json'
fs.create_file(in_path, contents='123')
# act
with pytest.raises(TypeError) as err_info:
pypyr.parser.jsonfile.get_parsed_context([in_path])
# assert
assert str(err_info.value) == (
"json input should describe an object at the top "
"level. You should have something like\n"
"{\n\"key1\":\"value1\",\n\"key2\":\"value2\"\n}\n"
"at the json top-level, not an [array] or literal.")
Michael #4: strenum
- A Python Enum that inherits from str.
- To complement enum.IntEnum in the standard library. Supports python 3.6+.
- Example usage:
class HttpMethod(StrEnum):
GET = auto()
POST = auto()
PUT = auto()
DELETE = auto()
assert HttpMethod.GET == "GET"
Use wherever you can use strings, basically:
## You can use StrEnum values just like strings:
import urllib.request
req = urllib.request.Request('https://www.python.org/', method=HttpMethod.HEAD)
with urllib.request.urlopen(req) as response:
html = response.read()
Can auto-translate casing with LowercaseStrEnum and UppercaseStrEnum.
Brian #5: Code Review Guidelines for Data Science Teams
- Tim Hopper
- Great guidelines for any team
- What is code review for?
- correctness, familiarity, design feedback, mutual learning, regression protection
- NOT opportunities for
- reviewer to impose their idiosyncrasies
- dev to push correctness responsibility to reviewers
- demands for perfection
- Opening a PR
- informative commit messages
- consider change in context of project
- keep them short
- write a description that helps reviewer
- include tests with new code
- Reviewing
- Wait for CI before starting
- I would also add “wait at least 10 min or so, requester might be adding comments”
- Stay positive, constructive, helpful
- Clarify when a comment is minor or not essential for merging, preface with “nit:” for example
- If a PR is too large, ask for it to be broken into smaller ones
- What to look for
- does it look like it works
- is new code in the right place
- unnecessary complexity
- tests
- Wait for CI before starting
Thomas #6: Shell Power is so over. Leave the turtles in the late 80ies.
- Partly inspired by/continuation of last week’s episode’s mention of running subprocesses from Python.
- Article by Itamar Turner-Trauring
- Please Stop Writing Shell Scripts https://pythonspeed.com/articles/shell-scripts/
- Aims mostly at bash, but I'll happily include bourne, zsh etc. under the same dictum
- If nothing else, solid listing of common pitfalls/gotchas with bash and their remedies, which is educational enough in and of itself already.
- TLDR; Error handling in shell is hard, but also surprising if you're not particularly steeped in the ways of the shell.
- Error resumes next, unset vars don't raise errors, piping & sub shells errs thrown away
- If you really-eally HAVE to shell, you prob want this boilerplate on top (aka unofficial bash strict mode:
#!/bin/bash
set -euo pipefail
IFS=$'\n\t'
- This will,
- -e: fail immediately on error
- -u: fail on Unset vars
- -o pipefail: raise immediately when piping
- IFS: set Internal Field Separator to
newline | tab, rather thanspace | newline | tab.- Prevents surprises when iterating over strings with spaces in them
- Itamar lists common counter-arguments from shell script die-hards:
- It's always there!
- But so is the runtime of whatever you're actually coding in, and in the case of a build CI server. . .almost by definition.
- Git gud! (I'm paraphrasing)
- Shell-check (linting for bash, basically)
- It's always there!
- The article is short & sweet - mercifully so in these days of padded content.
- The rest is going to be me musing out loud, so don't blame the OG author. So expanding on this, I think there're a couple of things going on here:
- If anything, the author is going a bit soft on your average shell script. If you’re just calling a couple of commands in a row, okay, fine. But the moment you start worrying about retrying on failure, parsing some values into or out of some json, conditional branching - which, if you are writing any sort of automation script that interacts with other systems, you WILL be doing - shell scripts are an unproductive malarial nightmare.
- Much the same point applies to Makefile. It’s an amazing tool, but it’s also misused for things it was never really meant to do. You end up with Makefiles that call shell scripts that call Makefiles. . .
- Given that coding involves automating stuff, amazingly often the actual automation of the development process itself is deprioritized & unbudgeted.
- Sort of like the shoemaker's kid not having shoes.
- Partly because when management has to choose between shiny new features and automation, shiny new features win every time.
- Partly because techies will just "quickly" do a thing in shell to solve the immediate problem… Which then becomes part of the firmament like a dead dinosaur that fossilises and more and more inscrutable layers accrete on top of the original "simple" script.
- Partly because coders would rather get on with clever but marginal micro-optimisations and arguing over important stuff like spaces vs tabs, rather than do the drudge work of automating the development/deployment workflow.
- There's the glimmering of a point in there somewhere: when you have to choose between shiny new features & more backoffice automation, shiny new features probably win.
- Your competitiveness in the marketplace might well depend on this.
- BUT, we shouldn’t allow the false idea that shell scripts are "quicker" or "lighter touch" to sneak in there alongside the brutal commercial reality of trade-offs on available budget & time.
- If you have to automate quickly, it's more sensible to use a task-runner or just your actual programming language. If you're in python already, you're in luck, python's GREAT for this.
- Don’t confuse excellent cli programs like
git,curl,awscli,sedorawkwith a shell script. These are executables, you don’t need the shell to invoke these. - Aside from these empirical factors, a couple of psychological factors also.
- Dealing with hairy shell scripts is almost a Technocratic rite of passage - coupled with imposter syndrome, it's easy to be intimidated by the Shell Bros who're steeped in the arcana of bash.
- It's the tech equivalent of "back in my day, we didn't even have <<>>", as if this is a justification for things being more difficult than they need to be ever thereafter.
- This isn't Elden Ring, the extra difficulty doesn't make it more fun. You're trying to get business critical work done, reliably & quickly, so you can get on with those new shiny features that actually pay the bills.
Extras
Michael:
- A changing of the guard
- Firefox → Vivaldi
- (here’s a little more info on the state of Firefox/Mozilla financially)
- (threat team is particularly troubling)
- Google email/drive/etc → Zoho
- @gmail.com to @customdomain.com
- Google search → DuckDuckGo
- BTW Calendar apps/integrations and email clients are trouble
- Firefox → Vivaldi
Joke: A missed opportunity - and cybersecurity
Episode Transcript
Collapse transcript
00:00 Hello and welcome to Python Bytes, where we deliver Python news and headlines directly to your earbuds.
00:04 This is episode 277, recorded March 28th, 2022.
00:10 And I am Brian Okken.
00:11 I am Michael Kennedy.
00:13 And I'm Thomas Geiger.
00:14 Welcome, Thomas. Welcome to the show. Thanks for coming on and being a guest.
00:19 Can you tell us a little bit about you?
00:21 Thanks, Brian. And thanks, Michael. Big fan, so it's an honor being here.
00:26 I'm the creator and maintainer of the PyPro Task Runner, which it so happens you discussed last week.
00:31 So I come in riding on AtWave.
00:34 Yeah.
00:36 Yeah, very cool projects. Congrats on it.
00:39 Thank you very much.
00:39 Well, so, Michael, it's March.
00:42 It is March. It's like March Madness, right?
00:46 Yeah.
00:46 So Chris May sent in this thing that says, hey, Python Bytes people, here's a fun thing to cover.
00:52 For March Madness, but for Python.
00:54 And for those of you who are not college basketball fans and follow it carefully, March Madness is basically the playoffs for the college basketball.
01:05 And it's single elimination.
01:07 You start with 16, I think.
01:09 And then every team plays another one.
01:11 Then it's down to eight, then down to four, and so on.
01:13 So that's the idea, but for Python.
01:15 Oh.
01:16 And check it here.
01:17 We have round one.
01:18 I guess it starts with 32 and then 16 and so on.
01:21 So we've got these different rounds.
01:23 And some of the rounds have already occurred, but the winner, the champion, is still yet to be crowned.
01:28 So you all need to get out there and vote.
01:31 I'll tell you how in a second.
01:32 A bit amazed NumPy is outdoing pytest there.
01:37 It's outdoing it pretty handily.
01:39 I mean, it did outdo it, right?
01:40 So if you go here, what you see is this tournament bracket.
01:43 And the first ones were like NumPy versus Redis.
01:46 And NumPy won.
01:48 And then pytest versus LXML, Parser.
01:52 And pytest won that one handily.
01:54 And then NumPy and pytest had to face off.
01:58 And as Thomas said, surprisingly, NumPy pretty badly beat up on pytest.
02:04 Brian, are you okay with this?
02:06 How are you feeling?
02:06 I didn't get to vote, so I'm not sure how this was done.
02:10 Yeah.
02:10 This is going to be the start of a long blood feud between the NumPy community and pytest.
02:16 Well, and the other part of this story I'm telling, the other side of the bracket was Psykit-learn versus Beautiful Soup.
02:23 And Beautiful Soup, oh my gosh, I think it was a buzzer beater.
02:26 It came in at the last second, and it's like 52% to 48%, Beautiful Soup won.
02:31 And so now this week, we're in the Elite Eight.
02:35 And so you can come and vote.
02:37 I'm going to vote.
02:38 Like my metric here is sort of how useful and how impactful is this thing?
02:43 Not necessarily do I like it better.
02:44 So I'm going to vote over here.
02:46 I'm going to say for NumPy versus Beautiful Soup, NumPy.
02:48 I actually would use Beautiful Soup probably more, but I think NumPy is more impactful.
02:53 pip versus Matplotlib, I'll pip all day long.
02:56 Same reason.
02:57 Pandas versus Docker.
02:58 Ooh.
02:59 Ooh, I do like me some Docker.
03:01 I'm going with Pandas.
03:02 And then Wheel versus Request.
03:04 I'm going to go with Request.
03:05 I know Wheel is important under the covers, but I don't see it, so I don't want to think about it.
03:09 So Request, top of mind.
03:10 I use that all the time.
03:11 So here you can see I voted, and everyone else who would like to can just click the link in the show notes, and you can vote too.
03:17 And these are basically open for a week, and then the elimination happens, and it moves on.
03:22 So we're going to see what happens in the final four.
03:24 Coming real soon, actually.
03:26 Okay, we're going to have to highlight this earlier in the month next year so that people can vote.
03:34 You want to create some voting blocks like in the reality TV shows.
03:37 The one on the island?
03:39 Survivor?
03:41 Yeah, Survivor, exactly.
03:42 Oh, you know, I'm sad to say scikit-learn's torch has been extinguished.
03:47 Oh, no.
03:48 You're going to have to leave the island.
03:49 Yes, that's right.
03:50 Anyway, thank you, Chris, for sending this in.
03:53 This is fun, and it's very low stakes.
03:57 It's just sort of, you know, people just enjoy this for what it is.
04:00 Yeah, bragging rights and whatnot.
04:01 So we'll send out a tweet or something about it.
04:06 You can get in there and check this out.
04:07 Definitely.
04:08 Yeah.
04:10 How about you, Brian?
04:10 What's your next one?
04:11 I'd like to talk about NB Preview, which actually I thought we covered, but I couldn't find it anywhere.
04:16 So NB Preview is a notebook previewer, so IPython or Jupyter notebook.
04:22 And it's kind of neat.
04:26 It's a command line thing, and I like to spend a lot of time on the command line.
04:30 So you just, once you pip install it, or since it's not really part of your project, I used pipx.
04:38 pipx installed this.
04:40 Oh, yeah.
04:40 But it's so you say NB Preview, and then you can give it some options, but then a notebook file name, and it will, it just previews your notebook in ASCII, which is awesome.
04:57 But it's not just ASCII.
04:59 It's rich.
05:00 So we've got colors and nice colors and tables and stuff.
05:04 There's actually quite a few features that I want to run down.
05:07 One of the things I loved right away was it's not just a file.
05:13 I tried it out on some local files, but you can give it like a URL or something.
05:19 There's a great way to, you can get a whole bunch of stuff.
05:22 You don't have to have local notebook files to put it in.
05:25 Oh, that's cool.
05:26 Yeah.
05:27 So I'm going to see.
05:27 Yeah.
05:27 Yeah.
05:27 So I'm going to see.
05:28 Yeah.
05:28 Here it's showing even you can curl something and pipe it to it.
05:32 So it'll take inputs as pipes.
05:34 And the fact that it's a command line tool and it deals with pipes correctly is what
05:39 I really like about it.
05:40 So you can pipe a notebook to it.
05:42 I don't know if you do that or not, but you might want to pipe output.
05:45 So by default, you get these nice colors, but if you pipe it to an output, you can pipe it
05:51 to grep or something and you can grep for things.
05:54 So this is kind of great.
05:56 I don't know if you've ever tried to grep for something in a notebook, but there's a lot
06:01 of junk around it.
06:02 There's a lot of formatting stuff that, and if that's not really what you're looking for,
06:05 it's not helpful.
06:06 So be having this tool to strip that out.
06:08 It's pretty nice.
06:09 Oh yeah.
06:10 That's really nice.
06:11 I love the ability to just pull this up and view them.
06:13 And given that it's based on rich, like it has formatting for all the cells.
06:18 I mean, Jupyter is like markdown plus code and rich as rich highlighting for both of those.
06:24 So that's cool.
06:25 Yeah.
06:25 It looks like it's got some pigments under the hood also, which happens.
06:29 Ian brought up last week, I think.
06:31 Yeah.
06:31 Yeah, exactly.
06:32 So a lot of continuations said this week.
06:34 So a lot of cool stuff that you would expect, like code highlighting and stuff.
06:37 But the thing that like really stood out to me is what does it do with images like graphs
06:43 and stuff?
06:44 And the images are kind of amazing.
06:46 They're like these, by default, these block things, which not that clear to use for utilities,
06:55 but it kind of shows you what it's going to do.
06:58 And there's a few options.
07:00 You can do this block level thing.
07:04 And I like the characters.
07:06 So it does like the ASCII art stuff of your images.
07:10 Or it uses the Braille stuff.
07:14 I don't know if there's an example here, but you can do Braille for all the dots to show up,
07:19 which is kind of neat.
07:21 It even does like cool data frame rendering.
07:23 So if you've got a data frame printed out there in your notebook, it'll format it nicely.
07:31 So even LaTeX is formatted, which is kind of a surprise.
07:36 I didn't expect that.
07:37 So that's kind of neat.
07:38 Anyway, specifically, oh, cool, hyperlinks too.
07:44 So you can click on HTML that's in there.
07:46 That's kind of neat.
07:47 The thing that I really like that is the simple part, though, is to be able to strip stuff
07:52 and pipe it to grip and things like that.
07:54 So this is handy.
07:55 Nice.
07:57 Thomas, what do you think?
07:58 Oh, this is great.
08:00 I don't really use notebooks all that much, to be honest with you.
08:03 So it's a little bit lost on me.
08:04 But more command line is absolutely good.
08:07 And it looks delicious.
08:10 Yeah, it does.
08:12 It's the terminal, the TUIs, the terminal user interfaces are definitely coming on strong
08:17 these days.
08:18 We forgot to ask you, what kind of Python do you do?
08:20 What's your flavor of Python?
08:22 Are you building APIs?
08:23 Are you doing data science?
08:25 What kind?
08:26 Well, the Piper project is what consumes most of my hours.
08:30 So I guess that's normal-ish Python as opposed to notebook-ish Python.
08:34 Data science, I don't really do too much either.
08:39 So it's mostly traditional style Python programming.
08:44 Yeah, got it.
08:45 All right.
08:45 Well, your topic is up next.
08:47 Tell us about it.
08:47 Well, funnily enough, this is very traditional programming.
08:50 What I bring for you for your delectation is PyFakeFS, which I think is a sadly relatively
09:00 unknown open source library.
09:02 And I'd like to give them some props and recognition because I think it's amazing.
09:06 And it's made a huge difference to me and my own code and the Piper project.
09:09 So hopefully this helps out some other people.
09:12 Now, what it is, is a fake file system.
09:16 So in a nutshell, it intercepts all calls from Python to the actual file system.
09:22 So if you think of the open function, the built-in open, that is, or shutil or pathlib, all of
09:29 those that might have real-world side effects in terms of the disk, the fake file system will
09:35 intercept these.
09:36 And this is completely transparent.
09:37 And which is to say that your functional code doesn't need to know about this.
09:42 So the patching happens without you needing to inject something or without you needing to go
09:48 and alter your actual code to take countenance of the system.
09:52 Now, what's great about this is the moment you start talking about testing a file system, you're
09:58 almost by definition in integration testing or functional testing terrain.
10:01 Like it's not a unit test anymore, which comes with its own disadvantages.
10:06 So if you do want a unit test, then let's consider a simplistic example, right?
10:12 If you want to, if your code under test writes an output file.
10:16 So first of all, you need to patch out that if you're in your unit testing framework with
10:20 something like mock open.
10:21 But secondly, you probably have a pathlib in there somewhere where you're either creating
10:27 the parent directories for the path to check that they exist before you try and write to
10:31 that location.
10:32 So now we already have two things we have to patch out.
10:35 And then on top of that, you might be doing it in a loop.
10:38 You might be writing more than one file and the testing becomes very clumsy very quickly.
10:43 Whereas once you use the PyFaEFS library, you can just write as normal, validate against
10:51 that file system using the standard Python inputs.
10:53 And what you end up with is, and once the test finishes, it all just goes out of scope and
10:59 you don't even need to bother cleaning it up.
11:00 What's...
11:01 Yeah, that's cool.
11:02 And you could specify the string that is the content to the file.
11:05 So when the thing reads it, you can control the...
11:07 Absolutely.
11:08 What it sees, right?
11:08 So it comes with a...
11:10 And Brian, you're going to love this.
11:11 It comes with a super handy pytest fixture.
11:14 So if you are using pytest, which you should, you can just add the FS fixture to your unit test.
11:21 And now everything in your unit test will be going to the fake file system rather than the
11:27 real underlying fake file system.
11:29 That's pretty cool.
11:31 Yeah.
11:31 And the helper functions allows you, like you were hinting at, Mike, you can specify encodings,
11:37 you can write in binary.
11:38 It's super useful.
11:40 Something else that I use quite a lot is the ability to switch between Linux, Mac, and
11:45 Windows file systems, which again, for Piper is such a boon to be able to test the cross-platform
11:51 compatibility.
11:52 Oh, interesting.
11:52 So if it asks for like the representation from a pathlib thing, it'll do SQL and backslash
11:58 instead of forward slash.
11:59 Yeah, exactly right.
12:00 So all of these things are, you know, I'm relatively conservative when it comes to pulling in new
12:07 libraries because I'm, especially if the library feels heavy and I feel I can do it just using
12:13 standard lib functionality.
12:14 And also with some libraries, I'm a little bit worried that they might stop being maintained
12:19 or something like that.
12:20 But PyFakeFS has been around since 2006, developed by Google.
12:25 It was open sourced in 2011.
12:29 The maintainers are really on it.
12:30 I submitted and had a PR merged earlier this year within an afternoon on a Saturday, which
12:37 for open source is very quick.
12:40 So they're on top of it.
12:42 Great project.
12:43 Check it out on GitHub.
12:44 Check it.
12:44 Check out the documentation too.
12:46 It's well documented and it's super useful.
12:49 And I was looking at the Toxinny.
12:51 It looks like it's tested to be compatible with PyPy also, which is kind of nice.
12:55 Yeah.
12:56 Yeah, absolutely.
12:58 Especially for what I'm doing in Piper, where wrangling configuration files is a lot of the
13:03 functionality as a task runner.
13:05 You're forever reading JSON, writing out YAML, converting between formats, converting between
13:10 encodings, swapping out values inside configuration files, merging configuration files.
13:17 And I'm now able to test all of this stuff without having to write integration tests for each and every permutation, which has been such a boon.
13:25 This actually does way more than I thought it did.
13:28 I'm going to check this out.
13:30 This is neat.
13:30 Yeah.
13:31 There's a lot of cool stuff there.
13:32 Absolutely.
13:33 Chris and Alvaro both think pretty neat out there.
13:39 They're digging it.
13:40 Yeah.
13:40 And I see the comment there.
13:42 It is like temp path with the difference that it's not actually writing to the desk itself, of course.
13:48 And what's also a little bit difficult when you're using the temp directory and the temp file modules is depending on how you're testing, it doesn't always help you very much.
13:58 Because the thing that might be generating the file might be the code under test.
14:02 So you're effectively going to have to intercept that and create a temp file to attach to it.
14:07 And then the temp file will clean itself up.
14:09 But that starts interrupting the flow of the functional code so much that I start questioning whether it's even a useful unit test anymore.
14:17 Yeah, absolutely.
14:19 Well, very, very cool.
14:20 So, Brian, before we move on, let me tell you about our sponsor, all right?
14:24 All right.
14:25 This episode of Python Bytes is brought to you by Microsoft for Startups Founders Hub.
14:30 Starting a business is hard.
14:32 By some estimates, over 90% of startups will go out of business in just their first year.
14:37 With that in mind, Microsoft for Startups set out to understand what startups need to be successful and to create a digital platform to help them overcome those challenges.
14:46 Microsoft for Startups Founders Hub was born.
14:49 Founders Hub provides all founders at any stage with free resources to solve their startup challenges.
14:56 The platform provides technology benefits, access to expert guidance and skilled resources, mentorship and networking connections, and much more.
15:04 Unlike others in the industry, Microsoft for Startups Founders Hub doesn't require startups to be investor-backed or third-party validated to participate.
15:14 Founders Hub is truly open to all.
15:17 So what do you get if you join them?
15:18 You speed up your development with free access to GitHub and Microsoft Cloud computing resources and the ability to unlock more credits over time.
15:26 To help your startup innovate, Founders Hub is partnering with innovative companies like OpenAI, a global leader in AI research and development, to provide exclusive benefits and discounts.
15:36 Through Microsoft for Startups Founders Hub, becoming a founder is no longer about who you know.
15:41 You'll have access to their mentorship network, giving you a pool of hundreds of mentors across a range of disciplines and areas like idea validation, fundraising, management and coaching, sales and marketing, as well as specific technical stress points.
15:55 You'll be able to book a one-on-one meeting with the mentors, many of whom are former founders themselves.
16:00 Make your idea a reality today with the critical support you'll get from Founders Hub.
16:05 To join the program, just visit pythonbytes.fm/foundershub.
16:10 All one word.
16:10 No links in your show notes.
16:12 Thank you to Microsoft for supporting the show.
16:14 Awesome.
16:15 Thank you, Microsoft.
16:16 Now, let me tell you about something that sounds incredibly simple, but as you kind of unwind it, you're like, wait, it does that too?
16:24 Oh, it does that too?
16:25 Oh, that's kind of cool.
16:26 Pretty similar to the fake file system that Thomas was just telling us about.
16:30 This thing called sternum.
16:32 Sternum is a fantastic name.
16:35 It's short for string enum, right?
16:38 Enums.
16:39 When were enums added?
16:40 Was that three, four?
16:41 Something like that.
16:42 A little while ago.
16:43 So enums have been in Python for a while.
16:46 Pretty much prehistory now that those are no longer supported.
16:51 And with enums, you can write cool code that says this class, its fields are enumerations.
16:57 And then you can say, you know, enum type dot enum value.
17:01 And you can use that instead of magic words.
17:03 So, for example, you might have HTTP method or something like that.
17:08 Or let's say HTTP status.
17:10 Start with that one because that's like a built-in type thing you could do easily.
17:12 You could have a 200, a 201, a 400, a 500, a 404, those kinds of things.
17:20 So, you could have like HTTP statuses dot and then those types with those numbers, right?
17:24 But there's a couple of challenges to working with those.
17:27 Their natural representation is a number, not a string.
17:32 And I know you can derive from enum and then also derive from string.
17:37 But like I said, more stuff happening than just that.
17:39 So, this sternum allows you to create enums like that and use the enum auto, enum.auto field.
17:48 So, I can say, here's an HTTP method with like verbs is really probably what it should be.
17:52 So, you can have a get, you can have a head and a post and a put.
17:55 And you just say auto, auto, auto, auto.
17:56 But the actual representation is that the get is a string get.
18:02 And the like put one or post is, you know, put or post.
18:09 Yeah.
18:09 And Alvaro is out there pointing out, thank you, that sternum was temporarily part of 3.10, but that it was dropped.
18:15 So, there was.
18:16 I saw a note that it might be included in 3.11 again.
18:19 Okay.
18:19 That'd be fantastic.
18:20 It would be.
18:21 Yeah.
18:22 So, there's some really neat stuff in here.
18:23 For example, one of the things that's nice is because this thing basically has the value string, where you're using it, you can actually use it where a string would be accepted.
18:33 So, here if you're doing a request to a URL and you've got to say method equals, here you can say method equals HTTP method dot head or whatever from the enum and it directly passes just the string head to the method.
18:45 So, it's a really nice way to like gather up string values that are like part of a group, right?
18:51 Like HTTP verbs or something like that.
18:53 Wow.
18:54 So, that's pretty neat.
18:55 Okay.
18:56 The side question is I don't really use auto much.
18:59 Is auto used anywhere else or is auto just an enum?
19:03 It comes out of the enum module.
19:04 Okay.
19:05 So, it's part of this.
19:06 So, it's part of the enum thing.
19:08 All right.
19:08 And one of the things I really like about this that is super tricky with enums is databases.
19:14 So, for example, imagine we had like get head and post.
19:20 So, we just had auto, but it was an integer based one.
19:22 So, it was like one, two, three.
19:23 And we store it in the database, right?
19:26 As a one or two or three and then you parse it back.
19:28 Fine.
19:28 But then somebody adds another auto thing in there and they don't put it at the end.
19:34 They're like, oh, this one starts with a D.
19:35 So, it goes after delete.
19:36 Yeah.
19:37 Well, all the stuff after that one is now off by one in the database, right?
19:42 Like, so this, if it goes into the database, it goes in as a string and it'll parse back
19:46 as the string.
19:47 It also has cool stuff like lowercase sternum and uppercase string enum.
19:53 So, you can derive from that instead.
19:55 And then no matter how you define your field, you get a lowercase string version or an uppercase
20:00 string version.
20:01 Okay.
20:02 And there's other cases as well.
20:04 There's pascal case, snake case, kebab case, macro case, and camel case.
20:10 Woo!
20:10 Go crazy on them, people.
20:12 And you can have the same code, but then like the string representation varies.
20:17 So, that's pretty awesome.
20:19 I think I'm going to go with kebab case just because that's fun to say.
20:22 It's so fun.
20:23 I know.
20:23 And then, yeah, you can also directly assign the value.
20:29 So, you know, enum value equals some string and then it like, right, you don't have to
20:34 worry about a casing.
20:34 It's exactly the string that you put.
20:36 Right?
20:37 So, there it is.
20:39 It's like regular enum, but strings.
20:41 And as people pointed out that it's not that different from what people have been considering
20:47 for CPython.
20:47 I'm pretty sure I'd heard about it as well in being in there, but the fact that it's not
20:52 there, maybe it'll be there, maybe not.
20:53 We'll see.
20:54 It's interesting.
20:54 But this has a lot of cool features.
20:56 And if you're not using 3.11 or want to depend upon it, you know, this is a small little
21:00 project.
21:01 Yeah.
21:02 It's nice.
21:02 Cool.
21:03 Yeah.
21:03 Thomas, what do you think?
21:04 This is great.
21:06 I especially like how it's smart enough to autocast so that when you use the enum, it will end
21:15 up translating to a string when you're actually hitting the database or your underlying API.
21:19 Yeah.
21:19 It makes it actually usable in those situations just directly.
21:22 Yeah.
21:23 Which I think is great.
21:24 And funnily enough, the example they chose is so great by way of great documentation because
21:28 HTTP verbs are just almost the example of magic strings, right?
21:33 Yeah, exactly.
21:35 Exactly.
21:36 Yeah.
21:36 Quite cool.
21:37 All right.
21:38 Ryan, over to you.
21:39 I'd like to review your code a little bit.
21:41 No.
21:43 I don't know.
21:44 I was trying to do a transition thing.
21:45 But so Tim Hopper wrote this article, which I absolutely love.
21:50 And it's called the Code Review Guidelines for Data Science Teams.
21:54 And I just recommend everybody go read it.
21:57 It's short.
21:59 It's good.
21:59 But one of the things I really like that he highlighted is before he got into the code review
22:07 or the code review guidelines, he started with, why are we doing a code review?
22:13 What is a code review for?
22:15 And this is something I think that is important just to talk with whoever, whatever team is
22:20 going on and talking, maybe even sticking it in a participation guideline in a project,
22:27 open source project even, is that it's not just so that we can look at the code or check
22:34 it to merge it.
22:35 So his reasons for a code review are first code correctness.
22:39 And that's what we think about is making sure the code's correct.
22:43 But also code familiarity.
22:45 Familiarity.
22:47 So you might be the expert on a project and everybody else is only kind of new on it.
22:52 You still should have code reviews for your code changes so that everybody else can watch also
22:58 and get familiar with the changes going on.
23:02 So that's nice.
23:03 Design feedback, of course.
23:05 mutual learning and regression protection are all the reasons why he did a code review.
23:10 And the other thing I also love is what to leave out of a code review.
23:17 So code reviews are not about trying to impose your guidelines on somebody else.
23:23 And they're also not a reason to push off responsibility.
23:29 So as long as your code's getting reviewed, it doesn't have to be correct, right?
23:32 Because somebody will catch any problems.
23:34 It's a bad thing to do in a code review.
23:36 So make sure your code's correct.
23:39 It's all cleaned up as soon as you, what you think is it's ready and then submit it, but
23:45 then also be nice.
23:46 So being nice is important.
23:49 Yeah.
23:50 Very cool.
23:50 So then it goes, he goes through, I'm not going to go through all these here, but he goes through
23:54 different things about what to think about before you do a, create a pull request and then what
24:02 to do if you're reviewing a pull request.
24:05 And a lot of these are just, they're just around being a kind human to the person on the other
24:10 end.
24:11 So that's really kind of what it's about.
24:13 So I saw a mention in the summer that I really liked, which is, I mean, by nature, a code review
24:19 is sort of nitpicky, right?
24:21 You're paying attention to flaws, but it's nice to compliment.
24:24 Also, like if there's something nifty or cool or cute, acknowledge compliment, call attention
24:29 to it.
24:29 Oh, that's a, that's a good point.
24:32 And I really liked that.
24:33 I also think, so one of the things that you don't want to do in a code review is like one
24:39 of the guidelines is, is we're not looking for perfection.
24:42 We're just, it's gotta, you know, that isn't one of the things we're looking for, but so what
24:49 happens if you notice something and you're like, it's a little weird.
24:52 It does it.
24:53 I'd like to say something about it, but I don't know how to say that.
24:56 His comment is to, to have, if you've got a minor thing that you want to comment on, go
25:01 ahead and sort of tag it.
25:03 He recommends tagging it with knit in it or a nitpick or something.
25:08 Just to be clear that I'm, I don't know if I like the word knit, but to be clear, Hey,
25:14 I noticed this.
25:15 Maybe we want to change this in the future.
25:17 Somehow indicate to the person that they don't need to fix this before the PR gets merged.
25:22 You're just noticed it.
25:24 So, and it might be something that the person that submitting the PR didn't realize in the
25:29 first place and went, Oh yeah, I don't like that either.
25:31 I'm going to fix it.
25:32 Or yes, I do know about that.
25:34 And I do plan on fixing it later or what, you know, whatever.
25:37 So just an interesting guideline.
25:40 And I think it can just, I'm kind of a, I've been on a kick lately of reading things about
25:46 community and, and creating cohesive teams and the review process is definitely some somewhere
25:52 to you need to have attention to for most teams.
25:56 So anyway, that's it.
25:58 Yeah.
25:58 I like it.
25:59 This is really handy.
26:00 I love the idea of having as much as possible, have the automation, make the complaints.
26:07 And like Thomas said, have the people give the compliments and the sort of interesting
26:11 discussion.
26:11 Right.
26:11 But like if black can just take care of the formatting, like you shouldn't have to debate
26:14 a formatting.
26:15 Yeah.
26:16 And if a linter can tell you, you know what, there's something wrong with this.
26:19 Just like, let the linter be the bad guy.
26:21 Yeah.
26:21 It was one of the guidelines that he brought up, which is interesting is especially with CI
26:25 and we're pushing a lot of things on black or, or linters that to wait.
26:32 So wait a little bit.
26:33 So don't, don't like review a code review right away.
26:37 Especially not if the CI hasn't finished, let the CI finish and let the person creating
26:43 it fix anything before you jump in.
26:46 I also, that peeve of mine, don't comment on it right away.
26:50 I might, one of the things I do frequently is I'll create a, a PR, especially for in a
26:57 work setting, I'll create a PR and then I, there's some complicated things.
27:01 So I plan on going through and writing some comments around some of the complicated bits.
27:07 Like why did I do certain things?
27:08 And, so if you see a PR right away, especially from me, wait 10 minutes or so before commenting
27:17 on it.
27:17 Cause I might, I might've answered your question before you get a chance to ask it.
27:21 An exclamation might be coming.
27:22 Yeah.
27:23 Indeed.
27:23 Anyway.
27:24 Awesome.
27:25 All right, Thomas.
27:26 How are you?
27:28 We're about to head into controversy because there's been, there's been some discord.
27:32 Are you going to bash on something?
27:34 Come on.
27:35 I'm going to bash it over the head with a, like a caveman.
27:39 Bash it with Python.
27:40 So partly inspired on the continuation of last week's discussion, you had about running sub
27:47 processes from Python.
27:48 And, Itamar Turner-Trowing wrote an article this week called, please, please emphasis mine.
27:56 Stop writing shell scripts.
27:58 Now this, as you might imagine, raised a bit of questions on the usual places like Reddit
28:05 and Twitter, but if nothing else, controversy aside, the article is a very good and succinct
28:12 summary of the most common gotchas and problems with bash, which we can almost all summarize
28:19 as that error handling is strange.
28:21 If you're used to other programming languages, like bash is a kingdom unto its own when it
28:27 comes to programming languages.
28:29 So he also gives a great recommendation for if you really, really have to write in bash,
28:35 what you might want to do.
28:37 And that would be to use the unofficial bash strict mode, which basically involves setting
28:45 that bit of boilerplate on top of your bash.
28:47 I'm not going to cover all the details, but basically the E and the U option will fail
28:52 immediately on error.
28:53 It will fail on unset variables.
28:55 And if you add the pipe file option, errors won't pass between pipes.
29:00 a pipe will actually fail immediately if there's an error process.
29:04 Awesome.
29:05 Like it should.
29:06 Like it should indeed.
29:08 But the point is there's batches on all technology and there's a lot of problems here.
29:14 And let me add, although this article mostly aims at bash, I am very happy, including born and SSH and fish and take your pick underneath the same dictum.
29:25 Now he goes on to talk about the typical reasons we hear of why we should be using bash of which the top one is, well, it's the most common.
29:37 And you're guaranteed to have an SSH runtime, at least on any given machine that you're going to be using.
29:43 But the point is not really because when we're doing code automation, almost by definition, the programming language or coding in its runtime is on the server.
29:55 So this argument that somehow it's good to go to the lowest common denominator, AKA SH or bash, when you already have Python on the machine is sort of, well, why?
30:05 And especially when we're talking about Python, which is so great at automation, it just baffles the mind.
30:12 That's a good point there.
30:13 You don't have to set up a compiler or any of that kind of business.
30:16 I say the same thing about Golang.
30:17 I mean, by definition, when you're compiling Go, the Go compiler is right there.
30:22 You might as well be writing a Go script or whichever your programming language is.
30:26 I mean, maybe if you're starting to talk about like C or C++, there's maybe a different argument that we can have there.
30:34 The second point he brings up is what I'm going to paraphrase as get good, which is this bash guru response, which we saw a bit off in the last week, that you're just bad at bash.
30:47 Like if you were better at bash, you wouldn't be complaining about these things, which is not a great reason.
30:54 It's just because it's not better because it's hard, right?
30:59 We have better tools available.
31:01 We have tools that behave more responsibly.
31:04 And something that I think is very important in line with what you've been talking about, Brian, about building teams is very often your automation activities start becoming this specialized zone that only two or three people on the team can even look at because they're the bash gurus.
31:20 And everyone else is too afraid to touch it.
31:22 Whereas if you keep your automation activities within the language you're coding in, suddenly everyone on the team can start carrying their weight, right?
31:30 Yeah, I kind of relate to this a lot.
31:33 I've been on projects where we've had a lot of our automation in bash and others that have been other languages.
31:41 Right now, it was one of those things, especially if you're not looking on a Windows environment, bash isn't there all automatically.
31:50 And a lot of the team members might not be familiar with it.
31:55 So the thing that I don't know if he addresses this, the thing that I was thinking about was we all know Python if we're programming Python.
32:04 But we might not all know the automation parts of it, the way to do like file manipulation or.
32:13 Right.
32:14 I say util and that kind of stuff.
32:17 Stuff that we might be familiar with with bash because we, if we're using it all the time on the command line, I already know how to do it.
32:24 But I might not know how to do that sort of stuff in Python because I'm not using Python like that.
32:31 But anyway, well, my response to that would be that whatever the thing is that you don't know how to do in Python, your chances of running into trouble with bash are, to my mind, a lot higher than they are with Python.
32:45 Or at least when things misbehave in Python, your control of flow is better so that you probably will have a, especially as the scripts start getting bigger, you will have better control over where the issues might be.
32:58 Or you would be better able to isolate those areas that you're not exactly sure of.
33:03 I saw someone in chat last week raise the specter of make files that call shell scripts that call make files.
33:10 And I mean, this is not uncommon.
33:13 I'm sure we've all seen these things.
33:15 And I'm actually very interested in the psychology around this because we're all coders, right?
33:21 I assume we're here because we enjoy automating things.
33:24 We enjoy solving problems.
33:26 We probably, you know, have a certain problem solving sort of mindset that got us into this to begin with.
33:33 Yet, it seems like we spend so much time automating our customers' business processes that we forget to automate our own coding processes.
33:40 Or when we do, we deallocate the priority.
33:43 We de-budget it.
33:45 We end up focusing on all sorts of other things other than this essential housekeeping.
33:49 Yeah.
33:50 Or treat it like a throwaway code instead of code that needs to be carefully factored.
33:55 Exactly right.
33:56 And I would argue it's a bit like housekeeping.
33:58 You know, no one likes doing it.
33:59 But if you don't want to live in a big star, you've got to do it.
34:02 You know, instead.
34:03 Yeah.
34:04 Well, also, to be honest, I was there once of like, I don't know how to do this automation stuff in Python.
34:10 But it bugged me that I didn't know how.
34:14 So I'm like, okay, well, what do I need to learn?
34:16 Like the few things like searching for stuff like I normally would have used Perl for Regex or something like that or said.
34:23 All that stuff you can do with Python.
34:25 And actually, there's tons of articles on it.
34:27 It's really not that hard to go, okay, the pieces I'm missing, how do I do that?
34:32 And just go learn it.
34:33 And then it's not that hard to switch a lot of automation to Python.
34:38 Yeah, definitely not.
34:39 And I mean, so much other automation happens in Python anyway.
34:43 I mean, in fact, kind of compiled programming languages will often use Python as an automation language.
34:48 It's so handy for the automation process.
34:52 There is another psychological thing, which I find, or I think psychological thing, that I find quite curious here, which is this dealing with complex shell scripts almost becomes this like technocratic rite of passage.
35:04 Where when you couple that with imposter syndrome, you know, it's very easy to be intimidated by the bash bros when they do these really clever one-liner bashisms that you can't make head or tail off.
35:15 And it's like, yeah, look how clever this is.
35:17 But it's very hard to maintain.
35:19 You don't, you know, and it's almost hard to call that to account unless you're very sure of yourself.
35:24 Because you almost have to justify yourself as to why you dislike it.
35:28 Like you first have to prove your bona fides.
35:31 I think it's sort of the tech equivalent of, you know, back in my day, like we didn't have X, you know, like whatever X is, shoes or toilet paper or like whatever.
35:43 Just because something used to be difficult doesn't mean it needs to be difficult forevermore, right?
35:48 Yeah.
35:48 Like the extra difficulty doesn't make it better.
35:51 It's not a video game like Elden Ring, you know, like the easier this is, the more quickly and effectively you can do the housekeeping, the more you can get up with the features that actually pay the bills.
36:02 Which is to say the shiny functional stuff that you can demo and put in front of customers.
36:07 Yeah, absolutely.
36:08 I have some real-time feedback and also a comment for you.
36:12 Alvaro says there's a VS Code plugin called Shellshock, if he's remembering it correctly.
36:17 Tells me when I'm doing something wrong or it might blow up.
36:20 There's also a plugin for PyCharm.
36:21 So if you're going to do it, you know, have those things for sure.
36:24 Yeah, funnily enough, we've got immediate feedback to that, which is the author of the original article mentions Shellshock, which is effectively, like the commentator mentioned, a linter for Bash.
36:35 But the article also mentions that it doesn't actually catch all things either.
36:40 So like all linterers, it can very easily lull you into a false sense of security, while it's not really necessarily addressing the underlying problems.
36:49 And I almost feel like I don't even need to say this because anyone who's ever tried to debug a long Bash script should know this.
36:57 They're tricky.
36:59 They fail in mysterious places, and it's very hard to figure out why and how.
37:04 Yeah, but I do like this article pointing out how, if you have to, to set up those flags to make it, you know, fail quicker.
37:12 Yeah.
37:13 Because that helps a lot.
37:14 So that's nice.
37:15 Yeah.
37:16 Yeah, for sure.
37:17 And also, just to give the author massive amounts of credit, this isn't clickbait.
37:21 He didn't position this as never, ever use Bash.
37:24 In fact, he explicitly says that, okay, if you're doing something super simplistic, like the typical sort of things that goes into a get hook, a pre-commit hook, where you're just running a command or two, then yeah, sure.
37:35 Of course, shell script's fine.
37:37 But I would say as soon as you're running loops, as soon as you're doing conditional branching, as soon as you're worried about retries, as soon as you're doing...
37:46 Oh, yeah, definitely.
37:47 Switch to Python.
37:48 Absolutely.
37:48 Yeah.
37:50 Yeah.
37:50 And then another quick question, just a quick follow-up.
37:53 Have you considered Conch?
37:55 I've not even heard of Conch.
37:57 I never mind considering it.
37:58 So it's, I haven't done much, but I've sort of looked at it.
38:02 It is a shell, like a competitor to Bash or ZShell or something like that, where it's a proper Python environment directly in the shell.
38:13 That's almost PowerShell-esque.
38:15 Yeah, it's a little bit like PowerShell, where PowerShell is like kind of .NET, C-sharp-like, kind of, but not really.
38:22 I suspect it's similar here, but...
38:24 And I know it's supposed to be pronounced Conch, but my brain says Zaunch, because it's funner to say.
38:30 Zaunch.
38:30 I know, but it has the shell.
38:32 It has the shell, so you know that's how you got to say it.
38:34 Yeah, they even have the Asgard going on for the logo.
38:37 That's interesting.
38:38 They do indeed.
38:39 They do indeed.
38:40 All right.
38:41 Well, cool, Thomas.
38:42 That was a good conversation.
38:43 That was good.
38:43 So do we have any extras?
38:46 Michael, do you have any extras?
38:48 You know I got extras, right?
38:50 I also, first, real quick follow-up, a real-time follow-up from Henry Scheiner in the audience,
38:55 that pep663 was the PEP around string enum.
38:59 Oh, okay.
39:00 And he's not sure if removing the support for that PEP means removing string enum from the standard lib or not, though.
39:05 Doesn't do all the other stuff like the casing and the various other things that that cool package I talked about does.
39:10 So maybe that package is, no matter what, relevant still or inspiration for the next one or whatever, right?
39:16 In terms of extras, I do have some extras.
39:19 Let me see what order I wanted to cover them in.
39:22 I had two, but then one got rescheduled.
39:25 This is supposed to be the transformation from bugs.python.org over to GitHub, but that got pushed back a week, so I'm not going to talk about that.
39:33 You just did.
39:34 Well, I was going to say it's happening.
39:38 It should have happened by the time you hear this.
39:39 Go check it out.
39:40 No, it's not true anymore.
39:41 No, okay.
39:42 Just if you're curious, supposedly it's moved to April 1st, but it's April Fool's Day, so I'm not sure if it's really going to happen or not.
39:50 Maybe it's a long con where the joke is being set up for in advance.
39:54 Yeah, exactly.
39:55 Oh, we're actually never doing this.
39:57 No.
39:57 I'm looking forward to that happening.
39:58 That's great.
39:59 All right.
39:59 I just have like a general theme of sort of stuff that's like thrown all together, kind of a changing of the guard, if you will.
40:06 Okay.
40:07 Let's see here.
40:08 So I have been switching so much of my software stuff around.
40:12 I've started using Vivaldi.
40:13 Now I've been using Firefox for a long time, but I started using Vivaldi, which I think is a really neat take on a browser.
40:19 So I switched over to Vivaldi and started using that.
40:22 You know, there's a bunch of different things.
40:24 Like Mozilla laid off 250 people recently.
40:28 They're axing the developer tools team too, which is just tragic.
40:31 Exactly.
40:31 Cut the developer tools team.
40:33 They cut the threat team, the team that looks for like a tactic.
40:38 It's like, I don't know.
40:41 It's starting to make me a little nervous.
40:42 So I'm trying out Vivaldi.
40:44 I've been doing that for like a month or so, and I'm enjoying that.
40:47 Mike, you said it's a different take on a browser or like, so it sounds like there's something conceptually different about it.
40:54 It's just super customizable.
40:56 I think that's the thing.
40:57 It's like, there's just all sorts of stuff.
40:59 It comes with a built-in ad blockers and tracker blockers.
41:01 I know some of them do tracker blockers, but built-in ad blockers.
41:04 Nice.
41:04 I mean, Brave is the other one that kind of does that.
41:06 But Brave is like, well, let's just trade those ads for our cryptocurrency ads that we'll put in there for you.
41:11 And you get a little bit of cryptocurrency.
41:12 This is like, no, we'll just block the ads.
41:15 So anyway, I switched over to that, partly motivated by just concern around this, but also just wanted to try some stuff out.
41:22 From Google Docs over to Zoho for other stuff and for like business email.
41:27 There's so interesting stuff going on there.
41:29 And then like also DuckDuckGo.
41:30 I've been using that for a while and I tried that a while ago.
41:33 It just, I didn't feel like you switched.
41:35 To me now, there's just like almost no difference in the quality compared to Google these days.
41:41 Where it used to be, I'd try and like, I might have to go to Google for that.
41:44 Like, you know, several times a day.
41:46 No, I don't really.
41:47 If I get stuck here, usually I try to go to Google and get it and I get still stuck.
41:51 So just got to deal with it.
41:53 So that's it for all my items.
41:55 I'm just down to telling a joke.
41:56 Thomas, you got anything extra you want to share throughout the area of the world?
42:00 Not particularly.
42:01 I'm looking forward to your joke.
42:02 Give a quick shout out to Piper real quick.
42:03 Oh yeah.
42:04 Check out last week's episode.
42:06 I know we covered it last week, but yeah.
42:07 Michael actually did as good an introduction to Piper as I could give.
42:11 So congratulations and well done.
42:13 Thank you.
42:14 If you do want to check it out, support open source software.
42:16 Do the usual share, like, subscribe, all the rest of it.
42:20 You can check it out on GitHub.
42:21 It is the Piper Task Corner, P-Y-P-Y-R.
42:25 And incidentally, if you don't want to run Bash scripts, then a Task Corner might be a good way of not doing so.
42:34 Yeah.
42:36 I was thinking about your project while you were talking about this.
42:39 I don't want to shill too horribly.
42:41 So I try to keep that to the end.
42:44 That's our job.
42:45 We only shill.
42:46 We basically just shill cool stuff all week.
42:49 That's our podcast.
42:50 Ryan, how about you?
42:51 Got anything extra you want to shout out there?
42:53 I've got some stuff, but there's nothing I can share right now.
42:55 So, yeah.
42:56 All right.
42:57 Well, we'll be waiting.
42:58 How about we share a joke then and wrap it up?
43:00 Sounds good.
43:00 So I feel like this is a missed opportunity because we had Ian on last week and he was all about
43:06 cybersecurity and using notebooks to track threats and stuff.
43:10 Well, has he considered this?
43:13 That was in a James Bond movie, right?
43:19 It's been several.
43:21 It could have been.
43:22 So here is like a big server rack with just, you know, like a hundred Ethernet cables.
43:27 And in a big printed sign on it says, in case of cyber attack, break glass, pull cables.
43:32 I'll also say what surprises me.
43:35 The Internet is going soft in its old age because back in my day, the first comments would have
43:42 been complaining that the cables aren't tidy enough.
43:44 Wow.
43:47 You got to get a good grip on it.
43:48 Yeah, exactly.
43:48 There's one zippy move with your arm and you give it a yank.
43:52 You need good cable management.
43:53 This is exactly why.
43:54 There's a lot of cables.
43:55 They should put like orange tags on the ones that are important to pull or something.
43:58 Yeah.
43:59 Exactly.
44:00 This is the sort of criticism that I would have expected.
44:02 Actually, the entire thing has a power switch just to power off the whole thing.
44:09 You don't want to lose data.
44:10 I mean, come on.
44:11 No, just kidding.
44:12 Also, where's the axe?
44:13 How do you break the glass?
44:15 Exactly.
44:16 Oh, or just open the door handle.
44:19 Very, not very thought through.
44:21 It reminds me a little bit of that.
44:23 In case fire, git commit, git push, run.
44:25 I mean, you know, also we're talking about IT people who generally probably aren't, you
44:31 know, that much into the pushing regime.
44:33 So, you know.
44:34 Or lifting axes.
44:36 You know, that might be a strain.
44:38 Sorry.
44:40 I'm going to get hate mail for that.
44:41 Oh, we are.
44:43 Yes, indeed.
44:44 Well, I thought it was fun, Brian.
44:47 So, well, thanks everybody for having a fun episode again.
44:52 Thank you, Thomas, for showing up.
44:54 Thanks, Michael.
44:54 And thank you, everybody in the chat for showing up.
44:57 So, we'll see you all next week.
44:58 Bye, everyone.




